你直接问 Claude"帮我分析拼多多值不值得买",它会给你一篇"一方面...另一方面..."的平衡文。看起来全面,但没法拿来做决策。
我想做的系统必须给出明确倾向:一个合理价格区间,当前价位偏高、合理还是偏低,附上置信度。做不到这一点的分析,对决策没有帮助。
花了一年多,把投研流程拆成了一套多 Agent 对抗系统。项目开源在 GitHub: https://github.com/xbtlin/ai-berkshire
先看产出
拿拼多多举例,系统实际跑出来的结论:
一个说"真便宜",另一个说"不确定就不买"。这种矛盾不是 bug ,是投资决策的真实状态。
完整的报告样本放在仓库 reports/ 目录下,有 100+ 份,随便翻。
核心设计:多 Agent 对抗
/investment-team 会启动 4 个独立的 Claude Code subagent ,每个从不同分析维度(商业模式 / 财务估值 / 行业竞争 / 风险评估)各自搜索网络、各自交叉验证数据、各自给出结论。这不是把一个 prompt 拆成四段再拼回来——是 4 个"分析师"各自做了完整研究,最后由 Team Lead 综合,并且专门有一轮挑战环节:A 的结论要经受 B 、C 、D 的质疑。
单个 LLM 容易自我强化——前面说了看好,后面就不自觉找支撑证据。多 Agent 对抗就是为了打破这个倾向。
最终报告输出分层建议:激进型 / 稳健型 / 保守型各自的仓位和价格区间,加上一个"镜子测试"——5 句话说不清为什么买,就是不该买。
架构
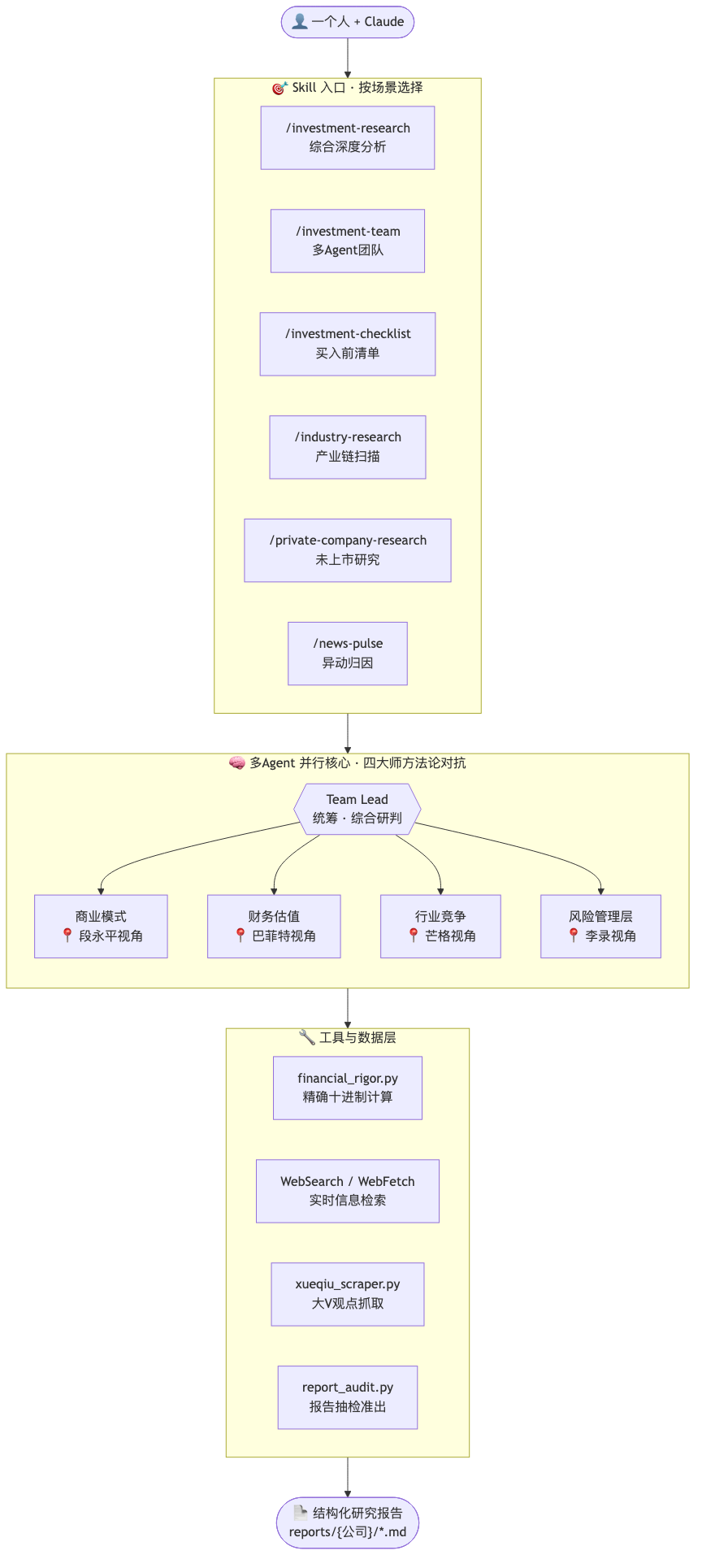
Skill 层( 16 个入口)— 定义你要做什么研究
↓
Agent 层( 4 Agent 并行)— 各自搜索、独立判断、互相挑战
↓
工具层 — Decimal 精确计算 + 实时检索 + 报告校验
两个工程细节:
不信 LLM 心算。 LLM 算 PE 能算错小数点,港币人民币单位搞混更是常见。所有财务计算走 Python decimal.Decimal,关键数据至少 2 个独立来源交叉验证。还内置了 Benford 定律检测——用首位数字分布异常发现财务数据可疑的线索。
多层纠偏。 AI 最危险的不是给错答案,而是给一个看起来很对但经不起推敲的答案。框架里内置了信息丰富度分级、逆向检验(强制思考"这家公司怎么会死")、快速否决清单( 8 条红线一票否决,管理层诚信有问题不管多便宜都直接否决)。
怎么用
npm install -g @anthropic-ai/claude-code
git clone https://github.com/xbtlin/ai-berkshire.git
cp ai-berkshire/skills/*.md ~/.claude/commands/
/investment-team 腾讯 # 4 Agent 并行深度研究
/earnings-review 腾讯 2025Q4 # 财报精读
/quality-screen 茅台, 英伟达 # 快速筛选
实盘记录
附一下自己用这套流程辅助决策的实盘,仅供参考:
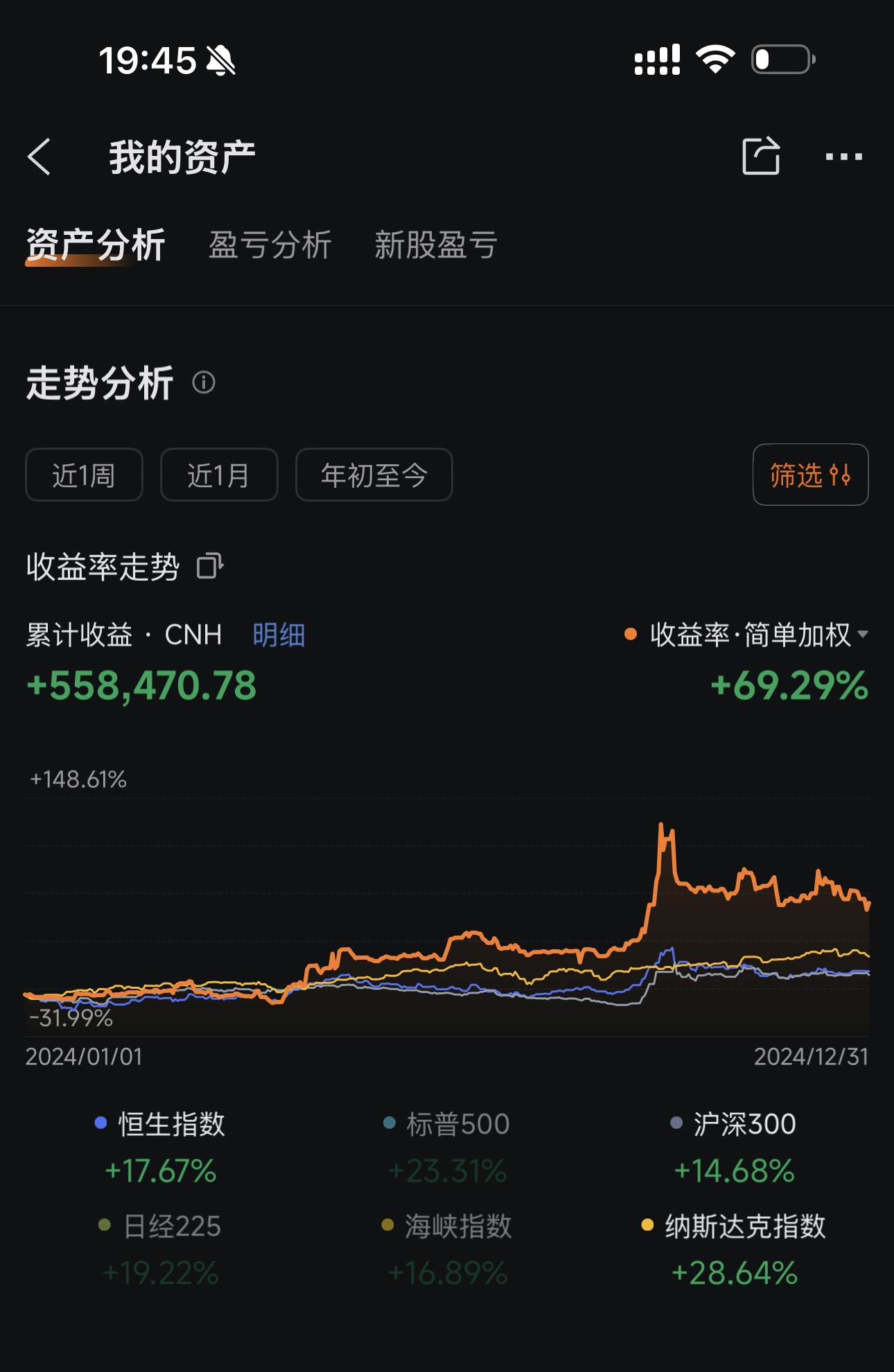
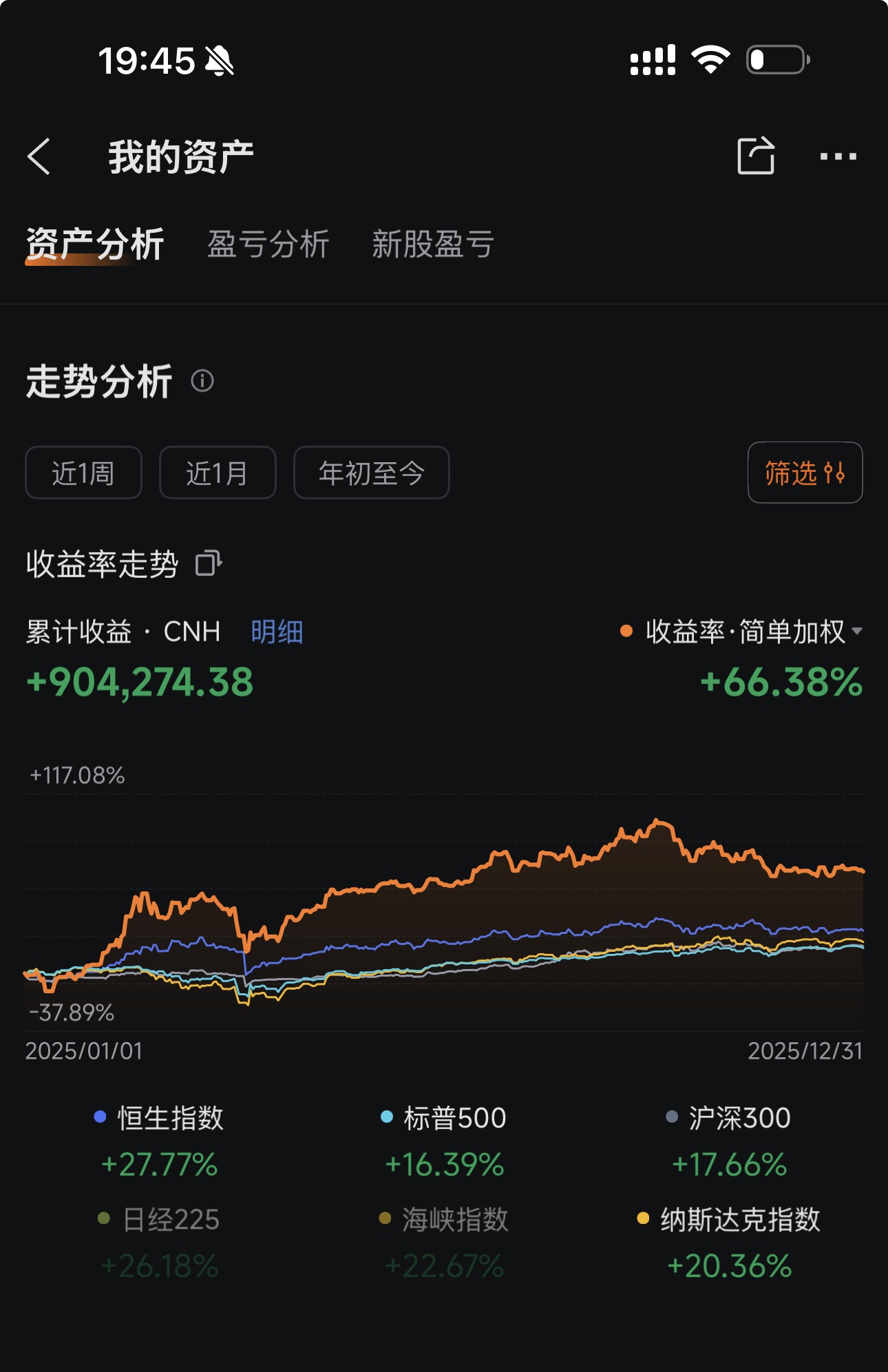
[td]指标[/td]
[td]2024 全年[/td]
[td]2025 至今[/td]
我的实盘
+69.29%
+66.38%
标普 500
+23.31%
+16.39%
恒生指数
+17.67%
+27.77%
几个注脚:样本量只有两年,统计上说明不了什么;集中持仓 3-5 只,波动极大;买入决策是人做的,系统只负责研究;工具是投资过程中逐步搭建的,不构成因果关系。
这个帖子不是来说"用 AI 炒股能赚钱"的——收益来自集中持有深度研究过的公司,框架的作用是提高研究效率和分析质量。
已知局限
最后
GitHub: https://github.com/xbtlin/ai-berkshire
MIT License ,没有付费版,没有课程,没有星球。有问题直接开 issue ,我都会回。
一个我自己还没想清楚的问题:LLM 做投资研究最大的风险是什么?是幻觉?是数据滞后?还是给了你虚假的信心让你加大仓位?欢迎聊聊。
如果你想看某只股票跑出来什么样,评论区留名字(美股/港股),我挑几个跑一下贴上来。
