这套流程可以让 AI 自动操作浏览器,代替你完成一切机械重复性的工作,而且特别的省 TOKEN 。
很多工作流甚至全程不需要 AI 参与,0 TOKEN 就能把自动化任务跑起来。比如可以 0 TOKEN 抓取电商网站评论,导出成 CSV 文件,自动把 Markdown 文章发布到 x ,还有对自己开发的 Web APP 进行 AI 自动化测试。我们并不需要懂浏览器的相关知识,只用自然语言就能完成这些任务。
本期视频我们使用的 Agent 框架是 Claude Code 或者 Codex 。
浏览器自动化方案是 Playwright CLI 搭配配套的 Skill 。

Playwright CLI 是 26 年初微软开源的全新浏览器自动化工具。
Github 首页:
https://github.com/microsoft/playwright-cli
根据官方的基准测试,playwright CLI 比起传统的 playwright MCP 方案,差不多能够减少 4 倍的 TOKEN 消耗

工具搭建好以后,我们可以把很多固定的工作流程沉淀成 skills ,让 AI 能够又快又省的完成任务。甚至熟练后你会发现很多固定流程甚至不需要 AI 参与,只需要让 AI 编写好一个固定的脚本,就可以 0 TOKEN 全自动完成工作。好废话不多说,我们直接开始。
基础使用
在开始之前,我们需要先确保电脑上安装了 nodejs 。如果没有安装过,可以来到 nodejs 的官网,根据自己的操作系统下载对应的安装包
https://nodejs.org/en/download
然后我们打开一个命令行终端,输入这个命令安装 playwright CLI
。安装完成,下一步我们要确保电脑上安装了 Chrome 浏览器,如果是 edge 浏览器也可以,不过最好还是推荐使用 Chrome 。好这样准备工作就完成了。
我们来测试一下。我们可以使用这个命令,使用 Playwright CLI 操作 Chrome 浏览器打开谷歌的官网
playwright-cli open google.com --headed
最后一个参数–headed表示使用的是有头浏览器,如果不加这个参数,Playwright 默认使用的是无头浏览器。无头浏览器会在后台静默运行,虽然比较省内存,但是我们看不到浏览器的页面。所以为了方便调试,我们一般加上这个参数–headed 。回车,playwright CLI 自动操作 Chrome 打开了我们要的网页 。

我们在控制台这边可以看到,playwright CLI 只是输出了一简洁的网页摘要,而没有返回整个网页的全部 DOM 结构
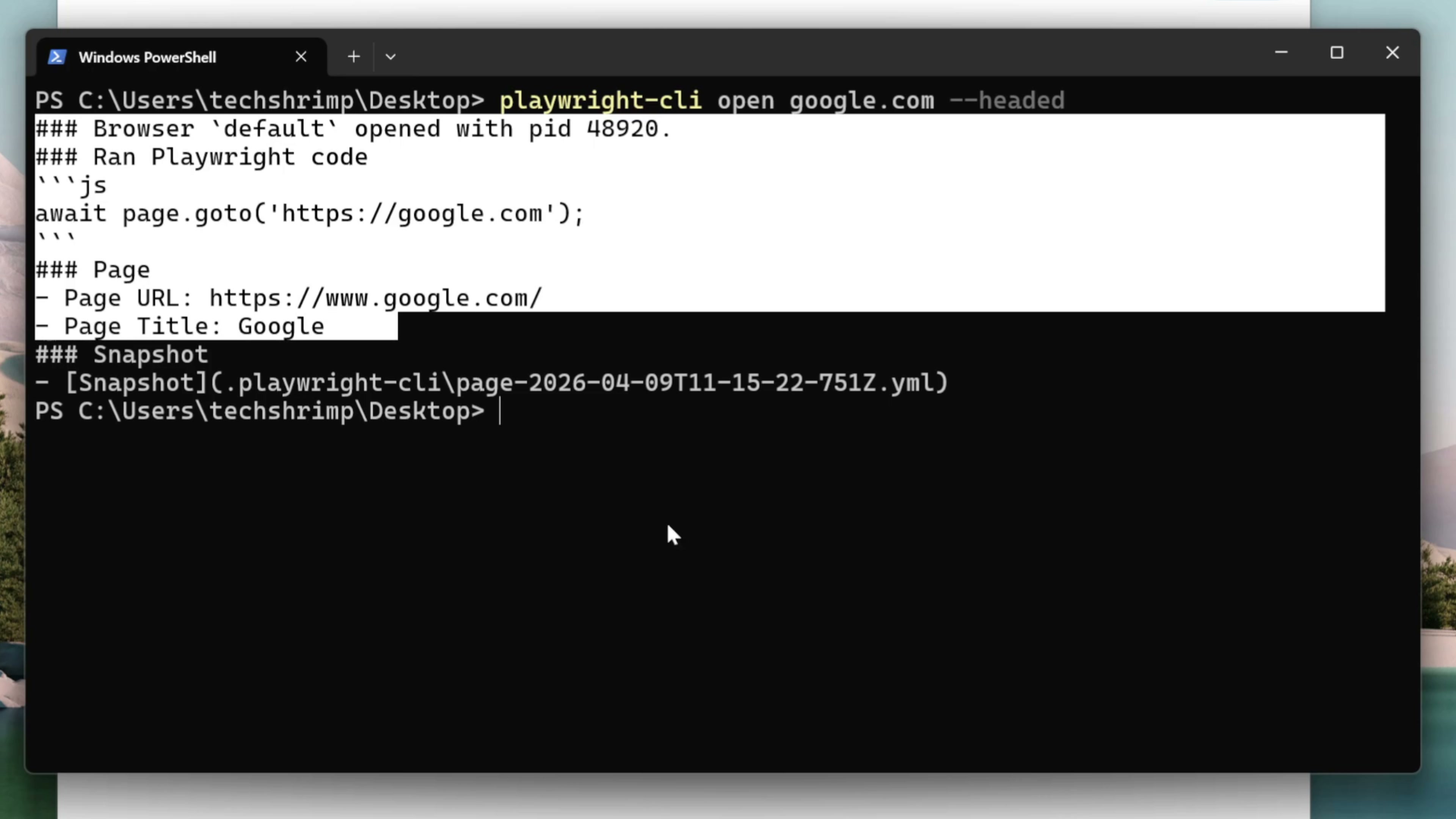
下面附带了一个网页结构的文件地址 。AI Agent 如果需要更详细的网页结构信息,就可以选择读取这个快照文件,获取更详细的信息。如果不需要,就可以选择不读取。这也就是为什么 Playwright CLI 比起 MCP 更节省上下文的秘密所在,因为 MCP 是把网页内容全部塞进上下文,而 Playwright CLI 可以由 AI 按需读取。同样这个命令也体现了按需加载的思路,
playwright-cli screenshot
Screenshot 是给浏览器截图,我们看到截屏的时候它还是以一个 PNG 的文件的形式存放在了电脑的本地磁盘上
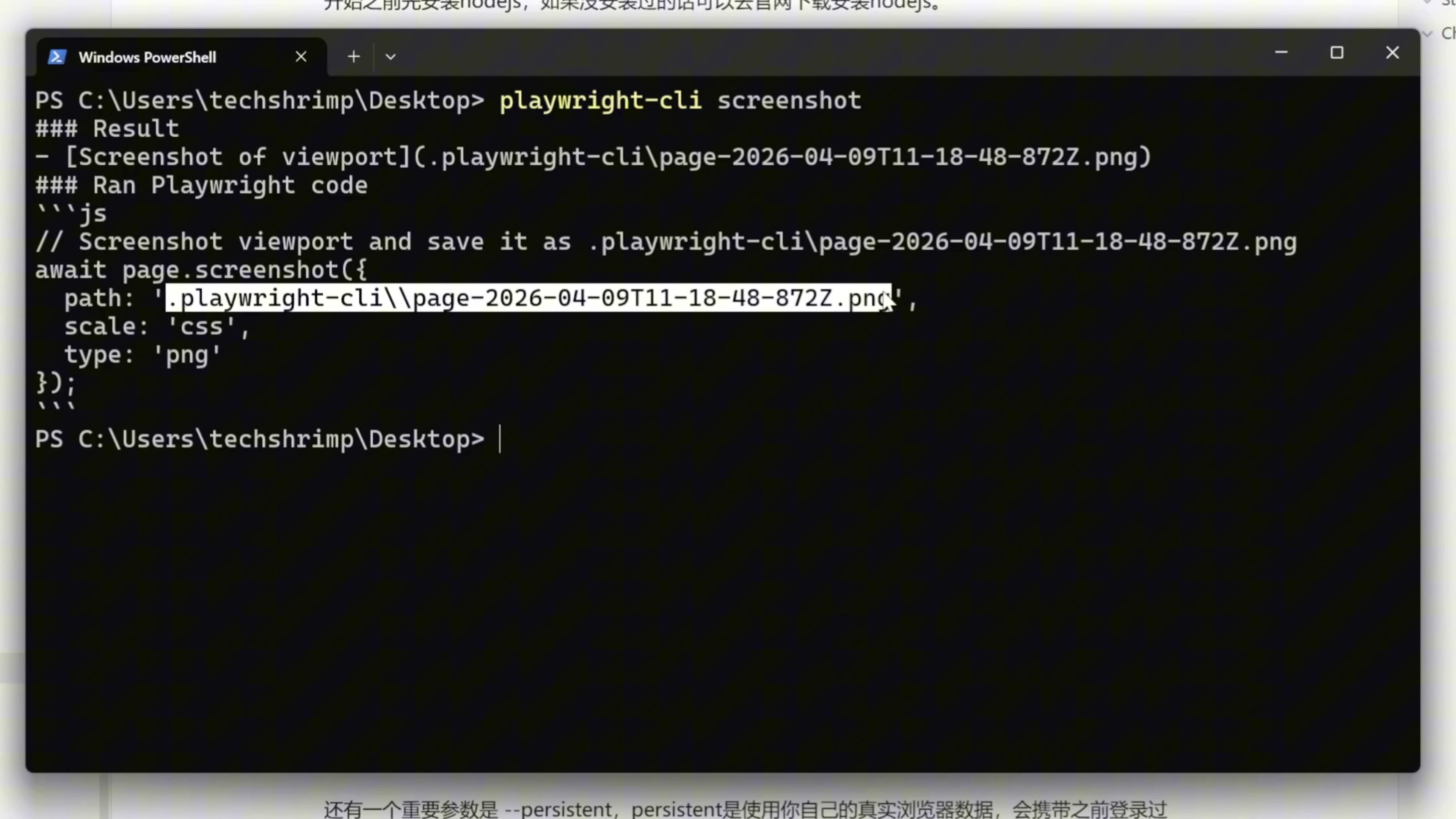
,由 AI 决定是否来读取,而不是像 MCP 那样直接把图片塞入 AI 的上下文。我们再介绍一个重要的参数,就是
--persistent。persistent 表示把 cookie 、登录状态、本地存储之类的数据写到磁盘里面,下次使用的时候继续拿出来用,这样就不需要每次都重新登录了。比如这里我带着 persistent 执行一下
playwright-cli open google.com --headed --persistent
,因为我之前登录过,我们打开的谷歌首页就变成了已经登录过的状态了
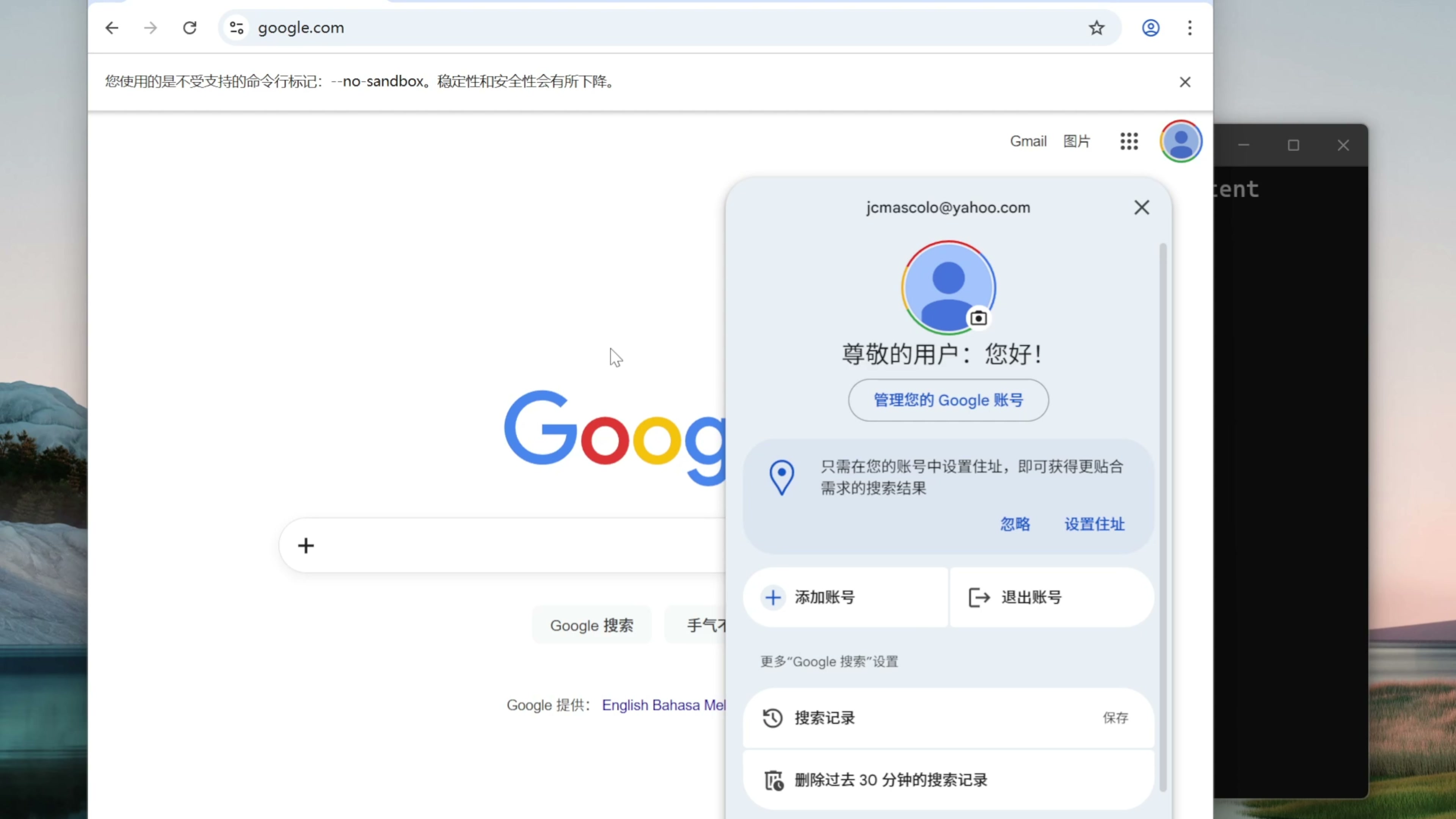
到这里我们就介绍完了 playwright CLI 的基础使用。下一步我们就把它接入 AI Agent 。
本期视频主要使用的 Agent 框架是 Claude code 和 Codex 。爬爬虾之前有很多期视频介绍 Codex 或者 Claude code 了,这里我就不赘述了 。playwright CLI 是一个新诞生的命令行工具,AI 并不知道该如何使用这些命令,所以我们需要给 AI 搭配 skills 来一起使用。

Playright CLI 作为技术底座,而 skills 作为说明文档,CLI 加 skills 搭配起来使用,就可以取代传统的 MCP 方式,这也是最近的一个技术发展趋势。我们先新建一个项目文件夹,打开这个文件夹,打开命令行终端,我们直接输入这个命令给文件夹里面安装 skills
playwright-cli install --skills
这样 skills 就安装完成了,它放到了我们新建的项目文件夹的目录下面 。然后我们就可以启动 Claude Code ,我来询问它你有哪些 skills ,它可以成功的读取到 playwright CLI 技能,这样我们就成功的把它接入了 Claude code
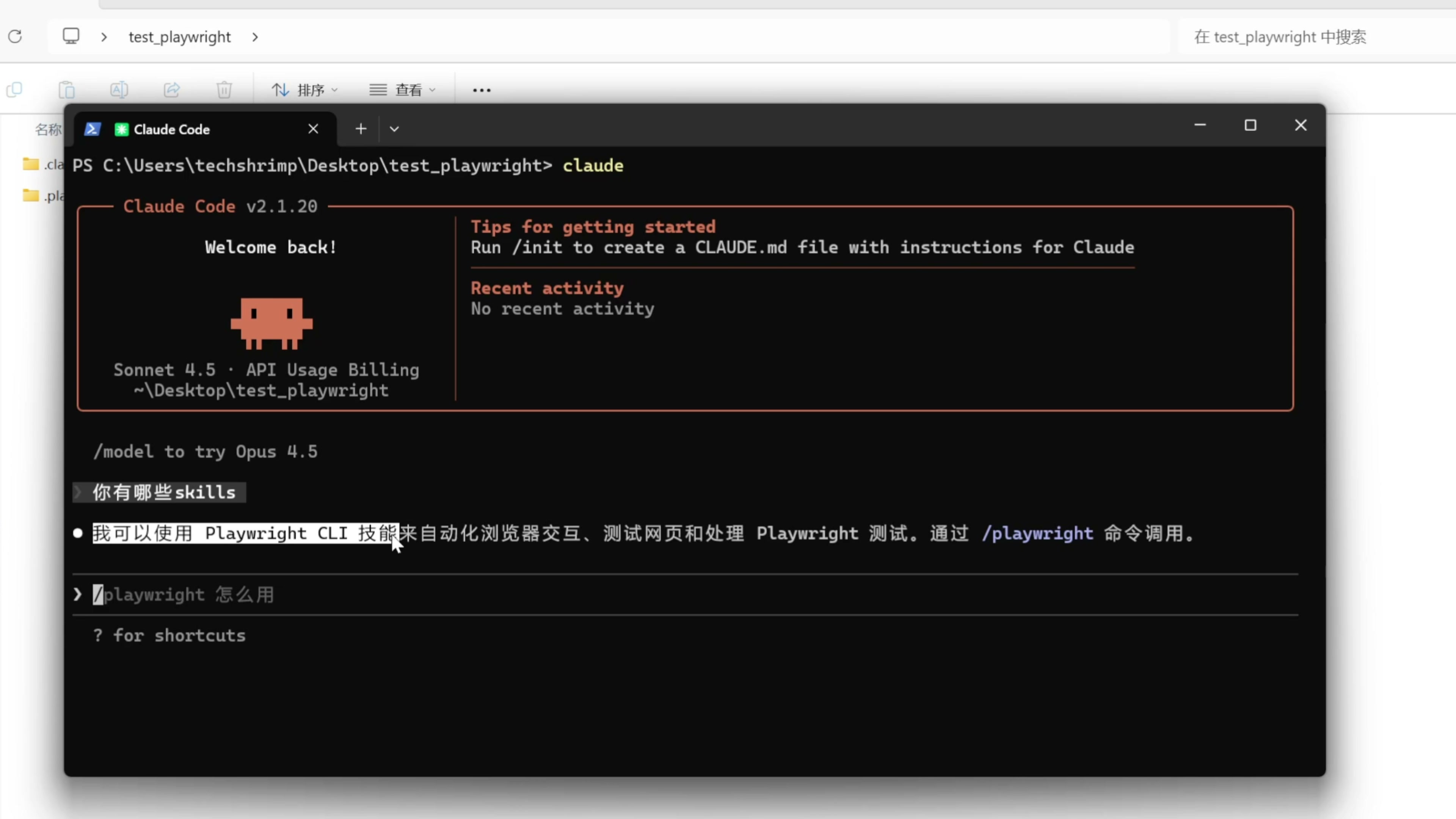
。接下来我们来看另外一个 Agent 的框架,就是 Codex 。我们只需要在项目目录里面,把存放 skills 文件夹的名字从.claude 改成.codex ,来适配 Codex 、
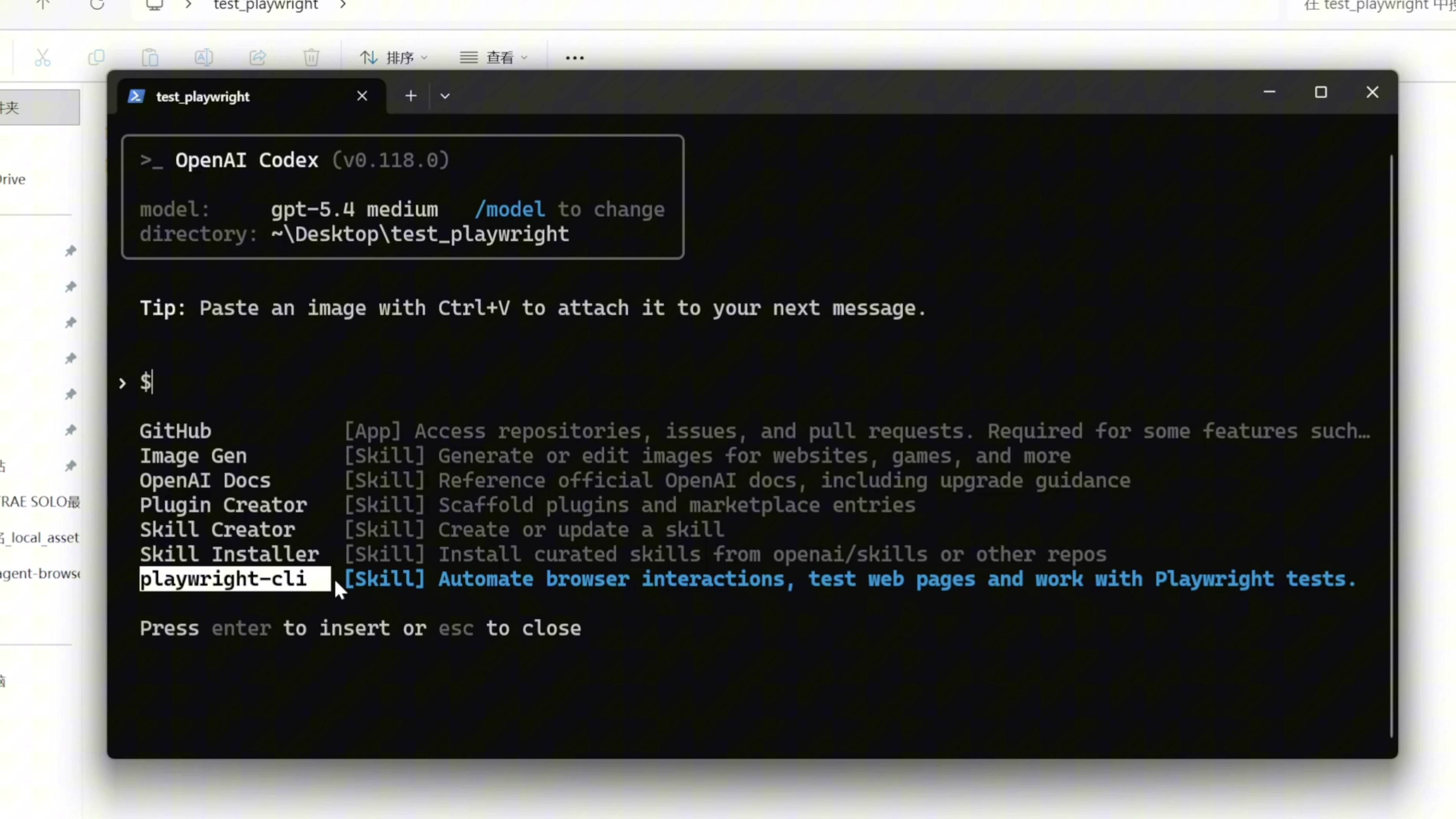
然后我们还是在这个目录里面打开 Codex ,在 Codex 里面可以输入命令/skills ,我们看到这里列出了 playwright CLI ,在 Codex 里面也配置完成了
我们在 Codex 里面测试一下基础用法,我让它使用 playwright CLI 加上这两个参数打开 Grok ,问问今天青岛的天气怎么样
。AI 成功的打开了浏览器,来到了 Grok 的首页,帮我们自动输入了问题,自动点击了回车,拿到了结果,最终成功打印到了控制台上,任务就完成了 。
进阶实战
我们来看一个复杂一些的例子,使用 playwright CLI 查看这个商品前 100 条评论,然后保存到一个 CSV 文件里面
我们看到 AI 还是先学习 playwright cli 技能,然后打开了商品页。第一次运行总是磕磕绊绊的,不过没关系,我们让它自己探索,自己寻找解决思路。AI 尝试了很多方案,也浪费了不少 TOKEN ,我们看到这里显示用掉了 41%的上下文窗口,最后成功完成了任务,帮我们获取到了这个 CSV 文件,成功抓取到了这么 100 条数据
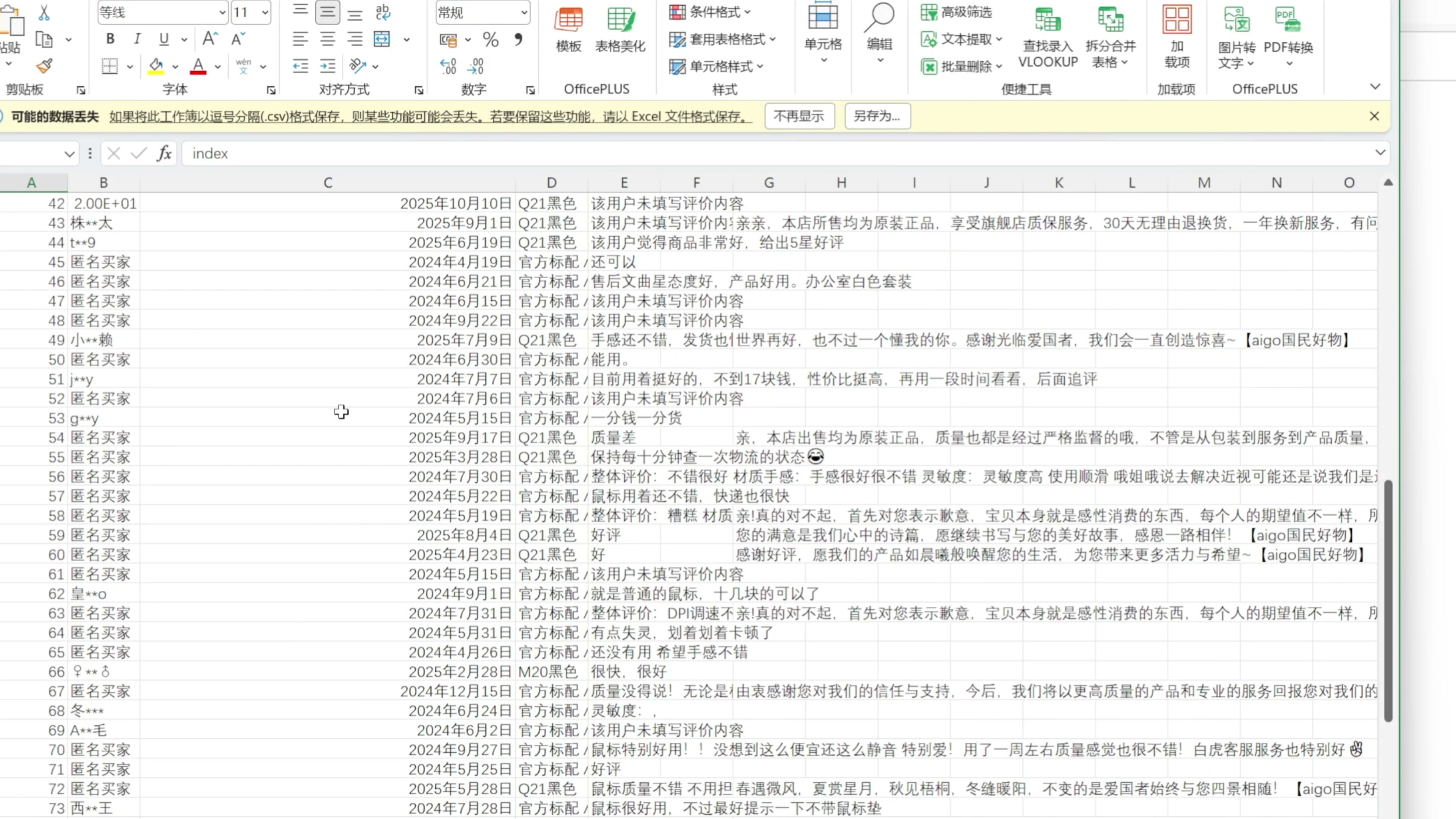
我们有两种方式可以把这个流程总结并且保存下来,让它下一次执行变得更加丝滑,更加省 TOKEN 。我们先来看第一个方式,就是把这个过程保存成一个 skill 。这里输入提示词
创建一个新的 skill ,把刚才打开网站,查看评论,并且保存评论的全过程,还有遇到的坑都提炼出来,保存到这个 skills 里面,后面我只要让你保存评论,你就能调用这个 skill 完成任务。AI 帮我们创建了 skill ,
AI 帮我们创建了 skill ,把这个任务里面可以复用的内容都固化进了知识。这里我让他修改一下,把 skill 放到项目目录里面
skill 成功放到了项目目录下面,现在我们有两个 skill 了,一个是 playwright CLI ,还有一个就是刚才保存评论那个流程的 skill 。这里我先清理一下上下文,我们再用相同的任务来测试一下
有了 skills 的指导以后,效果就不一样了。AI 充分吸取了之前的经验,没有再出现多余的动作,也没有报错,用最低的 TOKEN 消耗,完美的完成了任务
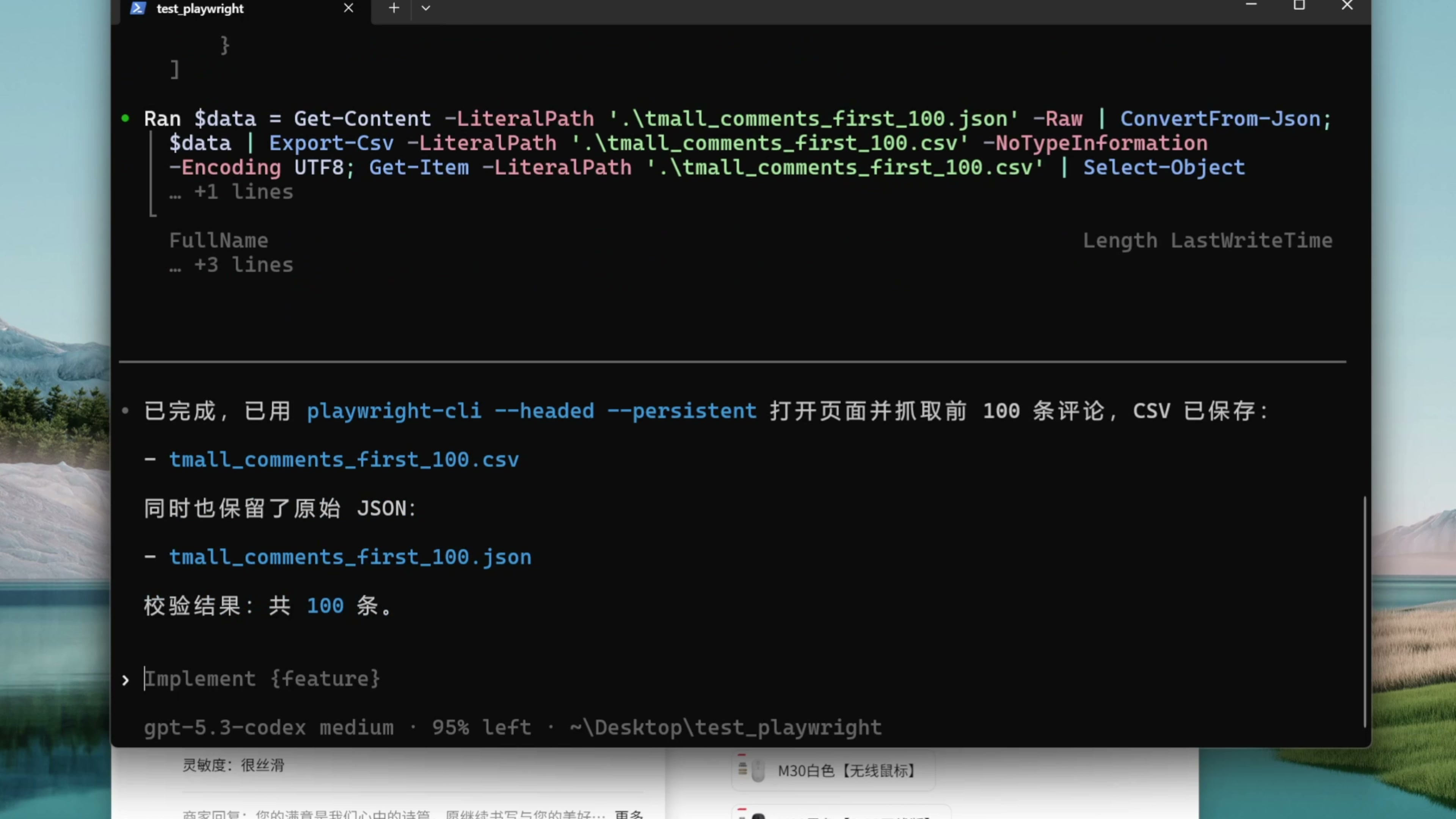
我们第一次让 AI 自己摸索,自己试错,用了 41%的上下文才完成了任务,第二次有了 skills 的指导,只用了 5%的上下文就完成了任务
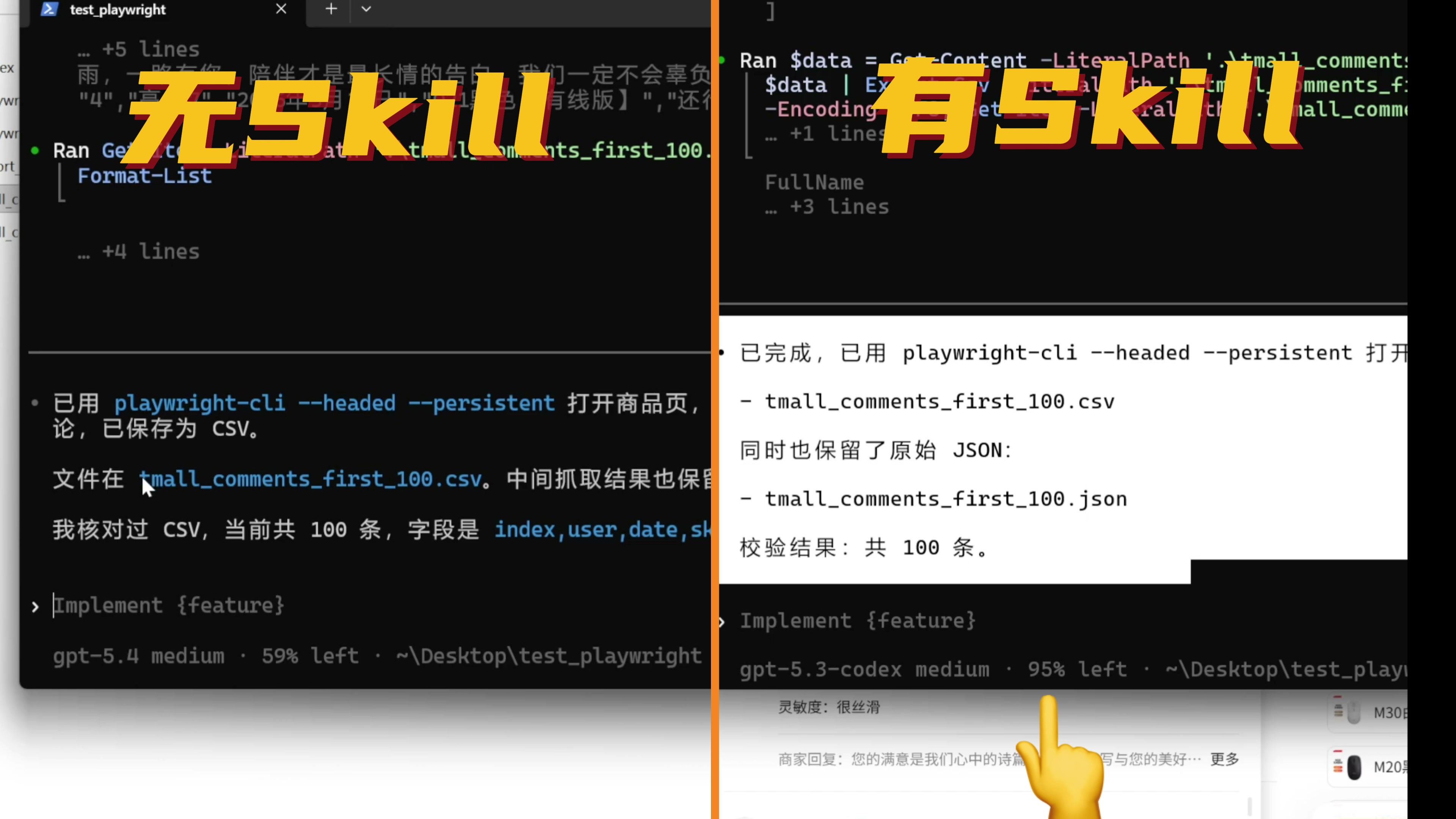
通过把过程提炼总结成 skills ,获得了将近 10 倍的效率提升。
抓取评论是一个固定流程,其实并不需要 AI 进行智能化的控制。我们可以直接把它编写成一个固定的脚本。这里输入提示词
你把刚才所有的 playwright cli 命令汇总成一个脚本,执行脚本就能获取商品的前 100 条评论,并且保存到一个 CSV 文件里面。注意每一步都要有合理的延时与等待,确保任务成功。脚本写完你先测试一轮。
很快 Codex 为我们编写完成了脚本,它已经自己测试通过了。我们来看一下这个脚本长什么样 在我这个 Windows 电脑上就是这么一个 Powershell 的脚本
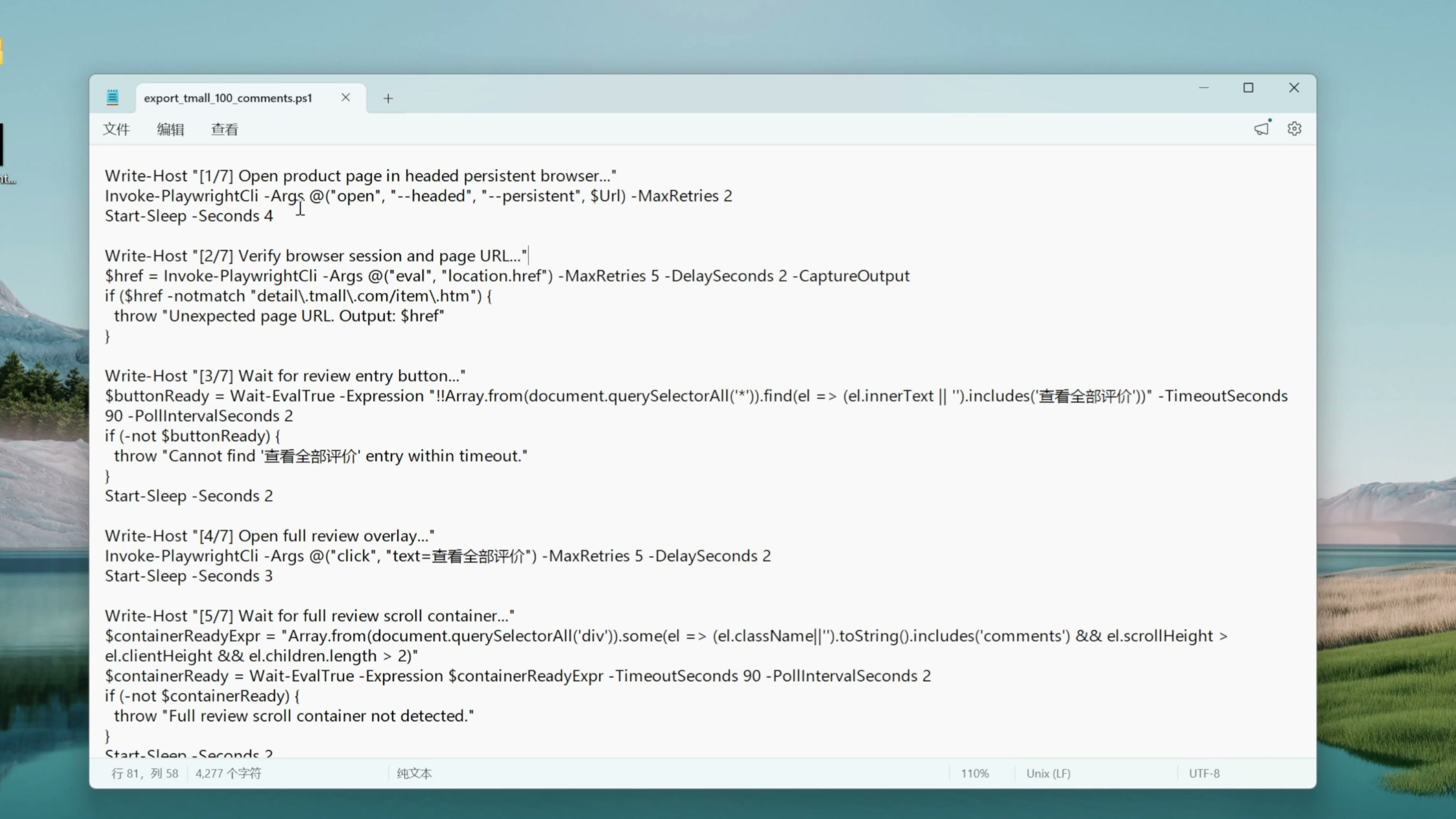
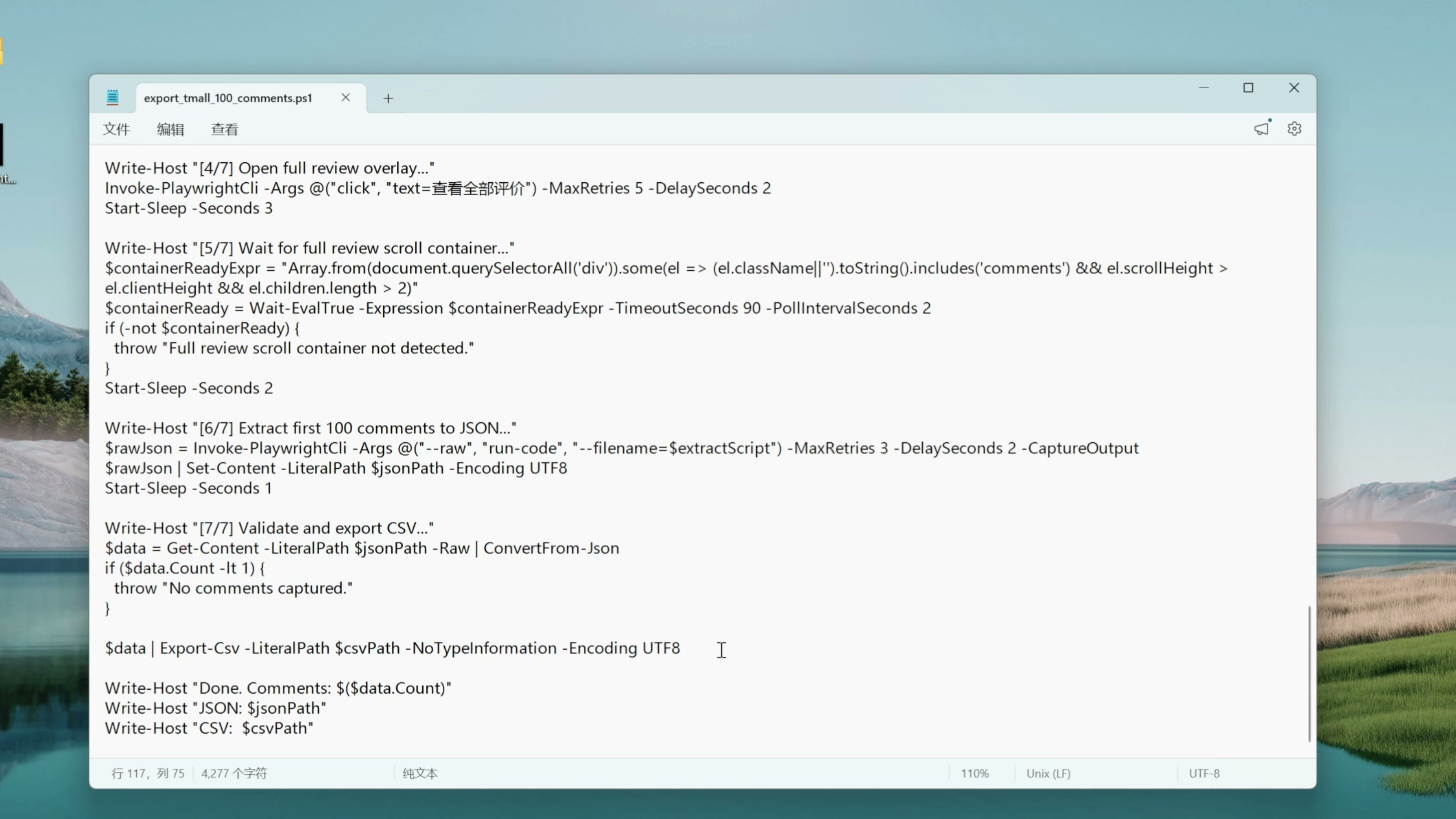
AI 以编程的方式把刚才的步骤都固定下来了。比如第一步打开商品页面,第 2 步确认浏览器里打开的是正确的 URL ,第四步点击查看全部评价按钮,第六步执行这个 JS 脚本获取评论,最后一步把刚才的 JSON 数据保存成一个 CSV 文件。
我们也来测试一下。我们打开一个命令行终端,输入这个 Powershell 脚本的路径,回车执行
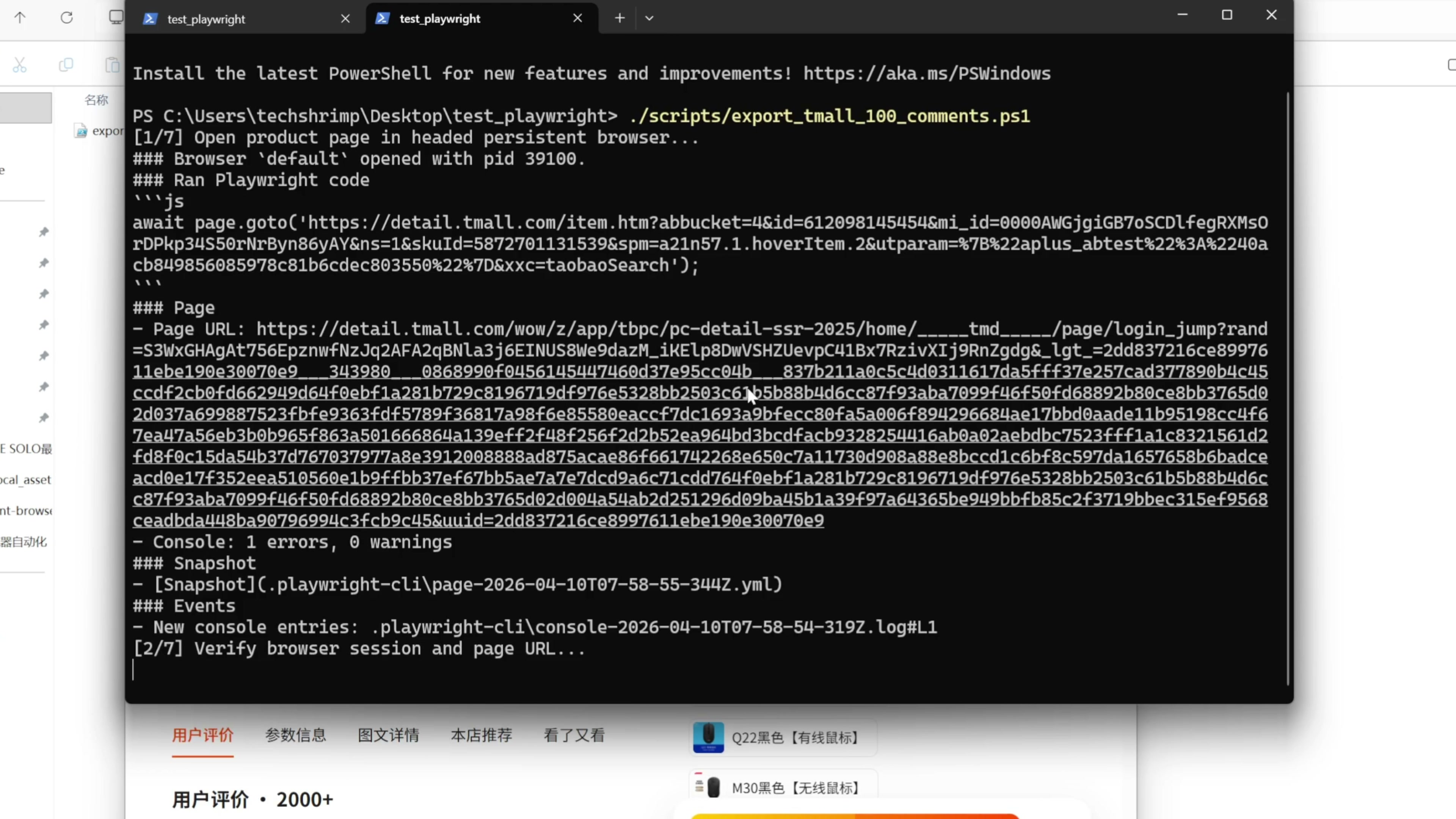
这是一个固定的流程,中间没有 AI 的参与。我们看到这次不再依赖 Codex 了,直接执行这个 Powershell 脚本 0TOKEN ,0 成本就完成了任务,还取得了相同的效果
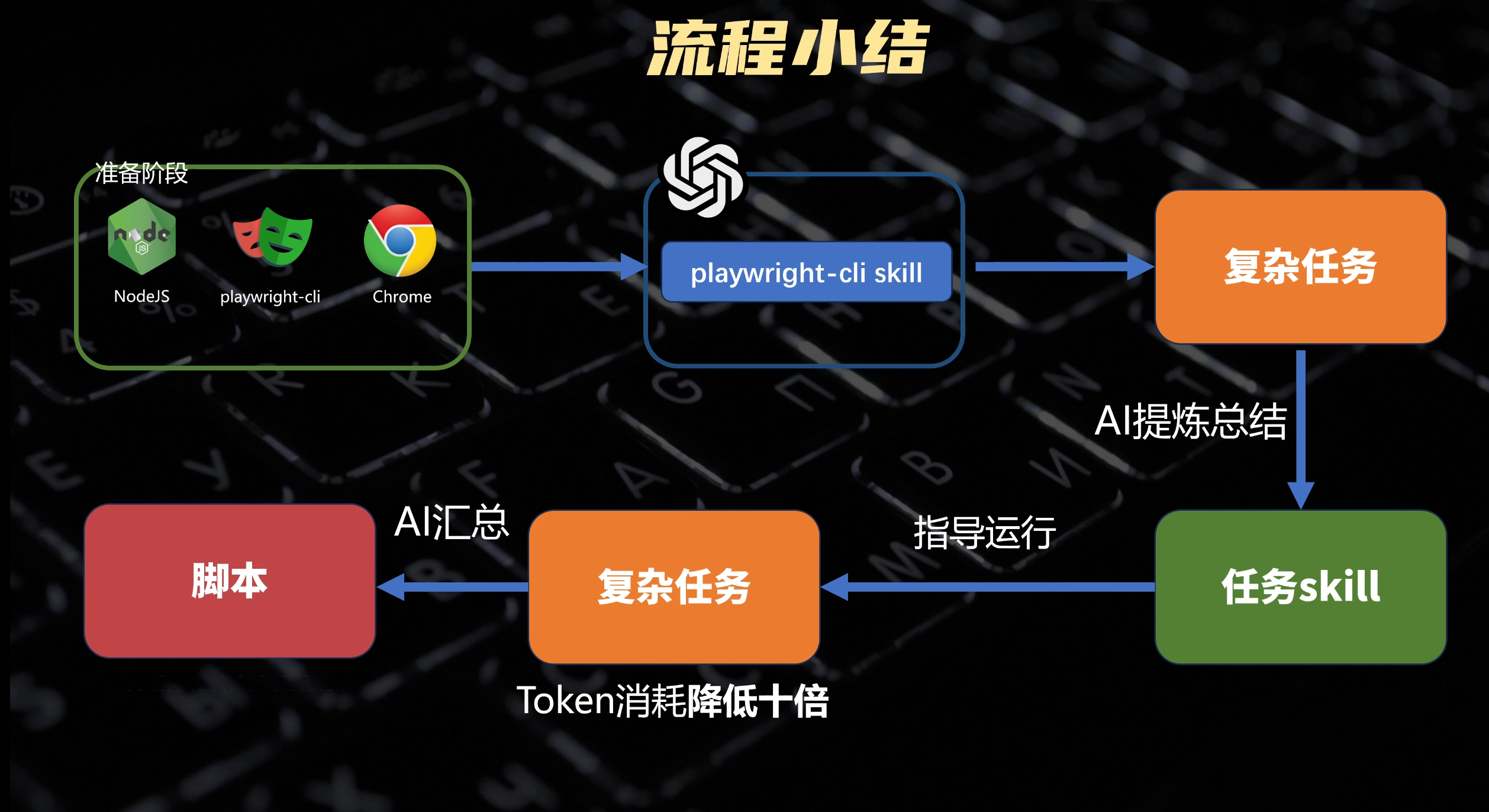
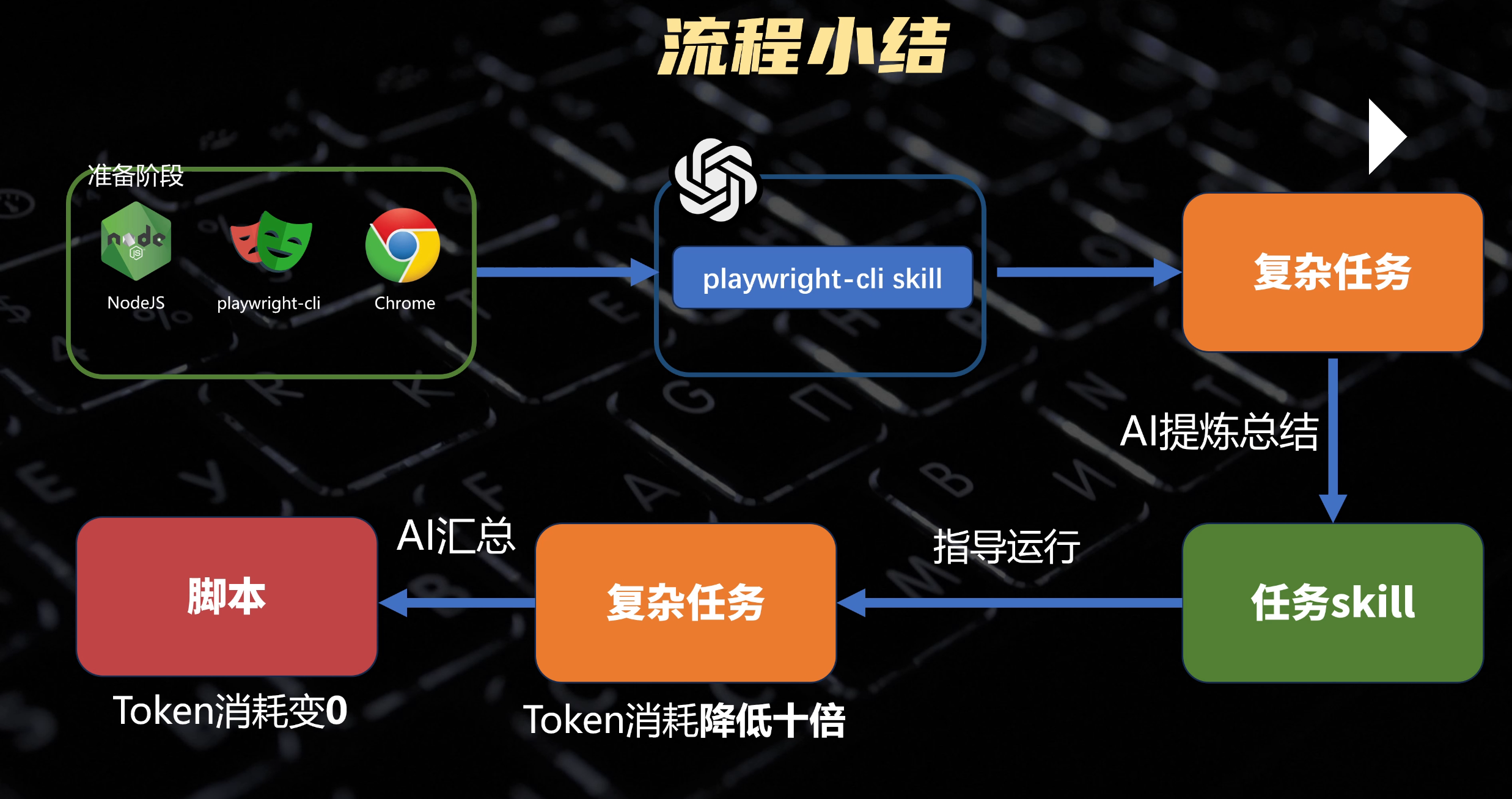
好我们来总结一下这套浏览器自动化的流程 。在准备阶段,我们先安装 nodejs ,playwright CLI 还有 Chrome 浏览器。第二步选择你喜爱的 AI Agent 工具,把 playwright CLI 的 skill 安装进去。第三步给 AI 一个复杂的任务,让它自己摸索并且执行完。第四步让 AI 把刚才的执行结果提炼总结成 skill ,之前遇到的坑就不要再踩了。第五步重试相同的任务,AI 在 skills 的指导下可以把 TOKEN 的消耗降低 10 倍。如果是完全固定化的流程,还可以继续进行第六步,让 AI 把这个过程直接编写成一个脚本。有了脚本以后,我们甚至可以直接执行这个脚本,完成任务,完全不需要 AI 参与,把 TOKEN 消耗直接降低到了 0 。
自动发文
我们再来看一个实战案例。最近爬爬虾把自己的视频用 AI 转成图文教程,然后发到各个平台上面。大部分平台发文章都比较简单,唯独有一个平台 X ,发文章的步骤非常的繁琐。这是我的一个 Markdown 格式的笔记文章 我们注意到这个文章是不能直接以 Markdown 格式粘贴过来的,首先这个格式会错乱,第二个问题是图片都展示不出来。然后我又测试了一下,如果使用 html 格式是可以粘贴的,但是又出现了一个新的问题,图片是粘贴不过来的,图片都变成了这么一个照相机的小符号
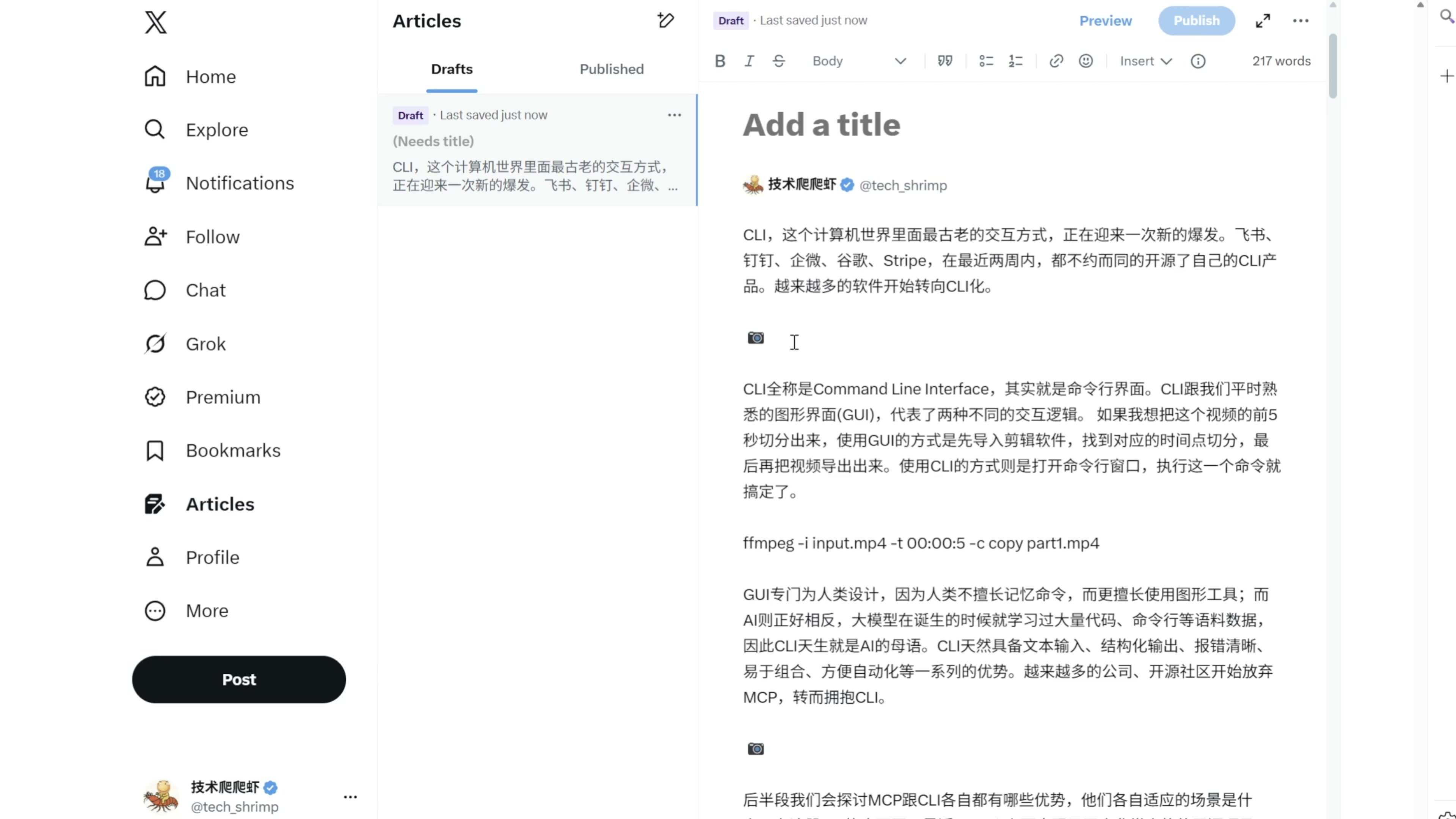
我们只能手动先把小照相机删除,然后把图片复制一下,一张张的手动粘贴过来,非常的麻烦。接下来我们就使用前面介绍的自动化流程,把这个发文章的全过程进行 AI 自动化。这里我还是使用 Codex ,
帮我编写一个 Python 脚本,把文章里的图片下载到本地,从 001 开始编号,放到这个文件夹里面,先转换成一个只使用本地图片的 Markdown 文章,然后运行 pandoc 把本地图片的 Markdown 文章转换成 html 格式。注意 html 格式里面每张图都应该是独立段落。
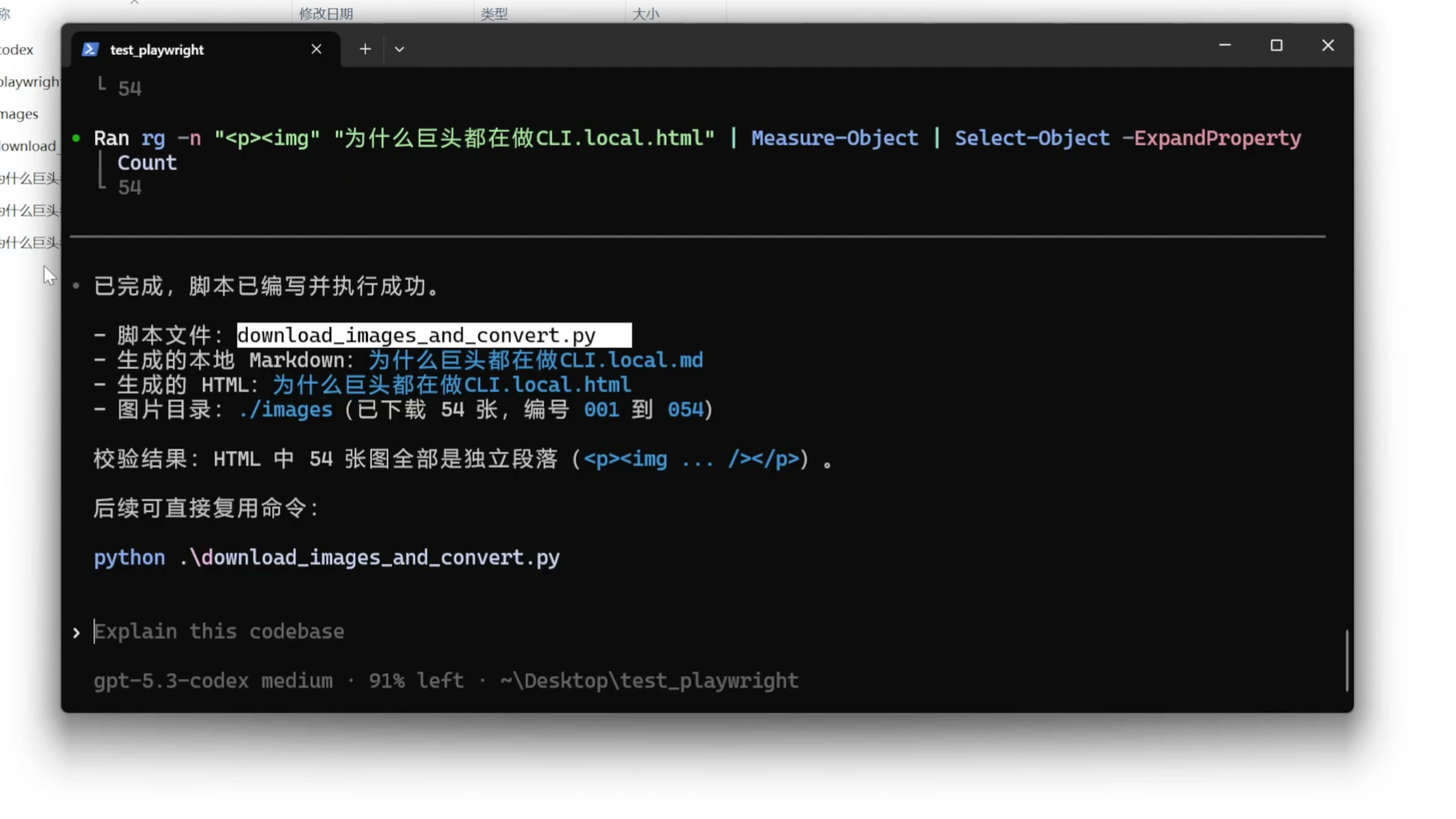
开始 AI 帮我们编写好了脚本,并且为我们转换好了文章,我们来看一下。图片都放到了这个 images 文件夹下面,而且已经把文章转换成了 html 格式的
好下一步我们就可以让 AI 来帮我们自动发文了。我们输入提示词
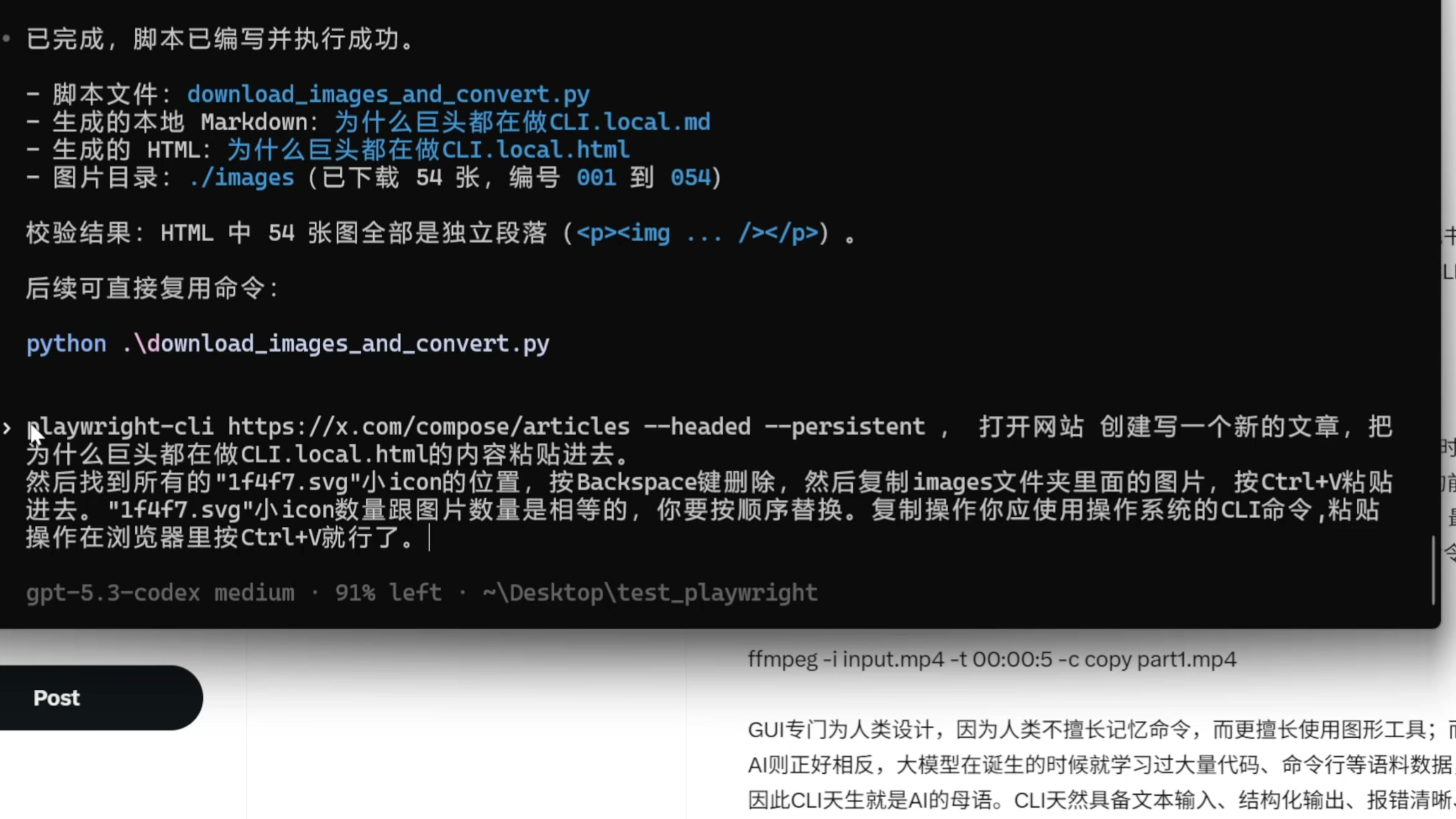
使用 playwright CLI ,先打开这个网站,创建一个新的文章,然后把这个 html 的内容粘贴进去,找到所有的这种照相机的这种小图标的位置,先按退格键删除掉小图标,然后在图片文件夹里面找到图片,先复制出来,按 Ctrl+V ,再粘贴进去。这个小 icon 的数量跟图片的数量是相等的,我需要它按顺序替换。
好我们开始。AI 为我们打开了浏览器,创建了一个新的草稿,把 html 格式的文章粘贴进去了,然后它开始为我们一张张的上传图片,把原来的占位符删除掉,然后一张张的替换成真正的图片。我们看到它正在一张张的帮我们自动化的替换,整个过程非常的顺利。

我让 AI 把从头开始的全流程整理成一个 skill ,然后放到项目目录,以后我只要给你一个文章,就能自动发布。AI 帮我们固化了一个 skill 。AI 为我们编写好了技能,生成了这些配套的脚本
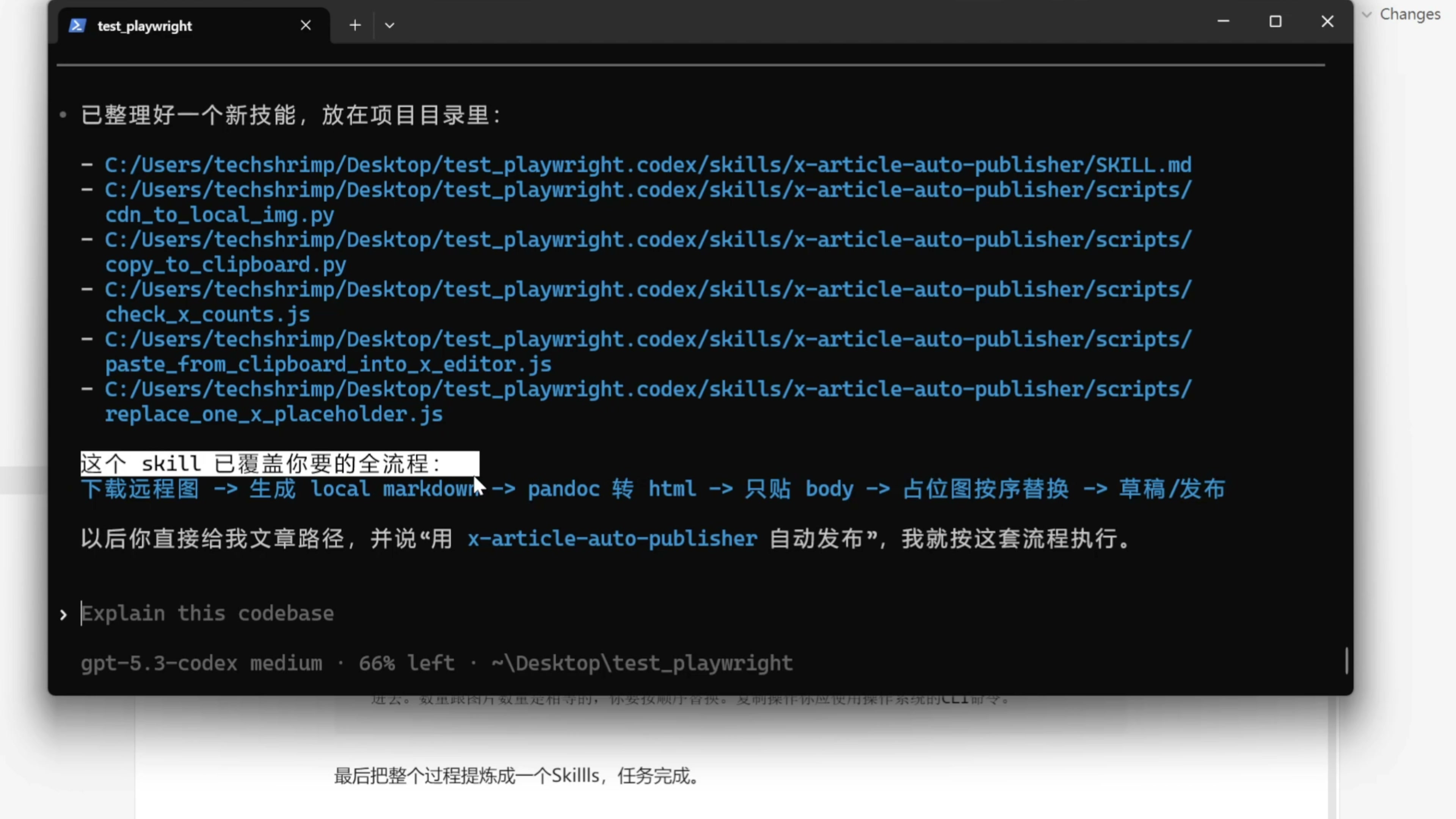
然后这个 skills 就可以覆盖自动发稿的全流程。以后我只要给他一个文章路径,告诉他使用这个 skill 自动发布,它就能自动的帮我把这个文章发布上去,非常的棒
这个 skill 的源代码我已经上传到了 Github 的这个仓库下面
https://github.com/tech-shrimp/x-article-auto-publisher-skill
感兴趣的观众朋友们,可以来参考试一下。不过我这个是 Windows 电脑的,如果是其他操作系统,可以让 AI 参考这个 skill 来改一下。相信按照我这套流程,大家都可以编写出属于自己的 skill 。
AI 自动化测试
我们这套浏览器自动化流程,一个重要的应用就是对自己写的 Web APP 进行自动化测试。比如这里我开发了一个简历润色美化的网页 APP
。接下来我输入指令
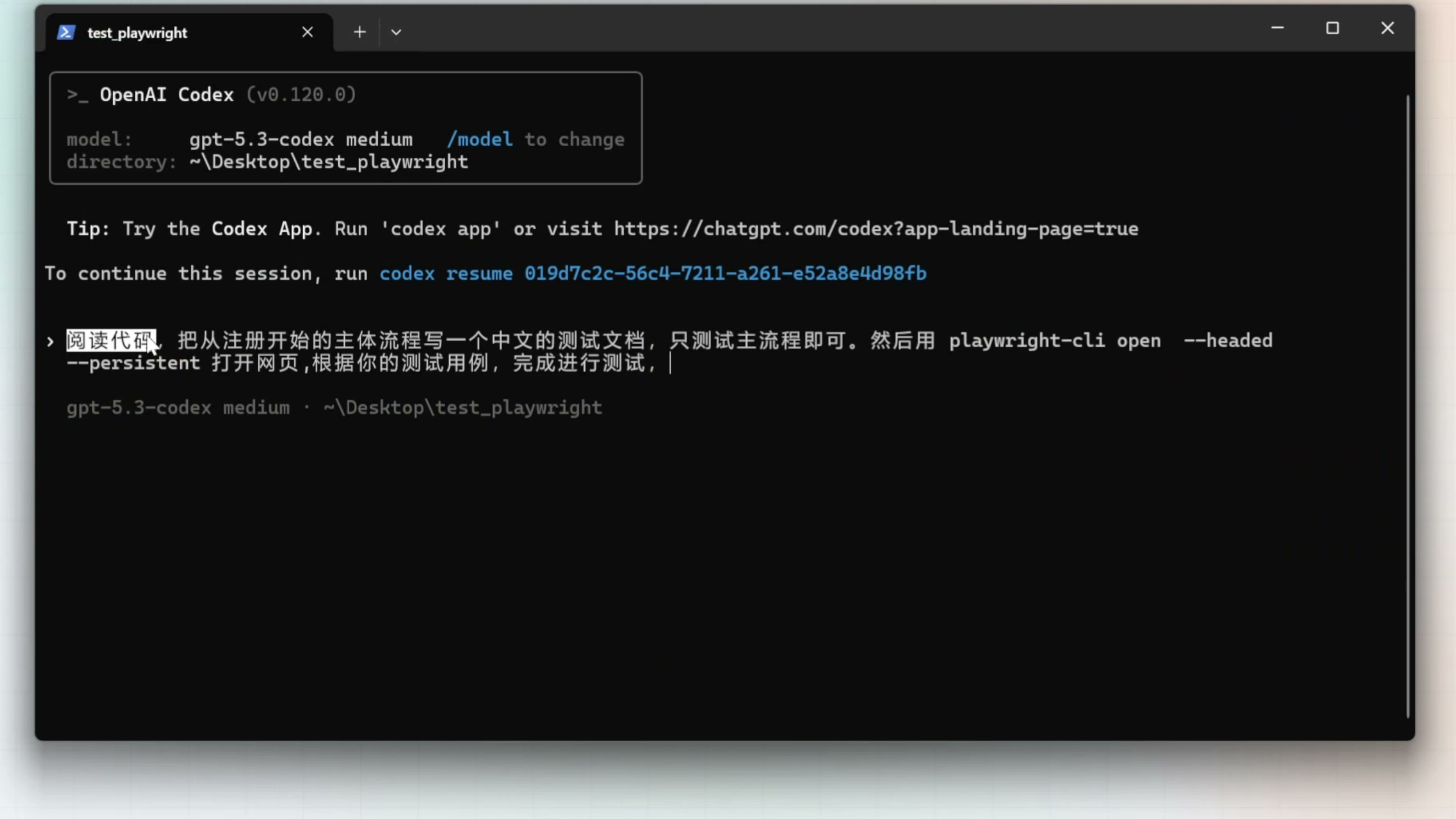
阅读代码,把从注册开始的主体流程写一个中文的测试文档,然后再用 playwright CLI 打开网页,根据你的测试用例完成测试。
AI 通过阅读代码学习到了这个项目的功能,然后确认了主体流程。接下来它开始编写测试文档。测试文档编写好了,这里包含第一步做什么,第二步做什么,第三步做什么
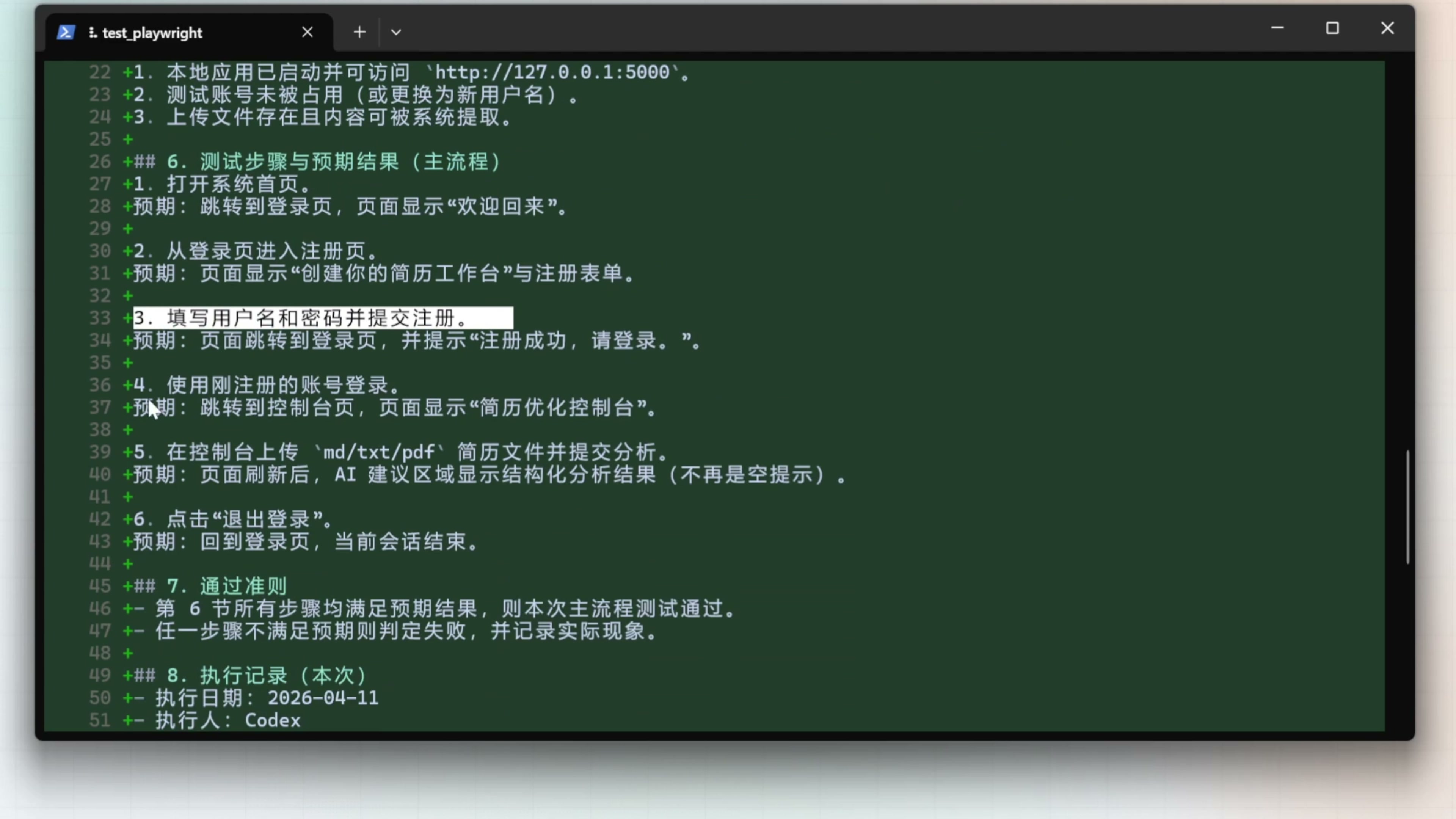
然后 AI 使用 Playright CLI 打开了浏览器,它自动点击了注册按钮,创建了测试账号,完成了登录。它创建了一份测试简历,并且上传上来了,完成了主体流程的测试。测试结论是通过 。
我们也可以要求 AI 编写更多的测试用例,使用 playwright CLI 进行全自动的测试。还可以使用 OpenClaw 这种带定时任务的 Agent 框架,让它定时对我们的系统进行测试。一旦我们修改出来了 bug ,AI 就能全自动的发现并且告诉我们,省去了很多的人工测试成本,对我们开发网页 APP 会很有帮助。好这就是本期视频全部内容了,感谢大家点赞支持,我们下期再见。
