开篇
为了让新朋友重新了解一下我们的评测结果,我再列一下。
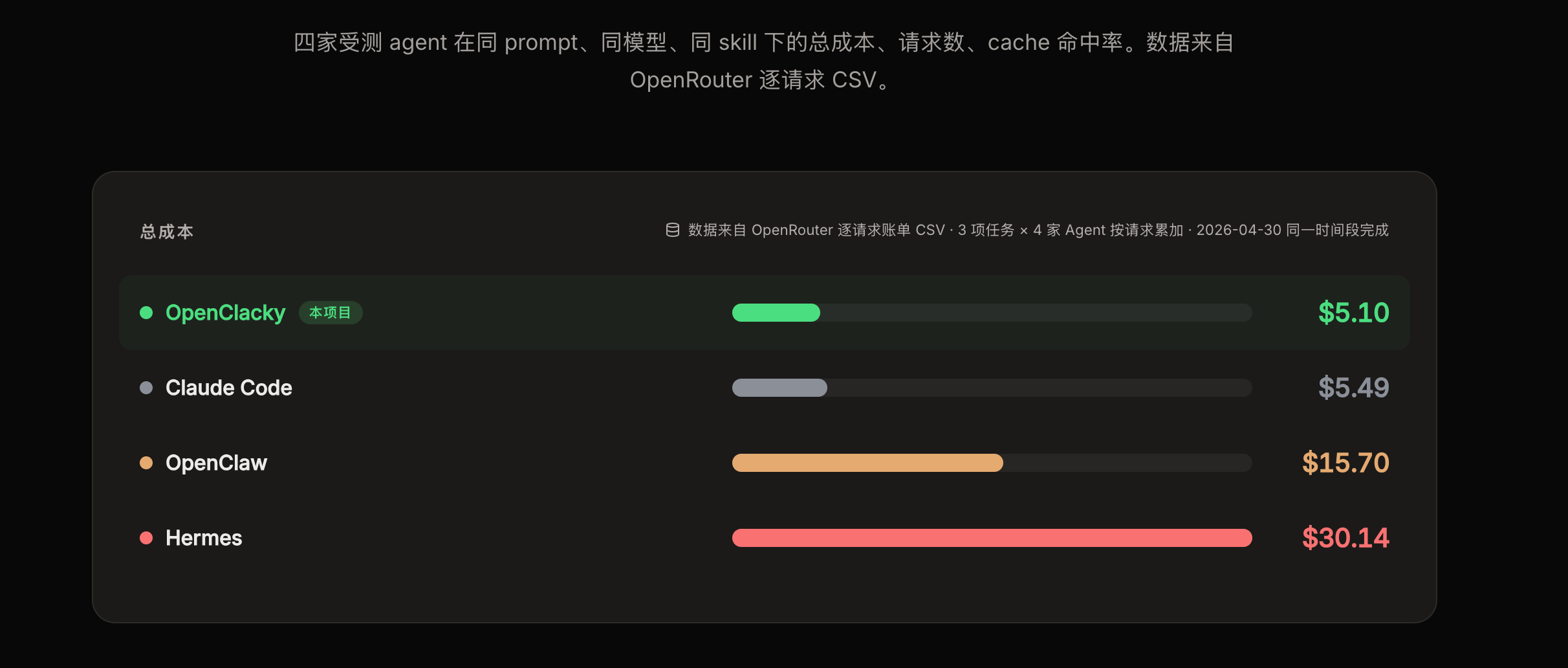
成本极优:3 项任务实测,4 家 Agent 横评,OpenRouter CSV 逐请求核算:
[td]Agent[/td]
[td]总成本[/td]
[td]请求数[/td]
[td]Cache 命中率[/td]
OpenClacky
$5.10
51
90.6%
Claude Code
$5.49
70
95.2%
OpenClaw
$15.70
81
88.7%
Hermes
$30.14
218
60.3%
完整数据和产物对比:openclacky.com/benchmark
51 个请求 + 90.6% 命中率 → $5.10 。218 个请求 + 60.3% 命中率 → $30.14 。成本差距的直接原因就两个:请求数和 cache 命中率。
不要忘了,OpenClacky 是一个全功能 Agent:WebUI + 命令行、长期记忆、Skill 技能库、定时任务、IM 接入(飞书/企微/微信)、浏览器自动化、子 Agent 、运行时切模型、Skill 自进化与动态加载。
而很多开源 Agent 也许有较好的 Token 消耗,或功能不全,或命中率不高。
在实践中最大的问题是:这些功能里很多跟"高 cache 命中率"是结构性冲突的。
举例:
单看任意一头都不难做:少做功能,命中率自然高;不管账单,功能可以堆得很猛。难的是两头同时做。这篇文章讲我们在每个冲突点上具体怎么取舍。
效果已经不是当前 Agent 的主要矛盾,成本才是。
起步:两年失败史
第三代之前还有两代,失败的很严重。但我感觉现在还有很多人在踩坑,估计很多人有争议,但我 100% 站我自己的观点。
第一代( 2024-2025 上半):RAG / 知识库
把用户 codebase 、文档、历史会话全 embedding 进向量库,hybrid 检索 + 重排 + query rewrite 。Agent 流程是"先查上下文,再答"。
实际跑下来的问题:
结论:千万不要搞任何 RAG 、知识库分片。如果你要上 Agent ,请直接上 Agent ,外加一个适合 AI 去阅读的网站就可以了。(参考我们自反思 Skill product-help 的实现)
第二代( 2025 中期):SWEBench / 多 Agent 工作流
Planner / Coder / Reviewer / Tester 各一个 agent ,消息总线 + 角色 prompt 编排。
实际跑下来的问题:
结论:
第三代( 2025 年底至今)
Ruby 从零重写,4 个月。围绕"cache 局部性"和"工具集稳定性"来组织。后面讲的所有决策都属于这一代。
核心决策 1:双 cache 标记 + 允许失败回退
OpenClacky 同时跑在 Claude / OpenAI 兼容这两条主线上,两边的 prompt cache 行为不同,但工程上我们只关心一个共性:cache 是按"前缀"匹配的——前缀里改一个字节,从那里往后全部失效。
所以前缀的"层次"和"标记位置",决定了你下一轮还能 hit 到哪里。我们把请求前缀分成几段考虑:
前两段交给"系统提示词层"的天然断点,后续每轮都能 hit 。真正需要工程的是"append-only 段"——它每轮都在长尾部,标记打哪儿、打几个,决定了下一轮还认不认得它。
朴素做法为什么不够
最直觉的做法是"每轮在 messages 末尾打一个 marker"。它在以下场景都会失效:
[ol]
[/ol]
我们一开始就栽在 (1) 上。修复链能从 git log 里看出节奏:
8ff66cc fix: cache
6ea99fe fix: prompt cache
e9a3602 feat: prompt cache works fine
7734c97 feat: try 2 point cache
前三个 commit 是逐步逼近,最后一个是结构性正解。
双标记是怎么工作的
每轮我们标 两条 连续消息,不是一条:
第 N 轮: [..., msg_A, msg_B(*), msg_C(*)]
↑ ↑
marker 1 marker 2
第 N+1 轮: [..., msg_A, msg_B(*), msg_C(*), msg_D(*)]
↑ ↑ ↑
(仍在) (仍在) 新 marker
第 N+1 轮发出请求时:
这是一个滚动双缓冲:任何时刻都持有两个断点——一个"刚建立的"(写)和一个"上一轮建立的"(读)。下一轮把"读"再读一次,把"写"扔掉,再在新尾部写一个。永远不会出现两个 buffer 同时失效的瞬间。
为什么是 2 ,不是 3 或 4
主流大模型的 cache 都允许多个标记位(上限不一),但更多并不更好:
简单说:2 是覆盖尾部边界的最小数量,3 多余,4 浪费。
允许失败:单步回退仍然命中
这是双标记的第二个好处,也是当时 7734c97 的真正动机。
模型偶尔需要回退一次 tool call:工具返回错误、用户 Ctrl-C 重试、或者上游 streaming 断了一半。这种情况下"昨天的最后一条"被丢弃了,但倒数第二个 marker 通常仍然落在仍存在的消息上——单步回退后还能命中。
单 marker 在回退时直接作废;双标记是能扛住单步回退的最小数量。我们没继续往上加(三标记也能扛两步回退,但成本不划算)——回退超过一步的概率已经低到可以接受全 miss 一次。
模型切换:为什么要 marker 不动
OpenClacky 支持在 session 中途换模型。工程上要保证两件事:
[ol]
[/ol]
这个细节不做的话,每次切模型一定要都要付完整 cache 重建的钱,用户会很不开心。
不能标的位置
marker 选择逻辑里有一条硬规则:跳过 system_injected: true 的消息。
[session context] 块就是典型例子——它是一次性信息,下一轮尾部已经变了,落在它身上的 marker 是一笔永远读不回来的写入。压缩指令注入也是同样的处理(决策 5 会展开)。
marker 选择从尾部往前走,system_injected 的跳过,凑够两个真实对话消息为止。
本节总结
把这四件事同时做到,普通一轮的 cache 命中率才有可能稳定在 95%+。前三件是 cache 几何,第四件是设计纪律。
决策 2:永不变的 system prompt
OpenClacky 的 system prompt 在 session 启动时一次性构建,之后字节冻结。 任何"想往 system prompt 里塞动态信息"的需求,必须重定向到别的位置。
这条纪律是 cache 命中率的第一道地基——system prompt 一变,后面所有 cache 全废,没有任何"局部修补"能挽回。
但日常跑下来,至少有四类信息"天然想插入到 system prompt":
[ol]
[/ol]
这四类信息都是"session 中途可能变"的。如果写进 system prompt ,任何一次变更都意味着全量 cache 失效。
[session context] 块
我们的做法是把这些信息写进 message 流,而非 system prompt 。每当环境发生模型需要感知的变化时(跨天、切模型、切工作目录),agent 在 history 里追加一条 user 角色的消息:
[Session context: Today is 2026-05-13, Tuesday. Current model: claude-sonnet-4-6.
OS: macOS. Working directory: /Users/.../project]
这条消息被标记为 system_injected: true。它不会被 cache marker 选中(决策 1 已经讲过),不会被算作真实用户轮数,压缩时也不会被原样搬进新历史。
注入是按日期 gate 的:同一天内只注入一条。跨天了,插一条新的。切了模型,插一条新的。大多数 session 里你只会看到一条 session context 块。
这个设计踩过的坑
第一版 inject_session_context 是在 agent 构造期就急切注入的。结果 @history.empty? 返回 false ,run() 误以为是后续轮,跳过了 system prompt 的构建——第一次请求带着一条"today is Tuesday"但没有 system prompt 就发出去了。agent 的行为诡异了大约一天才定位到。
修复只有一行:等 system prompt 构建完毕之后再注入。代码里有一段注释记录了这个约束:
# IMPORTANT: Skip injection when the system prompt hasn't been built yet.
# Otherwise, appending a user message to an empty history makes
# @history.empty? false, which causes run() to skip building the
# system prompt entirely.
教训是:前缀的组装顺序比前缀的内容更要紧。 你可以花大力气设计每一段的内容,但只要组装顺序错一步,整个 cache 策略就是废的。
Skill 列表怎么处理
Skill 列表是最容易跟"永不变的 system prompt"冲突的需求。用户可以随时装新 skill ,模型需要看到 skill 名和描述才能通过 invoke_skill 去调用它。
我们的取舍:skill 列表在 session 启动时渲染进 system prompt ,之后冻结。 session 中途装的新 skill ,模型在当前 session 里看不到——它会看到一条 [session context] 通告说"skill 列表已更新,新 skill 从下一个 session 可用"。
这意味着用户装完 skill 想立刻用会发现用不了,要开新 session 。我们接受这个摩擦,因为替代方案是重渲染 system prompt 导致全量 cache 失效——这个代价打到所有用户的所有 session 的每一轮上。装 skill 是低频操作,cache 命中是每轮都在享受的收益,取舍方向很清楚。
USER.md / SOUL.md 的更新也是同样的处理:session 启动时读取,session 内不再变。
但是,在用户体验上,我们虽然降低了一些 Skill 发现的概率,但一旦用户主动提起新的 skill 时,我们系统仍能及时发现新 Skill 。没有任何缓存,每次都会重建 Skill 列表。
决策 3:invoke_skill 的妙用
invoke_skill 是 OpenClacky 的 16 个工具之一,它是整个 OpenClacky 最核心的设计,花费的时间也最多,它提供 Skill 热加载能力,子 Agent 架构支持,记忆召回能力、Skill 进化能力,但它只占 system prompt 不超过 200 个 Token 。
[ol]
[/ol]
这个设计一口气解决了好几个问题:
子 agent = 状态隔离
做代码审查的 skill 可能需要读几十个文件、跑 grep 、输出长篇分析。如果这些中间步骤都在主 agent 的 history 里,history 会膨胀得很快——cache 命中率没变,但上下文总量上去了,压缩触发得更早,成本更高。
子 agent 把这些中间过程隔离在自己的 session 里。主 agent 只看到最终结论。主 agent 的 history 没有被污染。
动态加载 Skill ,不改 system prompt
装新 skill 的流程就是把一个 SKILL.md 放到 ~/.clacky/skills// 或 .clacky/skills// 下。skill 列表渲染进 system prompt 的时间点是 session 启动,决策 2 已经讲过。
但 invoke_skill 这个工具本身是始终存在的——它不需要 system prompt 里列出所有 skill 才能调用。模型可以通过 [session context] 通告知道新 skill 的名称,然后直接 invoke_skill(skill_name: "xxx")。Skill 的 SKILL.md 是在调用那一刻才读取的,不是预编译进 system prompt 的。
所以"动态加载 skill"这个能力,实际上是 invoke_skill 的运行时读取 + [session context] 的通告组合出来的。不需要改 system prompt ,不需要改工具列表,不需要重启 session 。
Skill 注入与路径处理
每个 skill 的 SKILL.md 可以引用相对路径的资源文件(模板、配置等)。invoke_skill 在启动子 agent 之前会把 skill 的目录作为上下文路径注入,子 agent 能用 file_reader、glob 直接读到 skill 附带的资源。
这让 skill 可以做到"自包含"——一个 skill zip 包里既有指令又有模板,装上就能用。
加密 Skill 与选择性落盘
部分 skill 包含商业敏感内容(客户的 prompt 策略、内部流程等)。OpenClacky 支持对 SKILL.md 做加密存储,运行时解密到内存、用完不落盘。同时 session 的落盘也是选择性的——对于涉及加密 skill 的 session ,可以配置为不持久化到磁盘,只在内存中存在。
这不是 cache 工程的范畴,但它是 invoke_skill 架构的延伸:因为子 agent 的状态是隔离的,选择性不落盘可以精确到某次 skill 调用,而不需要把整个 session 的落盘关掉。
决策 4:控制稳定可靠的工具集 16 个
工具 schema 紧贴 system prompt 之后,在 cache 前缀里。schema 一变,后面全失效。这意味着:每多加一个工具,你不只是多了一份 schema 的 token 成本,你还多了一份"下次改工具时全量 cache 失效"的风险面。
另一面,工具太少也有代价:模型本来一步能做完的事,现在要分两三步(先调一个通用工具获取信息,再调另一个来操作),轮次上去了,每轮都要付 cache 和 output 的钱。
所以这不是一个"越少越好"的问题,而是一个经验平衡点。我们的答案是 16 个。
这 16 个分别是什么
[td]类别[/td]
[td]工具[/td]
[td]说明[/td]
文件读写
file_reader, write, edit
读、写、搜索替换
代码搜索
glob, grep
文件查找 + 内容搜索
执行
terminal
shell 命令
浏览器
browser
接管 Chrome/Edge
网络
web_search, web_fetch
搜索 + 抓取网页内容
任务管理
todo_manager, list_tasks, undo_task, redo_task
规划、撤销、重做
交互
request_user_feedback
需要用户输入时
扩展
invoke_skill
调用 skill (决策 3 )
安全
trash_manager
安全删除( rm → trash )
设计原则
简化参数。 每个工具的参数尽量少、语义尽量明确。比如 glob 只要 pattern 和 base_path,不需要模型去组合 --include / --exclude / --type 这些 flag 。参数越多,模型出错的概率越高,出错就要重试,重试就是成本。
够用但不冗余。 glob 和 grep 是两个工具而不是一个:glob 负责"哪些文件匹配",grep 负责"文件里哪些行匹配"。合成一个会让参数变复杂,模型调错的概率上升。但也没有继续拆成 find_files / list_dir / tree 三个——glob 一个就能覆盖这三个场景。
为每个工具写丰富的测试用例。 工具是 agent 跟外部世界的接口,一个工具出 bug 的代价远高于普通代码出 bug——它会让模型产生错误的观察,进而做出错误的决策,进而需要更多轮次来纠正。我们一共有 1600+ 的用例去覆盖各种场景的处理。最近有 V 友还给我们提交了子项目扫描慢(对,OpenClacky 支持子项目处理)的一个相关优化 issue 。
为什么不是 10 个,也不是 25 个
10 个做不到。undo_task / redo_task / list_tasks 这些看起来"可以不要"的工具,拿掉之后模型就只能用 terminal 跑 git 来处理代码回滚——成功率远低于专用工具,而且 git 操作的副作用很难控制。很多工具设计了一个 code_run ,我们并不推荐,实测反而导致任务变慢(需要写长代码),轮次变多(多次尝试)。
不需要 40+,只需要 16 个。
[td]省掉的能力[/td]
[td]替代方式[/td]
[td]工具数节省[/td]
代码库分析专用工具
code-explorer Skill
~5 个
记忆读写专用工具
recall-memory Skill
~3 个
浏览器自动化(多动作拆分为多工具)
单一 browser 工具统一覆盖
~8 个
Sub-agent 编排工具
invoke_skill 统一入口
~6 个
定时任务管理工具
cron-task-creator Skill
~4 个
如果以后需要第 17 个,我们会加。4 个月了,还没加。
决策 5:压缩——不换模型、空闲时做、压到底
上下文窗口是有限的。不管 200K 还是 1M ,长任务跑下来总会填满。填满之前必须压缩,否则要么截断丢信息,要么溢出直接报错。
压缩是 cache 命中率最大的单点威胁:老的消息被替换成一段摘要,前缀从那一刻起就跟之前不一样了——必然 cache miss。但压缩不可避免,所以问题不是"要不要压",而是"怎么把压缩的破坏降到最低"。
结论一:不要换模型压缩
很多 agent 的压缩流程是开一个独立的 LLM call,用一个便宜/快速的小模型来做摘要。
问题:
等于你为每次压缩付了两笔钱:一笔给压缩 call 本身的 cache miss ,一笔给主 session 压缩后的 cold-warm 阶段。
我们的做法:压缩不开独立 call ,而是把压缩指令作为一条消息插进当前对话的末尾( Insert-then-Compress )。
这条指令被打上 system_injected: true,走正常请求路径。效果:
对比(一次 50K-token 会话的压缩事件):
[td][/td]
[td]独立 call 方案[/td]
[td]Insert-then-Compress[/td]
压缩 call 的 cache hit
0%
~95%
压缩期间 cold token
~50,000
~500
主 session cold-warm 轮数
4–5
1
结论二:20–30 万 token 是压缩的甜区
太早压:浪费了上下文里还有价值的细节,摘要丢信息。
太晚压:上下文太长导致模型注意力分散、推理变慢、输出质量下降。
我们测过多个阈值。20–30 万 token 是效果和成本的甜区——模型还能有效利用上下文,但离溢出还有足够余量来完成压缩本身。
压缩后无论如何会压到 1 万 token 以内。这不是省钱,这是控制后续每一轮的 baseline 成本——history 越短,每轮 input 越少,cache miss 时的惩罚也越小。
结论三:空闲第 3 分钟启动压缩
这是跟 cache TTL 的博弈。大模型厂商的 prompt cache 普遍有 TTL——cache 在一段时间无请求后会过期。过期之后下一轮的 input 是全量 cold ,直接翻到 10× 成本。而且后续每轮都在叠加成本,直到 cache 重新 warm 起来。
所以我们跑了一个空闲计时器(idle_compression_timer.rb):
效果是:用户思考了几分钟回来,看到的是一个已经压缩好、cache 已经 warm的 session 。相比之下,如果不做空闲压缩,用户回来时面对的是一个 cache 过期的长 history——那一轮的 input 可能是 30 万 token 全量付费。单这一个行为,在长思考间隔的场景下就能省 10× 的钱。
空闲计时器跑在后台线程里。记得加锁!
百万上下文的真相
"百万 token 上下文"听起来很性感,但做 agent 有两个现实:
[ol]
[/ol]
真实世界用户停下来思考太过于常见,Cache Missing 太容易发生,Agent 开发者必须想办法帮用户减少开销。
所以我们的策略不是"尽量用满上下文",而是"积极压缩,保持 history 短小"。1 万 token 的压缩后 history + 95% cache hit ,比 100 万 token 的未压缩 history + 99% cache hit 便宜得多,效果也更可控。
如何确保压缩后仍然保证足够好的效果,这是另一个话题,我们后面展开。
决策 6:自进化的工具能力
PDF 、Excel 、Word 、PPT 的阅读和解析是 Agent 经常遇到的需求。处理这类文件通常有两种路径:
[ol]
[/ol]
我们选了第三种路径:首次安装时把预设的文档处理脚本 copy 到用户目录,之后允许 AI 自行更新维护这些脚本。
具体做法:
这就是"自进化"的含义:处理文档的能力不是写死在 gem 里的,它活在用户目录的脚本里,agent 自己可以维护。 第一次可能需要装个 pdfplumber,装完之后就是永久能力。
这个设计把"文档处理"从工具层面拉到了脚本层面,避免了工具列表膨胀,也避免了硬编码 C 扩展依赖。trade-off 是用户机器上需要有 Python 3——但 macOS 和大多数 Linux 发行版默认自带,这个前提在实际用户群里几乎都满足。
决策 7:内置浏览器工具,No Headless
浏览器自动化是 Agent 越来越重要的能力——验证前端改动、抓取文档、自动化测试流程。
市面上主流的做法有两种:
[ol]
[/ol]
我们两种都不用,或者说——我们自己内置了一个 MCP Client ,去接管用户已经在跑的 Chrome / Edge。
为什么不用 Headless
Headless 浏览器的问题是"看不见"。agent 操作的页面用户看不到、不知道 agent 在干什么、出了问题也无法判断。对于 Agent 的使用场景——用户在旁边盯着 agent 干活——"看不见"是很大的信任问题。
另外,Headless 经常遇到反爬检测:登录态拿不到、Cloudflare challenge 过不去、需要手动验证。用户自己的浏览器里已经登录好了、cookie 都在,为什么不直接用?
我们怎么做的
lib/clacky/tools/browser.rb( 610 行)+ lib/clacky/server/browser_manager.rb 是整套实现。架构是:
[ol]
[/ol]
对模型来说,"浏览器"就是 16 个工具里的 1 个,schema 跟其他工具一样稳定,不会因为浏览器的状态变化而改 schema 。 这符合决策 4 的原则。
为什么不把浏览器做成外部 MCP
我们可以不内置浏览器、让用户自己配一个 Browser MCP 服务。但这样做的问题是:
内置一层封装的代价是我们要自己维护 MCP Client 和 daemon 的生命周期管理——browser_manager.rb 里处理了 daemon 启动、心跳检测、超时、crash recovery 。但这个代价是一次性的工程投入,换来的是用户零配置(只要 Chrome 在跑)和工具列表的稳定。
最后,选择 Ruby 的理由
这不是一个显而易见的选择。LLM agent 生态里 Python 和 TypeScript 是主流,Ruby 几乎没有前例。但我们选 Ruby ,而且选对了。
动态语言 + 元编程
Ruby 的元编程能力是我们实现 Skill 自进化、动态加载、工具注册等能力的基础。method_missing、define_method、class_eval 这些能力让运行时的行为修改非常自然。Python 也有类似能力,但 Ruby 在这一层的表达力明显更高。
对于一个"agent 自己可能改自己的辅助脚本"的系统来说,动态语言比静态语言更合适——你不需要重编译、不需要重启,改了就生效。
极致的分发能力
gem install openclacky 一行搞定。RubyGems 的分发链路非常成熟:版本管理、依赖解析、全局可执行文件注册(clacky 命令)都是开箱即用的。用户不需要 clone 仓库、不需要 npm install、不需要 pip 虚拟环境。
对比 Python 的分发——pip install + 虚拟环境 + 可能的 C 扩展编译——Ruby gem 的安装体验明显更丝滑。
零 C 库依赖
这是我们做了大量工程投入才做到的。看 openclacky.gemspec 的依赖列表:
faraday, thor, tty-prompt, tty-spinner, diffy, pastel,
tty-screen, tty-markdown, base64, logger, websocket,
webrick, artii, rubyzip, rouge, chunky_png
全部是纯 Ruby gem ,没有一个需要编译 C 扩展。
这意味着在 macOS / Linux 上,只要有 Ruby ( 2.6+),gem install openclacky 就能装上、立刻能跑。不需要 brew install libxml2,不需要 apt-get install libffi-dev,不需要 Xcode Command Line Tools 。
为了做到这一点,我们做了一些反常规的选择:
这一切是 AI Coding 的产物
说实话,"从零重写 WebSocket 客户端"、"从零实现 LLM streaming 协议"、"用 ANSI escape code 手画 TUI"——这些事情如果纯手写,工程量很大,这在以往完全不现实。
但 OpenClacky 本身就是一个 AI coding agent 。这些"为了极致安装体验而大胆从零重写依赖"的决策,是用 OpenClacky 自己来完成的。一个能写代码的 agent 让"零依赖"从不切实际变成了可执行。这是一个自举的过程——产品帮助自己变得更好。
结语
回头看这 7 个决策,它们背后其实只有一句话:把工程预算花在 harness 上,把智能预算留给模型。
不做 RAG ,不做多 Agent 编排,不做工具堆叠——不是因为这些东西没用,而是因为模型在快速变好。半年前需要 4 个 agent 协作才能勉强通过的任务,今天一个 agent + 一个好的 harness 就能做得更快更便宜。
我们选择把精力放在那些不会随模型进步而过时的事情上:cache 命中率、工具稳定性、安装体验、压缩策略。这些是 harness 层面的基础设施,不管模型换到哪一代都用得上。
如果这篇对你有用,请帮我们点赞,欢迎 PR 。欢迎转发和分享。
OpenClacky 完全开源,MIT 协议:github.com/clacky-ai/openclacky
gem install openclacky 一行装完即用,不需要 Docker 、不需要 clone 仓库。如果你也在做 Agent ,欢迎试试,遇到问题直接开 issue 聊。
4 家 Agent 横评的完整数据、产物对比、录像回放:openclacky.com/benchmark
本文引用的核心代码:Cache 标记 · Insert-then-Compress · Session context 注入 · 空闲压缩 · 浏览器工具
