1.前置阅读
样品地址:aHR0cHM6Ly93d3cuYXFpc3R1ZHkuY24v
本篇文章可能会省略某些过程,直接使用下面文章的结果,所以建议先阅读下面的文章。本篇文章也有与其他不一样的处理方法,以及单纯使用python来还原数据的加密和解密。
1.某空气质量监测平台无限 debugger 以及数据动态加密分析
2.Python 爬虫进阶必备 - 以 aqistudy 为例的无限 debugger 反调试绕过演示(附视频)
2.过反调试
先打开f12后,打开网页,直接遇到debugger
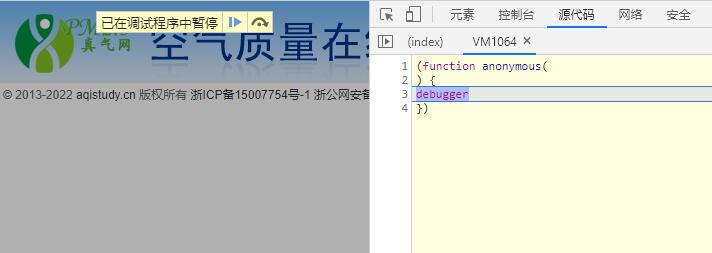
此时通过调用堆栈查找最上层
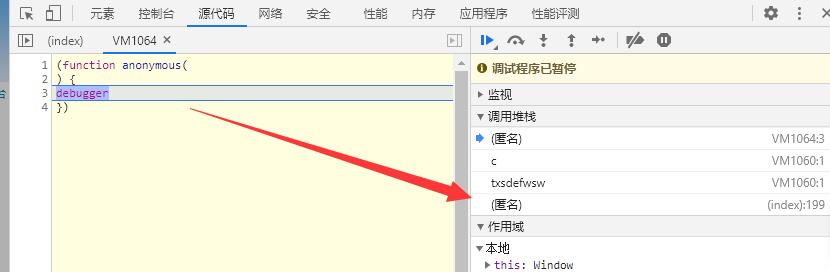
点击后跳转到主页源代码
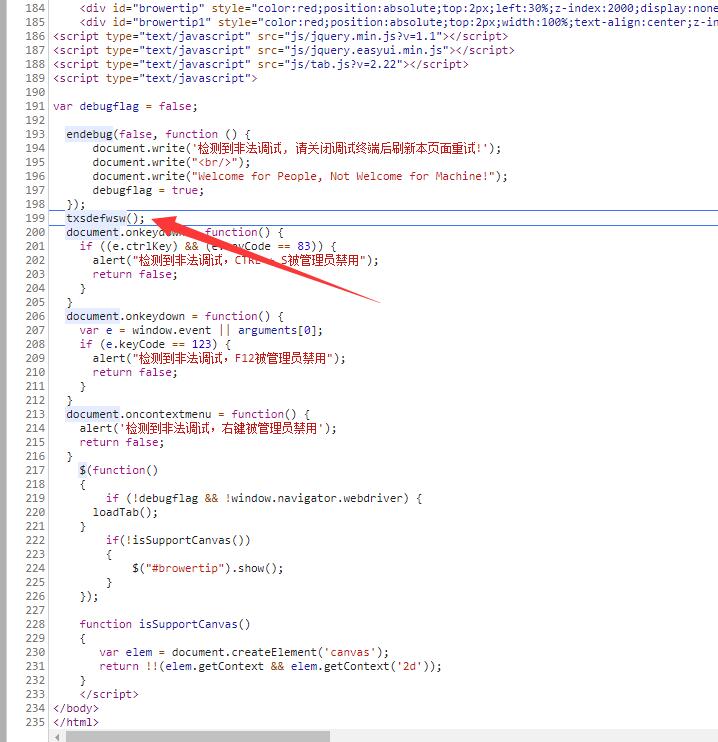
debugger是出现在 txsdefwsw函数里面,如果有办法可以使得这个函数不执行,那是不是就相当于不会出现debugger了。
这里参考了志远哥的fd插件里面,hook注入功能的想法。例如在网页的最前面加入自己的代码,或者修改源代码中的内容,就可以达到某些想要的效果。这里我是用的是mitmproxy这个软件
首先进行安装,直接使用pip
pip install mitmproxy
安装完成后编写一个处理响应的脚本,并命名为main.py
import mitmproxy.http
import re
print('脚本初始化成功')
def request(flow: mitmproxy.http.HTTPFlow):
pass
def response(flow: mitmproxy.http.HTTPFlow):
if 'https://www.aqistudy.cn/' == flow.request.url:
html = flow.response.text
html = html.replace('txsdefwsw();', '// txsdefwsw();')
flow.response.text = html
然后在命令行启动mitmproxy
mitmdump -q -p 8888 -s main.py
其中 -q 表示静默运行。-p表示监听的端口,-s 表示处理的python脚本
然后打开【网络和internet】设置,去到代{过}{滤}理
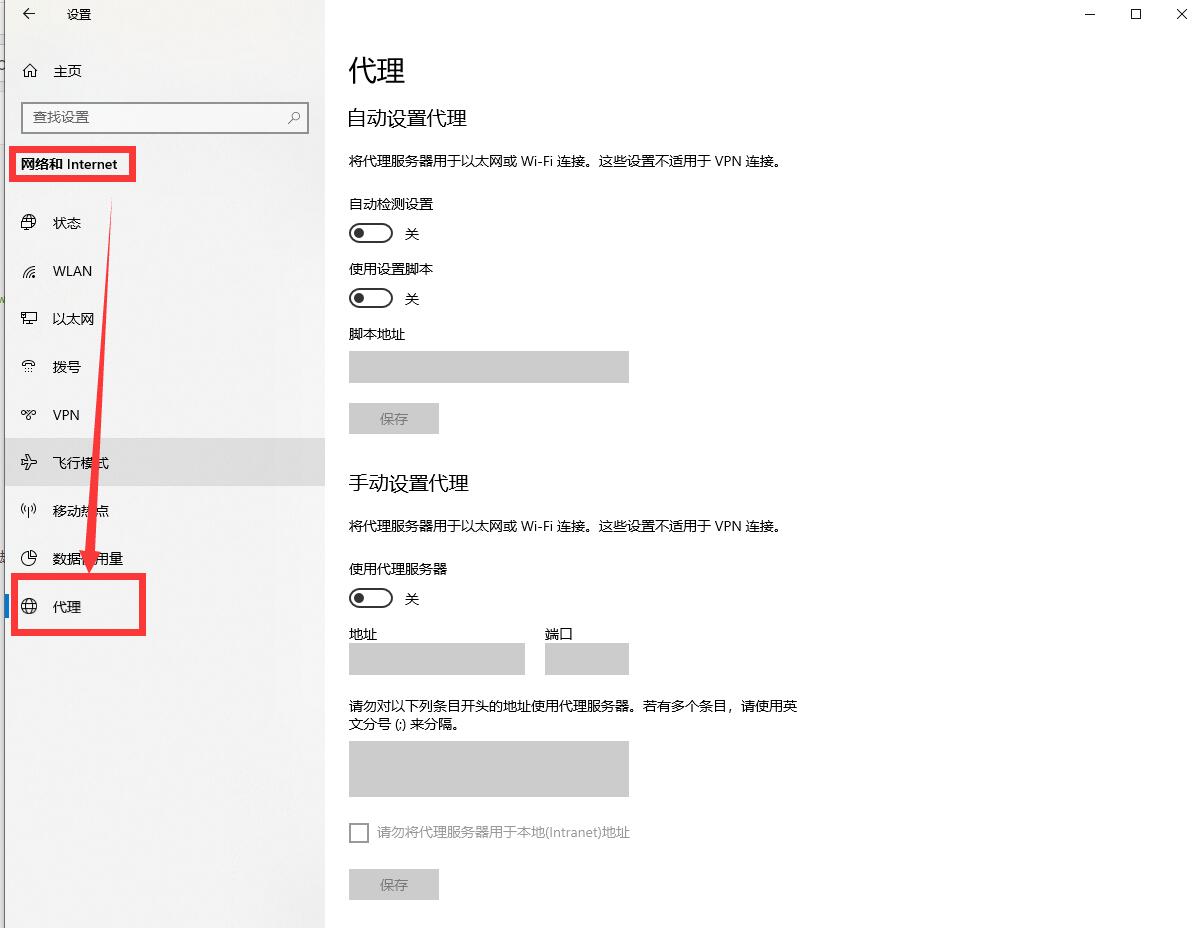
打开代{过}{滤}理服务器开关,地址填写【127.0.0.1】,端口填写刚刚上面的【8888】,然后点击保存。这是再次打开网页
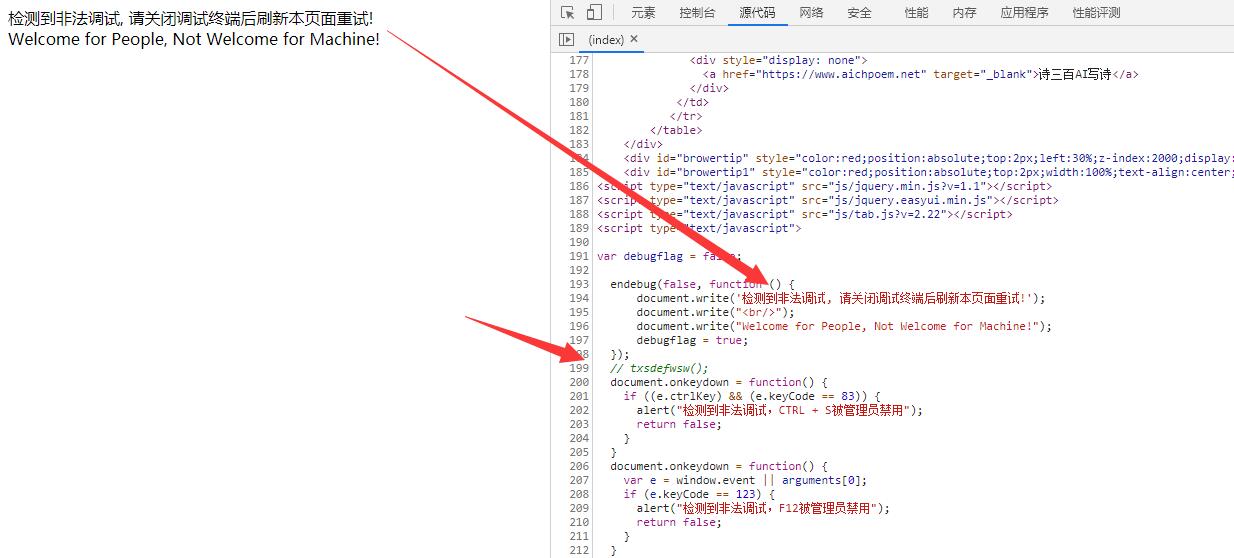
此时可以看到txsdefwsw函数已经被注释了,自然就没有出现debugger了。但是出现了其他的反调试情况。上面的【document.write('检测到非法调试, 请关闭调试终端后刷新本页面重试!');】重写了页面,为了不让它直接,在前面加上return
def response(flow: mitmproxy.http.HTTPFlow):
if 'https://www.aqistudy.cn/' == flow.request.url:
html = flow.response.text
html = html.replace('txsdefwsw();', '// txsdefwsw();')
html = html.replace("document.write('检测到非法调试, 请关闭调试终端后刷新本页面重试!');",
"return; document.write('检测到非法调试, 请关闭调试终端后刷新本页面重试!');")
flow.response.text = html
再次刷新网页
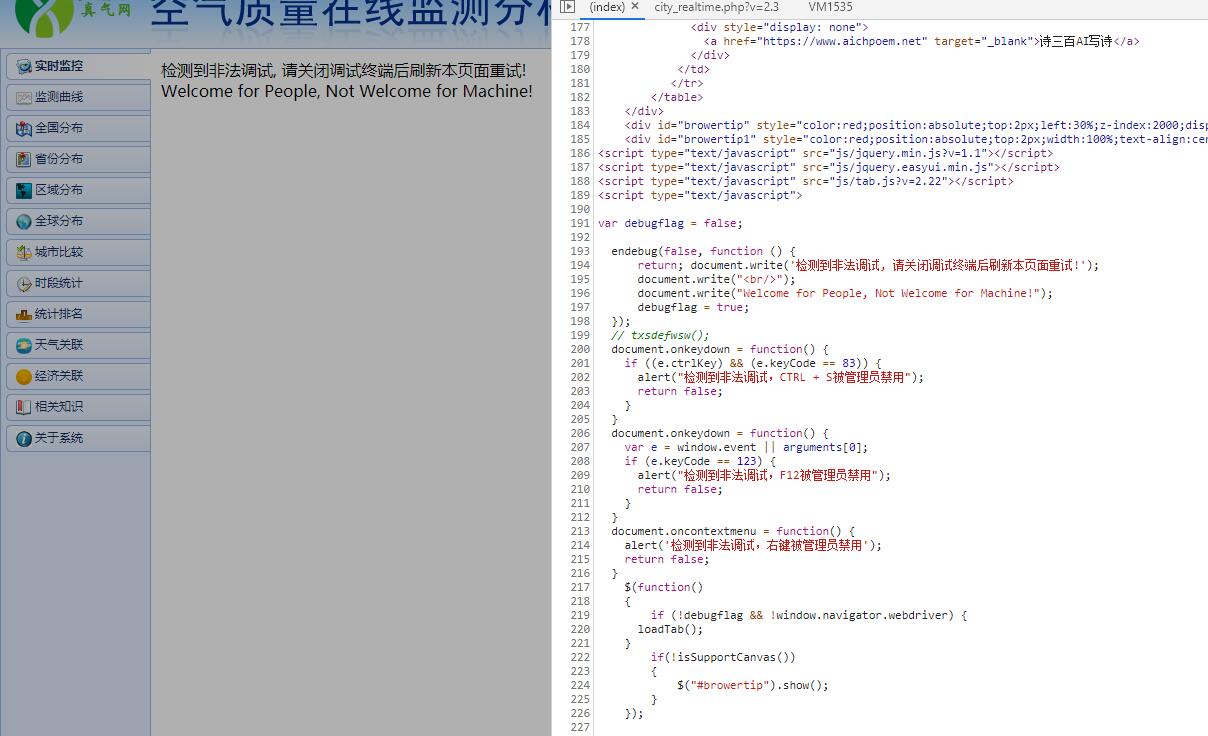
可以看到最外层的页面没有被重写,说明这里的反调试已经过了。但是这时又出现了之前无限debugger的情况。再次通过调用堆栈的最上层
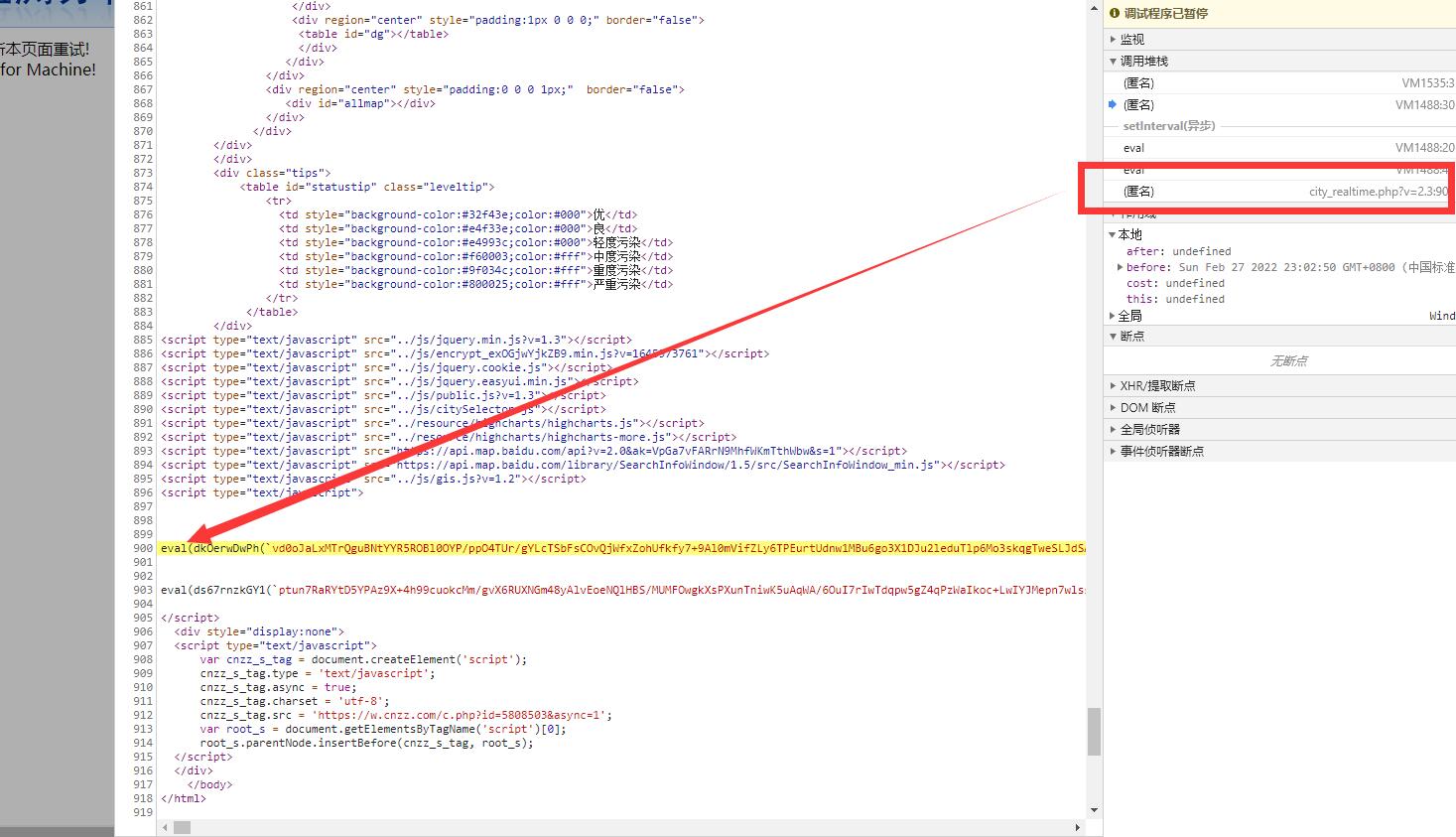
发现是这个eval出来的,这里有两个eval,只注释第一个有反调试检测的
def response(flow: mitmproxy.http.HTTPFlow):
if 'https://www.aqistudy.cn/' == flow.request.url:
html = flow.response.text
html = html.replace('txsdefwsw();', '// txsdefwsw();')
html = html.replace("document.write('检测到非法调试, 请关闭调试终端后刷新本页面重试!');",
"return; document.write('检测到非法调试, 请关闭调试终端后刷新本页面重试!');")
flow.response.text = html
elif 'html/city_realtime.php' in flow.request.url:
html = flow.response.text
js = re.findall('eval\(.+', html)[0]
html = html.replace(js, '// ' + js)
flow.response.text = html
最后再次刷新网页
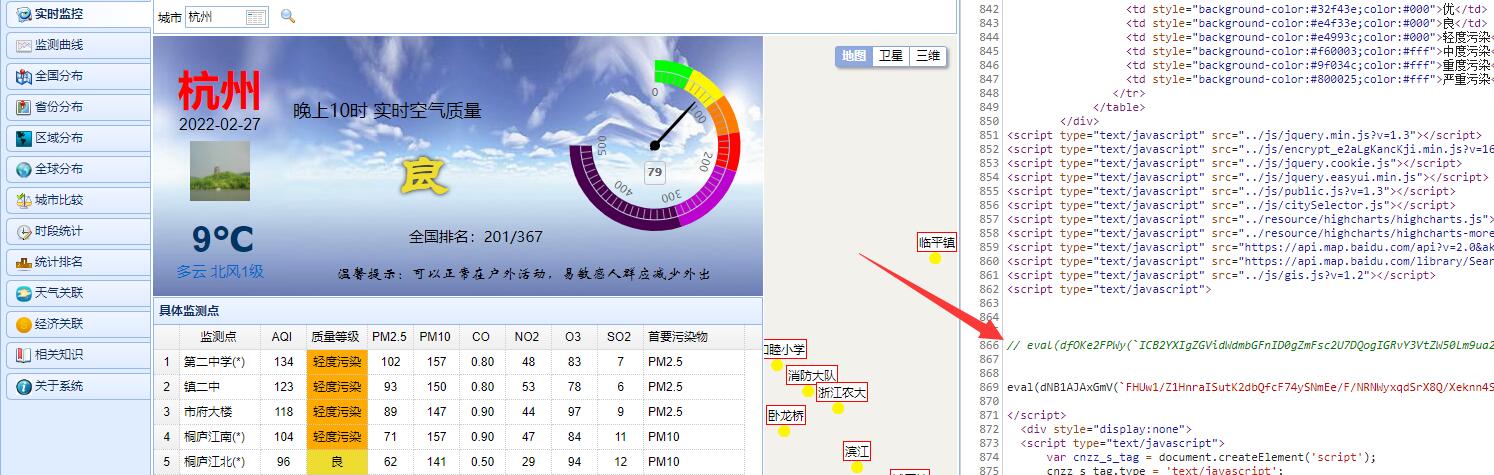
可以看到注释以后,不会再出现反调试的情况,这时反调试已经过完,可以进行js代码分析
3.js分析
分析过程给出的文章中,均有详细的介绍,所以本篇文章对分析部分跳过一些内容,仅对关键地方介绍。
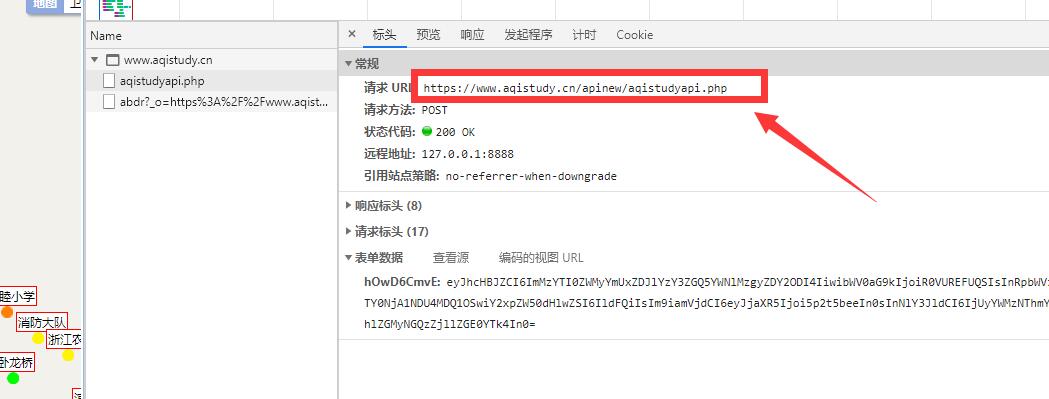
数据是通过这个接口获取的,请求体和响应体都被加密了
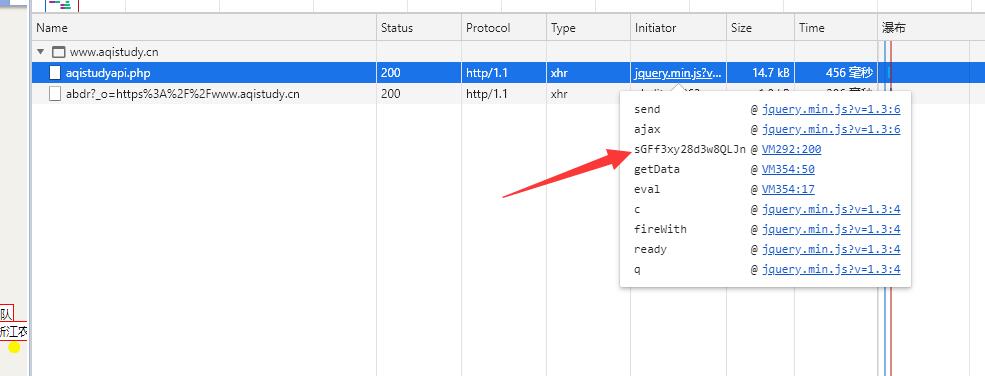
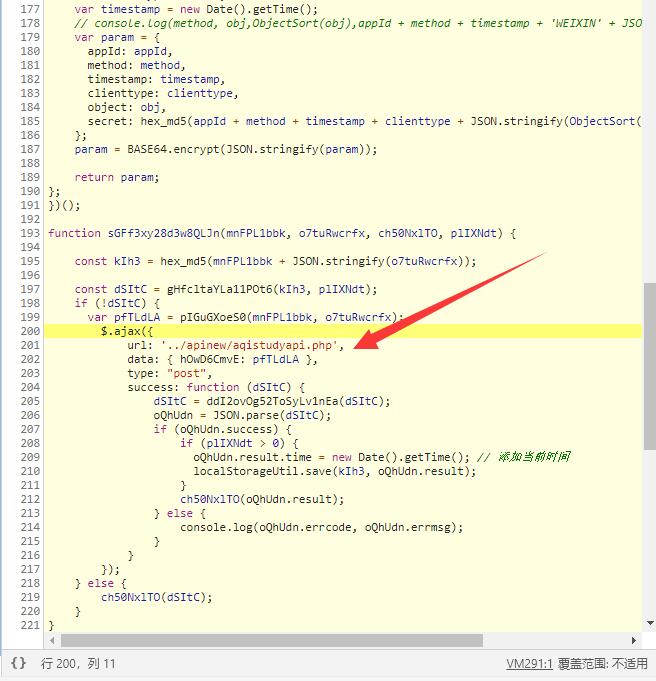
通过调用堆栈,很容易定位到函数调用的地方,这里是通过gHfcltaYLa11POt6函数对参数进行加密,请求成功后,调用ddI2ovOg52ToSyLv1nEa函数进行解密。
但是直接扣代码的话,也没有办法快速解决,因为这个js是会不断改变了,按照前面文章的说法,这个js平均每10分钟变一次,所以并不能简单的把代码扣下来直接用。
经过我向多个大佬询问,这个网站的js会变,但是接口的加密逻辑是不变的。如果把逻辑改成python,那么只有逻辑不变,就可以一直跑了。
4.代码逻辑改写
首先第一步就是获取加密的源代码,也就是gHfcltaYLa11POt6函数的改写
首先从cityrealtime.php?v=2.3中提取带有【/js/encrypt】的js链接,并获取js内容
requests = requests_html.HTMLSession()
url = 'https://www.aqistudy.cn/html/city_realtime.php?v=2.3'
headers = {
'User-Agent': 'Mozilla/5.0(WindowsNT10.0;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/69.0.3497.100Safari/537.36',
}
response = requests.get(url, headers=headers)
url = filter(lambda n: '/js/encrypt_' in n.attrs['src'], filter(lambda n: 'src' in n.attrs.keys(), response.html.xpath('//script'))).__next__().attrs['src'].replace('../js/', 'https://www.aqistudy.cn/js/')
print(url)
response = requests.get(url, headers=headers)
data = response.text
然后需要执行代码,获取eval之后的内容,eval后如果存在dswejwehxt,还需要进行base64解码
while data.startswith("eval("):
with open('temp.js', 'w', encoding='utf-8') as f:
f.write('console.log(' + data.strip()[5:-1] + ')')
nodejs = subprocess.Popen('node temp', stderr=subprocess.PIPE, stdout=subprocess.PIPE)
data = nodejs.stdout.read().decode().replace('\n', '')
if 'dswejwehxt(dswejwehxt' in data:
data = re.findall('(?
这时,data已经是明文的js代码,但是这里的js有可能是压缩的,也有可能是没有压缩的。这样对后面使用正则匹配非常不友好。所以这里使用ast统一格式化代码
const parser = require("@babel/parser");
const generator = require("@babel/generator");
const fs = require("fs");
console.log(generator.default(parser.parse(fs.readFileSync('temp.js').toString('utf-8')), {
compact: false,
comments: false,
jsescOption: {
minimal: true
}
}).code);
保存为【script.js】,并放到py同目录
# 格式化代码
with open('temp.js', 'w', encoding='utf-8') as f:
f.write(data)
nodejs = subprocess.Popen('node script', stderr=subprocess.PIPE, stdout=subprocess.PIPE)
data = nodejs.stdout.read().decode()
这个时候的data就是统一格式化后的js代码,这时可以使用正则提取里面的内容,为加密做准备。
appId = re.findall("(?
这时param参数已经组包完成。但是上面文章中有提及。param参数有三种可能,aes加密,des加密和不加密,所以还需要做一个判断
def encrypt_data_aes(text, key, iv):
secretkey = MD5.new(key.encode()).hexdigest()[16:]
secretiv = MD5.new(iv.encode()).hexdigest()[:16]
crypto = AES.new(key=secretkey.encode(), mode=AES.MODE_CBC, iv=secretiv.encode())
return base64.b64encode(crypto.encrypt(pad(text.encode(), AES.block_size))).decode()
def encrypt_data_des(text, key, iv):
secretkey = MD5.new(key.encode()).hexdigest()[:8]
secretiv = MD5.new(iv.encode()).hexdigest()[24:]
crypto = DES.new(key=secretkey.encode(), mode=DES.MODE_CBC, iv=secretiv.encode())
return base64.b64encode(crypto.encrypt(pad(text.encode(), DES.block_size))).decode()
if 'param = AES.encrypt' in data:
keyid = re.findall('(?
然后到最关键的请求接口
dataid = re.findall('(?
这时测试,可以成功获取到加密的响应体,接着就是还原解密的ddI2ovOg52ToSyLv1nEa函数,根据js是固定先进行aes解密,得到的结果再进行des解密,那么可以得到下面的python代码
def decrypt_data(text, data):
keyid = re.findall('(?
测试解密正常,完整代码如下
import requests_html
import time
import json
import base64
import re
import subprocess
from Crypto.Util.Padding import pad, unpad
from Crypto.Cipher import AES, DES
from Crypto.Hash import MD5
def encrypt_data_aes(text, key, iv):
secretkey = MD5.new(key.encode()).hexdigest()[16:]
secretiv = MD5.new(iv.encode()).hexdigest()[:16]
crypto = AES.new(key=secretkey.encode(), mode=AES.MODE_CBC, iv=secretiv.encode())
return base64.b64encode(crypto.encrypt(pad(text.encode(), AES.block_size))).decode()
def encrypt_data_des(text, key, iv):
secretkey = MD5.new(key.encode()).hexdigest()[:8]
secretiv = MD5.new(iv.encode()).hexdigest()[24:]
crypto = DES.new(key=secretkey.encode(), mode=DES.MODE_CBC, iv=secretiv.encode())
return base64.b64encode(crypto.encrypt(pad(text.encode(), DES.block_size))).decode()
def decrypt_data(text, data):
keyid = re.findall('(?

