这个问题想了一下,发现解释起来很复杂,需要理解"本地优先"最精髓的点。 两个概念确实相似——共同的敌人是百度腾讯阿里 Google Apple Meta ,它们提供了服务,也顺带垄断了用户的数据;两个概念也允诺同一种理想——自我控制、自给自足、简单稳定的数字生活。没有人希望被企业随意打扰侵入,都希望拥有主动权,享受数字世界的好处,又不被巨头玩弄注意力。
最简单区分两个概念的方式——数据在哪里?
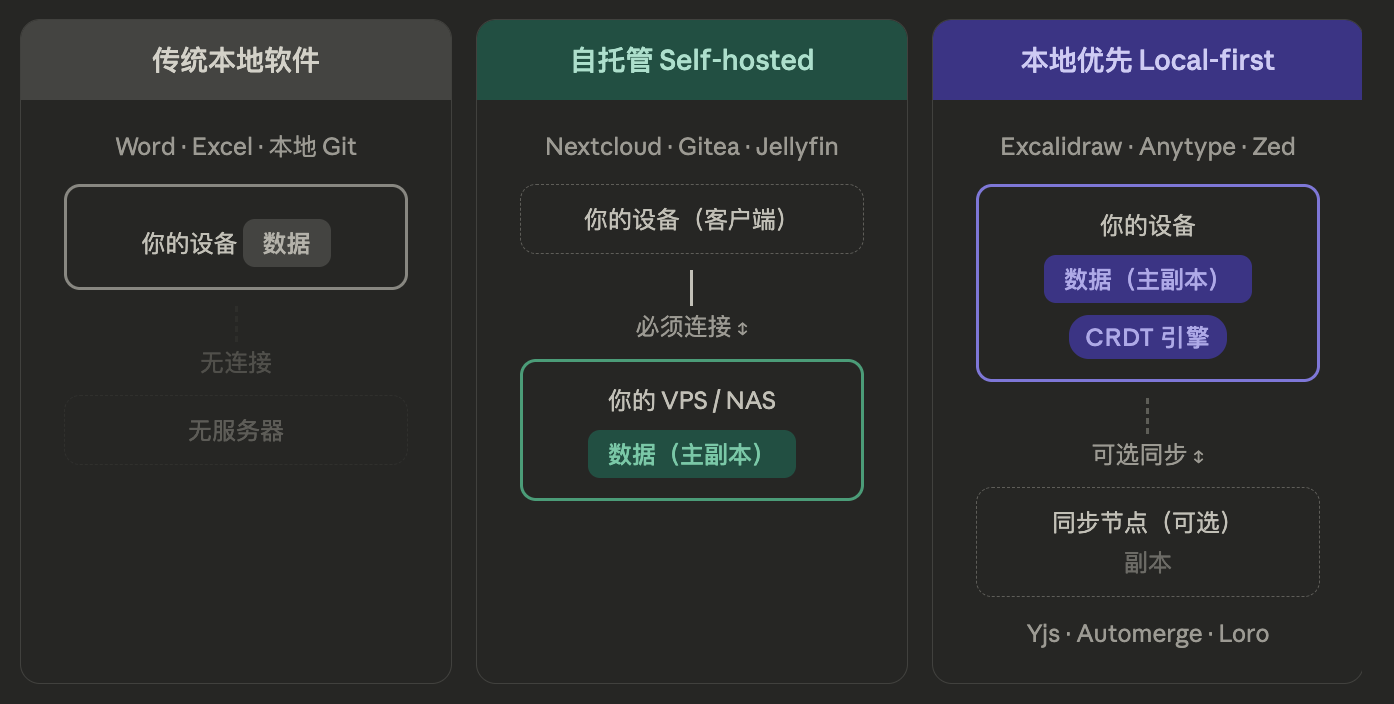
可以离网运行的软件,例如 Git 和 Obsidian ,它们在自己的计算机本地运行,这是一类。但本地优先与本地运行的软件并不相同。自托管(self-hosted)是 VPS 或 NAS 是自己的,上面跑一些应用,自己通过客户端来使用,数据本体在云上。本地优先是数据本体存在自己的手机或电脑上,云端最多用于同步和备份。自托管与本地优先也不相同。
"本地优先"是一个技术运动,它允诺了一种新的软件理想原型。本地优先应用是一种构建软件的方式,既支持实时协作(如 Google Docs ),也支持离线工作(如 Git )。其原理是将用户数据存储在本地设备上,并在后台与协作者同步。如何合并在不同设备上独立进行的编辑是核心挑战,CRDT (无冲突复制数据类型)正是为解决这个问题而开发的。
这个问题非常好玩,值得多写一些来解释清楚。下面会讲讲历史和它的理想。
历史
要理解本地优先想做什么,绕不开 Ink & Switch 这个实验室。
V2EX 上有人翻译过《本地优先软件》,已经很好了。更详细的信息,可以跟 AI 唠唠。
2019 年,实验室的合作者 Martin Kleppmann 等人发表了论文"Local-first software: You own your data, in spite of the cloud",正式提出了本地优先的概念。核心论点很简单:把云应用中"服务器数据为权威、客户端仅为缓存"的模型翻转过来——用户设备上的数据副本才是主副本,服务器只负责同步和备份。由此推导出一系列理想:无需等待、网络是可选的、无缝协作、数据长期留存、用户保有最终控制权。
Martin Kleppmann 是《数据密集型应用系统设计》(豆瓣评分 9.6 )的作者,现任剑桥大学副教授。Automerge 最初的理论基础和算法设计都来自于他。Automerge 的核心维护者 Orion Henry ,也是实验室的三位创始人之一。
实验室本身,要从 Heroku 说起。2010 年 Heroku 被 Salesforce 收购后,联合创始人 Adam Wiggins 、James Lindenbaum 和 Orion Henry 在 2015 年重聚,成立了 Ink & Switch 实验室。Peter van Hardenberg ( Heroku Postgres 的创建者)于 2016 年加入,2020 年成为实验室主管。团队一开始并不知道要做什么具体产品,而是先思考一个根本问题:"计算到底应该怎么服务人?"这种从理念出发的方式,决定了后来 local-first 的走向。
Ink & Switch 不做面向市场的产品,而是先提出理念,再围绕理念做技术探索和原型验证,产出论文和可运行的实验性原型——这些原型会成为其他人做产品的想象力来源。类似于当年的 PARC 实验室发明了图形用户界面和以太网。
理念背后有一种朴素的直觉:不会有多少普通用户愿意自己跑一个服务器来掌控数据,那为什么不让用户自己的设备就是数据存放的地方?思路很自然,但最难的问题随之而来——当多台设备各自修改同一份数据,冲突怎么解决?
这里有一个有趣的反转。本地优先的目标是让软件摆脱对服务器的依赖——数据在本地,协作走点对点,服务器不再是必需品。而提出这个理念的人,此前十年做的事情恰恰是让所有人把应用和数据交给服务器。Heroku 是最早的云平台之一,开创了"git push 即部署"的体验。Peter van Hardenberg 在 Heroku 从零搭建了托管 PostgreSQL 服务,比 Amazon RDS 支持 PostgreSQL 早了三年。这种转变原因很简单——服务器-客户端模型并不是用户想要的。数据在别人的服务器上,离线就没法用,服务商关了数据就没了。
于是,建造云的人转身要摆脱云。
CRDT
云应用给了我们协作,传统软件给了我们数据所有权,能不能两个都要?把数据放回本地之后,核心难题就一个:两个人各自在本地改了同一份文档,没有服务器做裁判,怎么合并?
现有工具的处理方式往往是生成一个冲突副本,或者把冲突文档丢进一个专门的文件夹,让用户自己想办法。这不是解决方案,而是把问题转嫁给了用户。
CRDT ( Conflict-free Replicated Data Type ,无冲突复制数据类型)的思路是从数据结构层面让冲突不可能发生。
举一个最简单的例子。假设几台设备要统计同一件事的发生次数,做法是:每台设备只递增自己的计数器,同时保存其他设备的计数值,总数等于所有设备的计数之和。因为每台设备只改自己的那一格,不碰别人的,根本不存在冲突。无论各设备以什么顺序同步,最终结果都一样。
这就是 CRDT 的核心直觉:不是在冲突发生后去解决它,而是把操作设计成怎么组合都不会冲突。在数学上,这要求并发的操作满足交换律——不管谁先谁后,结果一样。需要注意的是,CRDT 提供的不是完美的实时一致性,而是"强最终一致性":两个副本可能暂时不同步,但只要同步过消息,就一定会达成一致,不需要人为介入。
计数器只是最简单的情况。要在文本编辑、列表排序、树形结构上实现同样的无冲突合并,复杂度要高得多。
目前比较成熟的开源 CRDT 库有Automerge、Yjs、Loro。
关于 CRDT 更详细的介绍,推荐读陈子轩的《 CRDT 简介》以及他的博客,他是 Loro 的维护者。
CRDT 历史
在 CRDT 之前,协同编辑的主流方案是 OT ( Operational Transformation ,操作变换),1989 年由 Ellis 和 Gibbs 提出,Google Docs 至今仍在使用。OT 的思路是由一台中心服务器对并发操作进行变换来保证一致性,在有中心服务器的场景下运行良好。但要让它在去中心化环境下工作,异常困难。
CRDT 的学术理论脉络可以追溯更早。2006 年,Oster 等人发表了 WOOT 算法,是最早的协同文本编辑 CRDT ,虽然当时还没有"CRDT"这个名字。2011 年,Marc Shapiro 等人正式提出了 CRDT 的定义,将其分为 State-based 和 Op-based 两类,并给出了数学证明。
理论框架早已建立,但工程实现充满挑战。
几个关键问题:数据膨胀——最朴素的做法是每个字符带一个全局唯一 ID 加上因果关系元数据,1KB 的文档可能需要 100KB 的元数据。数据回收——CRDT 通过只增不删来保证无冲突合并,但这样数据永远膨胀,早期一个 10 万字且经过大量修改的文档能吃掉 800MB 内存。排序问题——在同一位置并发插入字符时,如何让数学操作与用户意图保持一致?早期 CRDT 算法可能把"hello"+"world"逐字符交错成"hweolrlold"。还有更多问题:单一数据类型的 CRDT 不难,但一个文档里同时包含 map 、list 、text 多种格式呢?每种格式的语义、多种格式的交互都很复杂。再比如一个长期离线的节点突然上线,带来巨量历史操作,如何处理?测试也困难重重,很多 bug 需要极其特殊的条件才能触发。
Automerge 记录了自己早期版本的性能:一篇学术论文的完整编辑过程,最终文档约 10 万字符,共产生约 26 万次插入和删除操作。由于早期 Automerge 将每次单字符编辑都存为一条独立的 JSON 操作记录,每个字符带来约 240 字节的元数据开销,序列化后文件体积膨胀到数十 MB ;回放前 10 万次操作就需要 43 秒,在约 23.5 万次操作时便耗尽了 Node.js 默认的 1.4GB 堆内存而崩溃,根本无法完成全部回放。这正是后来 Automerge 2.0 用 Rust+WebAssembly 重写并引入列式二进制编码的核心动因。
今天另一个 CRDT 库 Loro 展示了这个领域的最新进展。Loro 用 Rust 编写,2024 年 10 月发布 1.0 ,在同一条 26 万次操作的基准测试中,Loro 的回放耗时约 176ms ,文档体积为 128KB ,并且 Eg-walker 算法允许已同步的历史操作被安全回收,缓解了早期 CRDT"数据只增不减"的根本问题。Automerge 也在进步,120 万字符的白鲸记,纯文本大小 1.2MB ,Automerge2.0 时内存占 700MB ,Automerge3 内存占 1.3MB 。一个有大量历史的文档,旧版 Automerge 加载超过 17 小时都无法完成,3.0 只需 9 秒。
上文的性能数据只提到了 Loro 和 Automerge ,但如果追溯历史,三个库各有侧重。Yjs ( GitHub 21k+ star )最早把 CRDT 做到了工程可用,生态最成熟; Automerge ( GitHub 6k+ star )从学术出发,追求通用的数据模型和完整的版本历史; Loro ( GitHub 5k+ star )最年轻,试图兼取两者的长处,性能最好。三个项目恰好勾勒出这个领域十年来的演进。
Kevin Jahns 在德国亚琛工业大学读书期间开发了 Yjs ,2015 年发表论文。他设计的 YATA 算法,核心创新是用扁平链表而非树结构来表示文档,大幅降低了计算开销,性能长期领先于同期的学术实现。但 Yjs 的设计聚焦于列表和文本——如果数据是复杂的嵌套结构,就需要自己想办法映射。目前 Yjs 生态最成熟,GitHub 超过 2 万 star ,Jupyter Notebooks 的协同编辑就基于 Yjs 。
Automerge 走了另一条路:让 CRDT 支持任意嵌套的 JSON 结构。2017 年 Ink & Switch 与 Martin Kleppmann 合作启动了这个项目,理论基础是 Kleppmann 同年发表的论文"A Conflict-Free Replicated JSON Datatype"。Automerge 还完整保留文档的编辑历史,支持类似 Git 的版本回溯和分支。代价是早期纯 JavaScript 实现非常慢,Kleppmann 自己说过,最初的版本"极慢,还有 bug",只是研究质量的软件。2020 年起团队用 Rust 重写后端,性能问题才逐步解决。
Loro 出现在 2023 年,由陈子轩创立。它试图同时解决前两个库各自的短板,技术基础来自 Joseph Gentle 提出的 Eg-walker 算法——没有并发编辑时开销接近 OT ,有并发时才启动 CRDT 的合并逻辑。Eg-walker 允许已同步的历史操作被安全回收,缓解了早期 CRDT"数据只增不减"的根本问题。在文本编辑上,Loro 整合了 Fugue 算法来解决交错异常,并在此基础上开发了自己的富文本 CRDT 算法。
理想
一言蔽之,本地优先不是关于把数据放在哪里的产品理念,而是一种新的软件架构。
这种架构的可贵之处在于对云的最小化依赖。服务器可以扮演端到端加密的存储与同步角色,但无法查看用户的内容。这从根本上改变了安全模型——即使服务器被攻破,攻击者拿到的也只是加密数据,平台大规模数据泄露的问题因此得到缓解。
在 AI 时代,网络攻击的成本在降低。也许我们会去到赛博朋克 2077 里的世界——AI 成为攻击的手段,赛博空间的全面战争爆发。如何储备相关的技术,把把流窜的恶意 AI 行为,挡在没有被 AI 摧毁的残存网络之外,就是一个很有趣的科幻故事与未来问题了。
不只是本地优先。GNU/Linux 和各类 FOSS 工具链、端到端加密协议、与密码学支持的各种安全交互、多样小型的新网络协议栈实验、手机中的 SE...这些技术的发展共同允诺了一种可能性:从云退回到本地,重新想象数字世界的样子。
虽然不知道它会走向何方。但至少它对个人更友好,也限制了平台的能力。至于是否会让社会变得更美好,与技术无关,取决于每个人的道德与努力——让这些技术不被扭曲。
