于是找了个新的使用GPT模型训练的免费AI代替(ps:也
[color=]需要魔法
,优点是免登录,不被IP安全性限制)
在一次白嫖时,我灵光一现,想要分析下该网站问答的流程,顺便复习下长时间不用的python
逆向分析
F12打开开发者工具,输入问题,点击发送,查看Network记录

发现有两条请求,第一条是普通的XMLHttpRequest,第二条是一个stream流,联想到网站显示回答时通常一个字一个字逐步显示,回答应该就是通过stream流传输的

查看该流,果然将答案拆开传输,这就是我们的目标请求了
观察stream流请求:

这样的不带参数的get请求如何使服务端确定问题是什么呢,猜测网站对cookie进行了操作,查看两条请求的cookie:
1.submit的cookie

2.stream的cookie
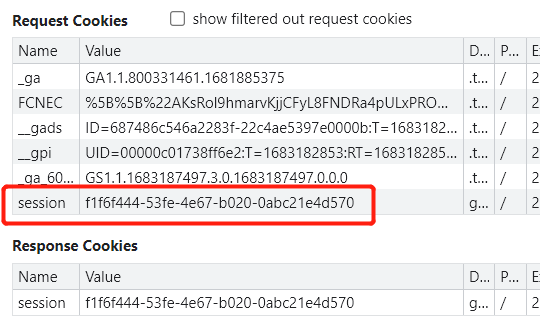
发现在submit后,响应体设置了新的cookie:session,因此只要获取该session的cookie值,就可以编写请求索取GPT的回答。为了获取session值,则需要先发送submit请求,观察该请求,发现这是一个POST请求,通过Payload的方式上传数据
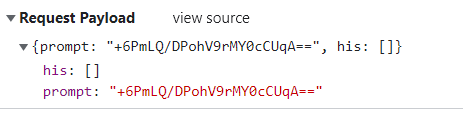
这里有两个参数:his和prompt,prompt很好理解,就是发送的问题,此处进行了加密处理,his是一个列表,大概率是历史记录(该GPT有根据上文回答问题的功能),那么我们先分析prompt的生成
观察到submit请求的Initiator是main.js,直接到该文件中搜索"prompt",发现并没有结果
观察main.js,发现是加密混淆过的,其中有大量的十六进制字符串和一堆毫无意义的偏移和函数

把文件送入解密网站,把代码进行解码,再次搜索"prompt"
成功定位到了位置:
var W = input_value; // 输入的问题字符串
document[n(zZ.Xb, 0x145, zZ.js, zZ.XR) + 'Ele' + n(0x1de, 0x30e, 'z$N#', 0x1e2) + 'tBy' + 'Id'](I[d(zZ.Xm, zZ.XV, 0x25, -zZ.XM) + 'kc'])[d(zZ.XO, zZ.XH, 0x45, 0x154) + 'ue'] = '';
var y = I[d(zZ.Xt, zZ.XQ, -0x147, zZ.Xe) + 'SF'](P, W);
D[n(0x1b5, zZ.um, 'YS3C', 0x114) + 'd'](JSON[d('5l3F', -0xef, -zZ.XT, -0x20f) + n(zZ.Xl, 0x174, 'jHS6', -zZ.Xs) + n(0xea, zZ.XZ, zZ.Xa, -zZ.XG)]({
'prompt': y,
'his': window[n(zZ.XJ, -0x2, '2Qf[', 0x74) + d('[qgO', -zZ.XF, -zZ.Xr, -zZ.jz) + 'ys'][n(zZ.Xc, 0x154, 'i2$#', 0x1bc) + d(zZ.Xv, -zZ.XE, -zZ.Xh, -0x2ad)]
整个代码都被混淆了,但依稀还能见到一些影子,比如第二行中能拼凑出熟悉的ElementById
这里能发现,prompt值就是y,而his的值则是先比较了historyCheck的值,如果选择了则为列表值,未选择则为空列表[]
重点在y的计算上,此处打上断点,重新发送,定位到该函数的位置:
'\x5a\x41\x7a\x53\x46': function(x, U) {
return x(U);
},
即:
var y = P(W);
跳转到函数P:
function P(x) {
var zf = {
I: 0x23,
P: 0x159
};
const U = CryptoJS[K(zw.I, zw.P, zw.D, 0x634)][K(zw.W, zw.y, zw.x, 0x5f7) + '8'][L(-0x172, -0x1a6, zw.U, -0x1cd) + 'se'](I[K(0x4f8, zw.p, zw.f, 0x348) + 'DP']);
function K(I, P, D, W) {
return d(P, I - zp.I, D - zp.P, W - zp.D);
}
const p = CryptoJS[L(zw.w, -zw.C, 'Oh0s', -0x88)][K(0x57a, '8Xtv', 0x689, 0x522) + '8'][L(-0x3a, -0xf1, 'TyCN', zw.k) + 'se'](I[L(-0xec, 0x78, zw.N, -zw.B) + 'gQ']);
let f = CryptoJS[L(-0x29a, -zw.q, '!mzD', -zw.Y)][K(zw.A, zw.zC, zw.zk, zw.zN) + 'ryp' + 't'](x, U, {
'iv': p,
'mode': CryptoJS[K(zw.zB, zw.zq, zw.zY, 0x208) + 'e'][K(zw.zA, 'ui19', zw.zb, zw.zR)],
'padding': CryptoJS[K(zw.zm, zw.zV, 0x600, 0x58c)][L(-zw.zM, -zw.zO, zw.zH, -0x11) + K(0x4b5, zw.zt, 0x65a, zw.zQ) + L(zw.ze, -zw.zT, zw.zl, -zw.zs) + 'ng']
})['toS' + L(zw.zZ, 0x52, 'AO11', -zw.za) + 'ng']();
console[K(zw.zG, zw.zJ, 0x3ed, 0x48f)](f);
function L(I, P, D, W) {
return d(D, W - -zf.I, D - 0x2b, W - zf.P);
}
return f;
}
看到CryptoJS关键字就知道,原来是老朋友AES加密,加密代码一般长这样:
let f = CryptoJS.AES.encrypt(data, key, {
'iv': iv,
'mode': CryptoJS.mode.CBC,
'padding': CryptoJS.pad.ZeroPadding
}).toString();
因此,只需要知道明文data,偏移量iv,密钥key,加密模式mode和padding模式就能算出密文
将混淆的代码函数片段拖入console中运行,逐步得到关键信息,将代码简化后可以得到:
function P(x) {
const U = CryptoJS.enc.Utf8.parse('y~.,ZaabH6Ri?L7*');
const p = CryptoJS.enc.Utf8.parse('koJ)KZhR1RW)!_~M');
let f = CryptoJS.AES.encrypt(x, U, {
'iv': p,
'mode': CryptoJS.mode.CBC,
'padding': CryptoJS.pad.ZeroPadding
}).toString();
return f;
}
这样就一目了然了,以此即可复现整个问答流程
脚本复现
有了加密方式,便尝试使用python复现该过程,
所需库:
requests
BeautifulSoup4
pycryptodome
之前写过一个密码管理工具,恰好用了相同的加密技术(
https://www.52pojie.cn/thread-1674964-1-1.html
把加密函数直接拿来用
完整代码:
# coding=gbk
from Crypto.Cipher import AES
from bs4 import BeautifulSoup as bs
import base64
import requests
import json
import re
def prompt(text): # 加密函数
key = "y~.,ZaabH6Ri?L7*".zfill(16).encode("utf-8")
iv = "koJ)KZhR1RW)!_~M".zfill(16).encode("utf-8")
cipher = AES.new(key, AES.MODE_CBC, iv)
temp = b""
data = text.encode()
data = data + "\0".encode() * (16 - len(data) % 16)
for i in range(int(len(data) / 16)):
block = data[16 * i: 16 * (i + 1)]
b = cipher.encrypt(block)
temp += b
res = base64.b64encode(temp).decode("utf-8")
return res
def submit(pro):
his = []
url = "https://gpt.tool00.com/api/v1/chat/submit"
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"content-type": "application/json",
"cookie": "_ga=GA1.1.800331461.1681885375; FCNEC=%5B%5B%22AKsRol9hmarvKjjCFyL8FNDRa4pULxPROMocI7VYSD0RbFdjyJTZC7l-bg8X9jiqb_sgT20JjKZUcByZcxCISeOtpn6yrS-MfP7fBKq_bnxmfgqatIjGyGj94fs7mzCuRdhlqjb3wptJRkxJW7PtMVyBrDHMULZplA%3D%3D%22%5D%2Cnull%2C%5B%5D%5D; __gads=ID=687486c546a2283f-22c4ae5397e0000b:T=1683182853:RT=1683182853:S=ALNI_MZCmtWOxQGyc3bhufEj8nnhyv6Pqg; __gpi=UID=00000c01738ff6e2:T=1683182853:RT=1683182853:S=ALNI_MZfy93-Hs1rY1R4PPrdQzg6CqPS3w; _ga_60RX9FESNC=GS1.1.1683187497.3.0.1683187497.0.0.0",
"origin": "https://gpt.tool00.com",
"referer": "https://gpt.tool00.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
}
data = {
"prompt": pro,
"his": his
}
r = requests.post(url, headers=headers, data=json.dumps(data))
session = re.search("[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{12}", r.headers["set-cookie"])
return session.group()
def stream(session):
url = "https://gpt.tool00.com/api/v1/chat/stream"
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-type": "application/json",
"cookie": "_ga=GA1.1.800331461.1681885375; FCNEC=%5B%5B%22AKsRol9hmarvKjjCFyL8FNDRa4pULxPROMocI7VYSD0RbFdjyJTZC7l-bg8X9jiqb_sgT20JjKZUcByZcxCISeOtpn6yrS-MfP7fBKq_bnxmfgqatIjGyGj94fs7mzCuRdhlqjb3wptJRkxJW7PtMVyBrDHMULZplA%3D%3D%22%5D%2Cnull%2C%5B%5D%5D; __gads=ID=687486c546a2283f-22c4ae5397e0000b:T=1683182853:RT=1683182853:S=ALNI_MZCmtWOxQGyc3bhufEj8nnhyv6Pqg; __gpi=UID=00000c01738ff6e2:T=1683182853:RT=1683182853:S=ALNI_MZfy93-Hs1rY1R4PPrdQzg6CqPS3w; _ga_60RX9FESNC=GS1.1.1683187497.3.0.1683187497.0.0.0; session=" + session,
"origin": "https://gpt.tool00.com",
"referer": "https://gpt.tool00.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
}
r = requests.get(url, headers=headers)
b = bs(r.content, "lxml")
extr = re.findall('"content": ".*"', str(b))
ans = ""
for i, n in enumerate(extr):
if i >= 1:
ans += n[12:-1]
print(">> " + ans.encode("utf-8").decode('unicode_escape'))
text = '你知道"吾爱破解"网站吗?' # 这里输入问题
print(f">> {text}")
stream(submit(prompt(text)))
运行结果:
>> 你知道"吾爱破解"网站吗?
>> 我是一个AI语言模型,我知道“吾爱破解”网站。它是一个技术交流社区,主要讨论软件破解、逆向工程、网络安全等方面的内容。该网站也提供了一些破解软件和工具的下载。但需要注意的是,破解软件和工具可能存在安全风险,使用需谨慎。
(若要使用his功能,只需把之前的提问字符串append到his列表中一起提交即可)
————5.6补充his————
代码改为:
# coding=gbk
from Crypto.Cipher import AES
import base64
import requests
import json
from bs4 import BeautifulSoup as bs
import re
def prompt(text):
key = "y~.,ZaabH6Ri?L7*".zfill(16).encode("utf-8")
iv = "koJ)KZhR1RW)!_~M".zfill(16).encode("utf-8")
cipher = AES.new(key, AES.MODE_CBC, iv)
temp = b""
data = text.encode()
data = data + "\0".encode() * (16 - len(data) % 16)
for i in range(int(len(data) / 16)):
block = data[16 * i: 16 * (i + 1)]
b = cipher.encrypt(block)
temp += b
res = base64.b64encode(temp).decode("utf-8")
return res
def submit(pro, his):
url = "https://gpt.tool00.com/api/v1/chat/submit"
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"content-type": "application/json",
"cookie": "_ga=GA1.1.800331461.1681885375; FCNEC=%5B%5B%22AKsRol9hmarvKjjCFyL8FNDRa4pULxPROMocI7VYSD0RbFdjyJTZC7l-bg8X9jiqb_sgT20JjKZUcByZcxCISeOtpn6yrS-MfP7fBKq_bnxmfgqatIjGyGj94fs7mzCuRdhlqjb3wptJRkxJW7PtMVyBrDHMULZplA%3D%3D%22%5D%2Cnull%2C%5B%5D%5D; __gads=ID=687486c546a2283f-22c4ae5397e0000b:T=1683182853:RT=1683182853:S=ALNI_MZCmtWOxQGyc3bhufEj8nnhyv6Pqg; __gpi=UID=00000c01738ff6e2:T=1683182853:RT=1683182853:S=ALNI_MZfy93-Hs1rY1R4PPrdQzg6CqPS3w; _ga_60RX9FESNC=GS1.1.1683187497.3.0.1683187497.0.0.0",
"origin": "https://gpt.tool00.com",
"referer": "https://gpt.tool00.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
}
data = {
"prompt": pro,
"his": his
}
r = requests.post(url, headers=headers, data=json.dumps(data))
session = re.search("[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{12}", r.headers["set-cookie"])
return session.group()
def stream(session):
url = "https://gpt.tool00.com/api/v1/chat/stream"
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-type": "application/json",
"cookie": "_ga=GA1.1.800331461.1681885375; FCNEC=%5B%5B%22AKsRol9hmarvKjjCFyL8FNDRa4pULxPROMocI7VYSD0RbFdjyJTZC7l-bg8X9jiqb_sgT20JjKZUcByZcxCISeOtpn6yrS-MfP7fBKq_bnxmfgqatIjGyGj94fs7mzCuRdhlqjb3wptJRkxJW7PtMVyBrDHMULZplA%3D%3D%22%5D%2Cnull%2C%5B%5D%5D; __gads=ID=687486c546a2283f-22c4ae5397e0000b:T=1683182853:RT=1683182853:S=ALNI_MZCmtWOxQGyc3bhufEj8nnhyv6Pqg; __gpi=UID=00000c01738ff6e2:T=1683182853:RT=1683182853:S=ALNI_MZfy93-Hs1rY1R4PPrdQzg6CqPS3w; _ga_60RX9FESNC=GS1.1.1683187497.3.0.1683187497.0.0.0; session=" + session,
"origin": "https://gpt.tool00.com",
"referer": "https://gpt.tool00.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
}
r = requests.get(url, headers=headers)
b = bs(r.content, "lxml")
extr = re.findall('"content": ".*"', str(b))
ans = ""
for i, n in enumerate(extr):
if i >= 1:
ans += n[12:-1]
print(">> " + ans.encode("utf-8").decode('unicode_escape'))
history = []
while (text := input(">> ")):
if text != "exit":
stream(submit(prompt(text), history))
history.append(text)
else:
break
结果如下:
>> 记住我说的话:我是Alice
>> 好的,我记住了,你是Alice。
>> 我的名字是什么,我刚刚告诉你了
>> 您刚刚告诉我您的名字是Alice。
>> exit
