把 OpenClaw 技能库“一次看全、一次看透”的技能分类分析工具。
skill-taxonomy 用来扫描整套 skill 目录,自动识别技能所处的架构层级,梳理依赖关系,发现路由冲突、能力重复和抽象缺失,并最终生成一份可交互的 HTML 分析报告,帮助你快速看清整个技能系统的结构健康度。
它输出的报告主要包含两部分:
这个仓库被单独开源出来,是为了让这套 taxonomy 分析流程可以脱离私有工作区,独立复用、持续迭代,也方便团队协作和社区共建。
效果预览
Graph 视图
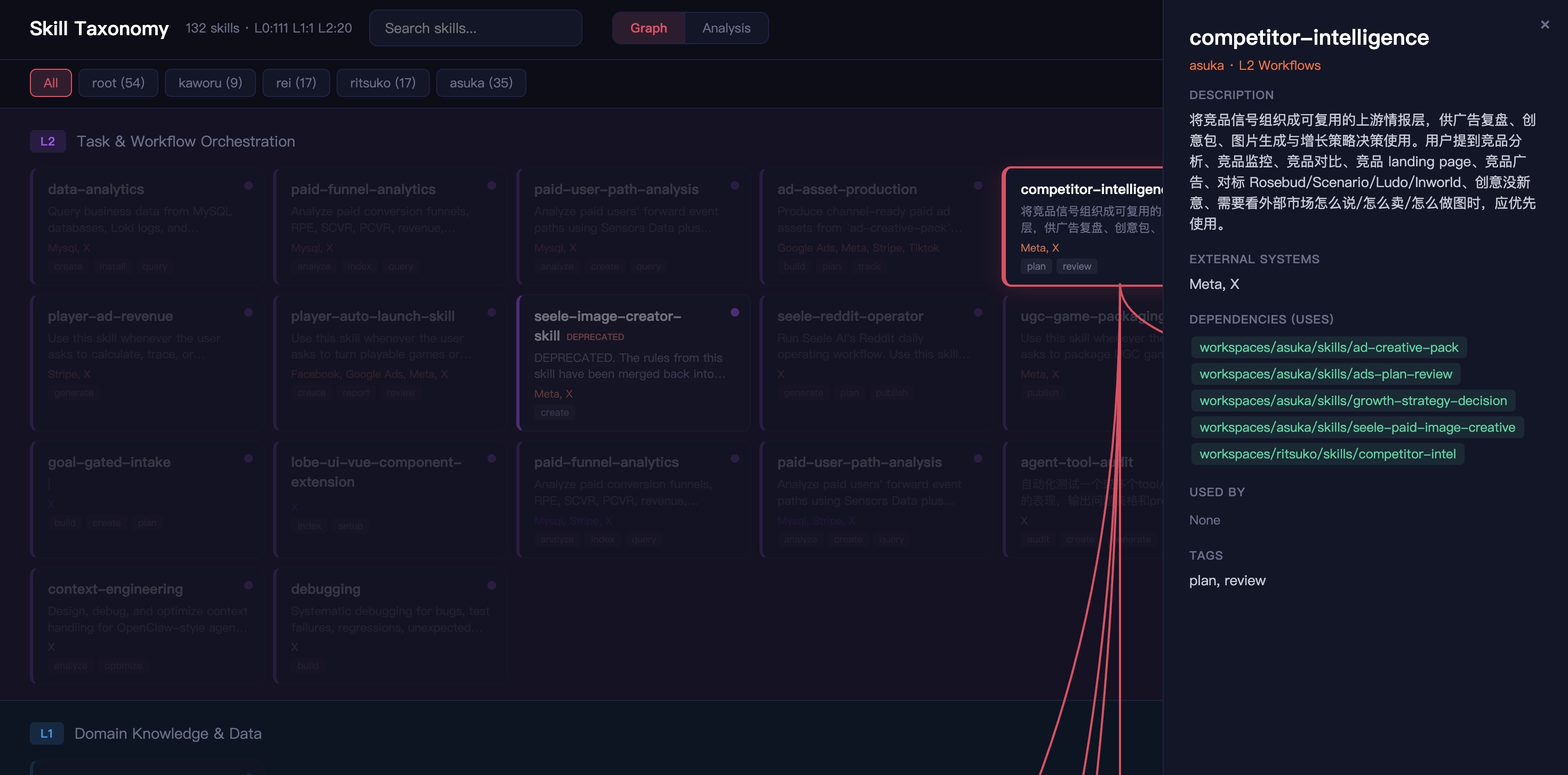
Analysis 视图
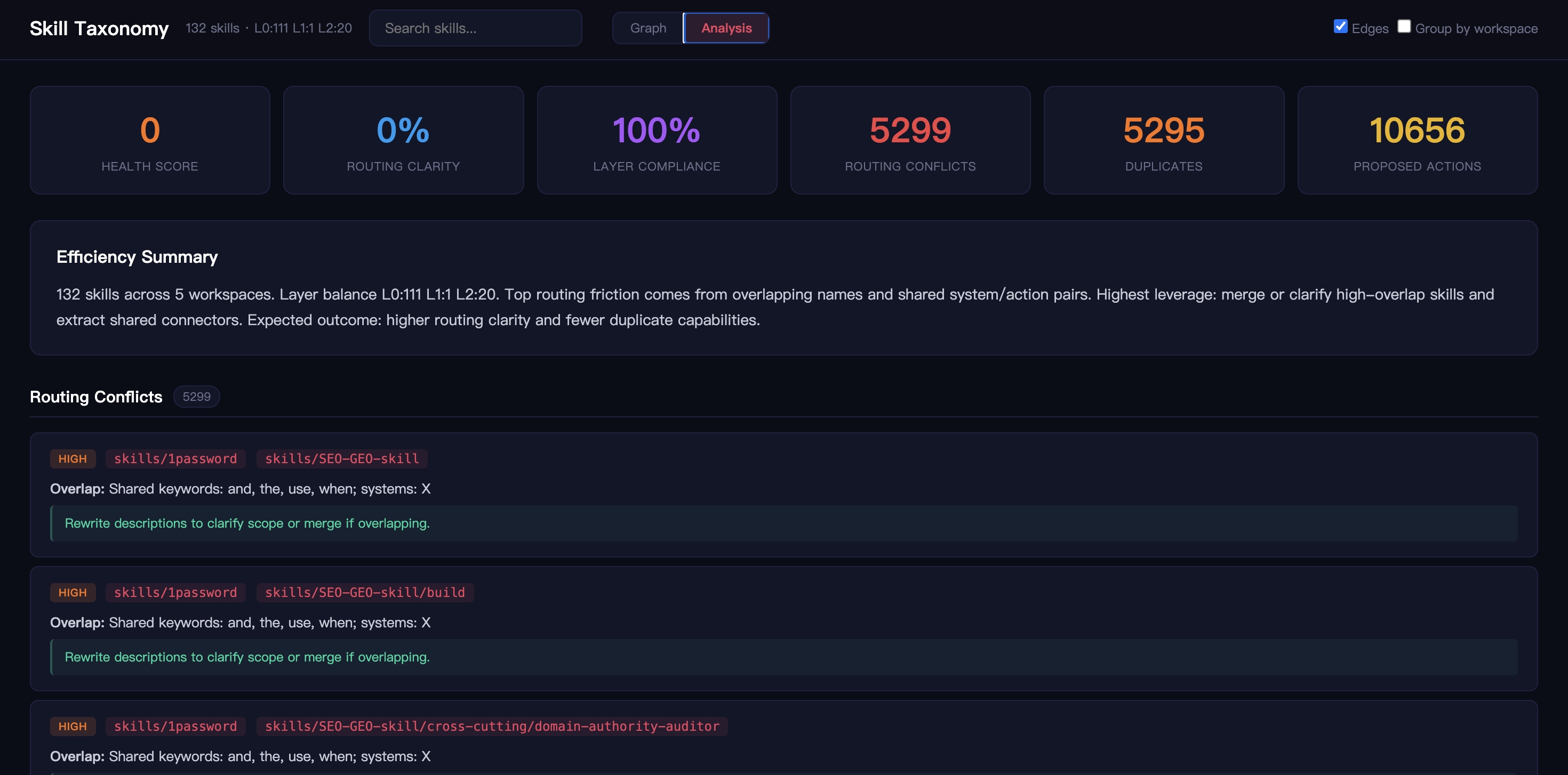
为什么需要这个仓库
随着 skill 数量不断增长,系统的“可维护性”和“可路由性”通常会先变差,但团队往往很晚才意识到问题。常见症状包括:
skill-taxonomy 的价值,就是把这些平时不易察觉的结构问题,一次性可视化出来。
它不再只是给你一个平铺的文件夹列表,而是给你一个“技能系统结构图”,让你能快速回答下面这些关键问题:
它会产出什么
整个流程会生成两类核心产物:
[ol]
[/ol]
其中,HTML 报告默认包含以下能力:
分层模型
taxonomy 使用三层架构模型:
通用能力层,负责基础设施、外部系统接入与底层通道能力
领域知识层,负责行业规则、指标体系、结构化检索与数据转换
任务编排层,负责把多个步骤串起来,完成端到端交付
这套分层不仅用于可视化展示,也会被用于检测架构违规,例如高层是否直接越层依赖底层实现、某些 skill 是否放错层级等。
仓库结构
skill-taxonomy/
├─ README.md
├─ LICENSE
├─ .gitignore
├─ SKILL.md
└─ scripts/
└─ generate_graph.py
工作流程
核心分析流程定义在 SKILL.md 中,整体步骤如下:
[ol]
[/ol]
快速开始
1. 准备分析 JSON
按照 SKILL.md 中定义的流程,先生成一个类似下面格式的 JSON 文件:
{
"skills": [],
"analysis": {
"metrics": {
"health_score": 0,
"routing_clarity": "0%",
"layer_compliance": "0%"
}
}
}
保存到:
/tmp/skill-taxonomy-data.json
2. 生成交互式报告
python3 scripts/generate_graph.py \
--input /tmp/skill-taxonomy-data.json \
--output /tmp/skill-taxonomy-graph.html
3. 打开报告查看结果
open /tmp/skill-taxonomy-graph.html
脚本会做什么
scripts/generate_graph.py 负责:
脚本本身足够轻量,只依赖 Python 标准库,便于本地快速运行和二次改造。
适合用在什么场景
当你遇到以下情况时,这个仓库会很有价值:
它不是什么
为了避免误解,需要明确几点:
更准确地说,它是一套面向 skill 系统治理的“分析与决策辅助工具”。
校验方式
本地可先做基础校验:
python3 -m py_compile scripts/generate_graph.py
关于 Seele
该仓库由 SeeleAI 发布,是其开源 agent 工作流与 skill-system 工具链的一部分。
开源协议
MIT
