[ol]
[/ol]
模型具体情况: 目前训练了 8b 和 14b 两个参数的模型,共使用 8xH100 全量微调约 2 天。底模是 Sakura-Qwen3-Base ,在此感谢 sakura 和 qwen 的贡献为本工作节省了大量 PT 和 CPT 的时间。
模型的具体效果, 可以参考我们在这里的测试,使用 COMET (wmt22-comet-da) 指标测试了共 200 个段落级别的数据,效果优于 Gemini3.0pro 以及 claude4.5opus 等 sota 闭源商业模型。用户的反馈结果和实际检查下来也很不错,在 ACGN 领域有着很强的翻译效果,并且还有一点,没有审查,可以翻译某些不可言说的东西()
我会放一段具体的翻译结果对比到评论区供大家参考。
(免费的 GPU ,可用性不能保障,推荐优先本地测试)
然后再简单介绍一下针对翻译模型适配开发的推理前端。(虽说是针对本模型设计但是现在功能已经很全面了)
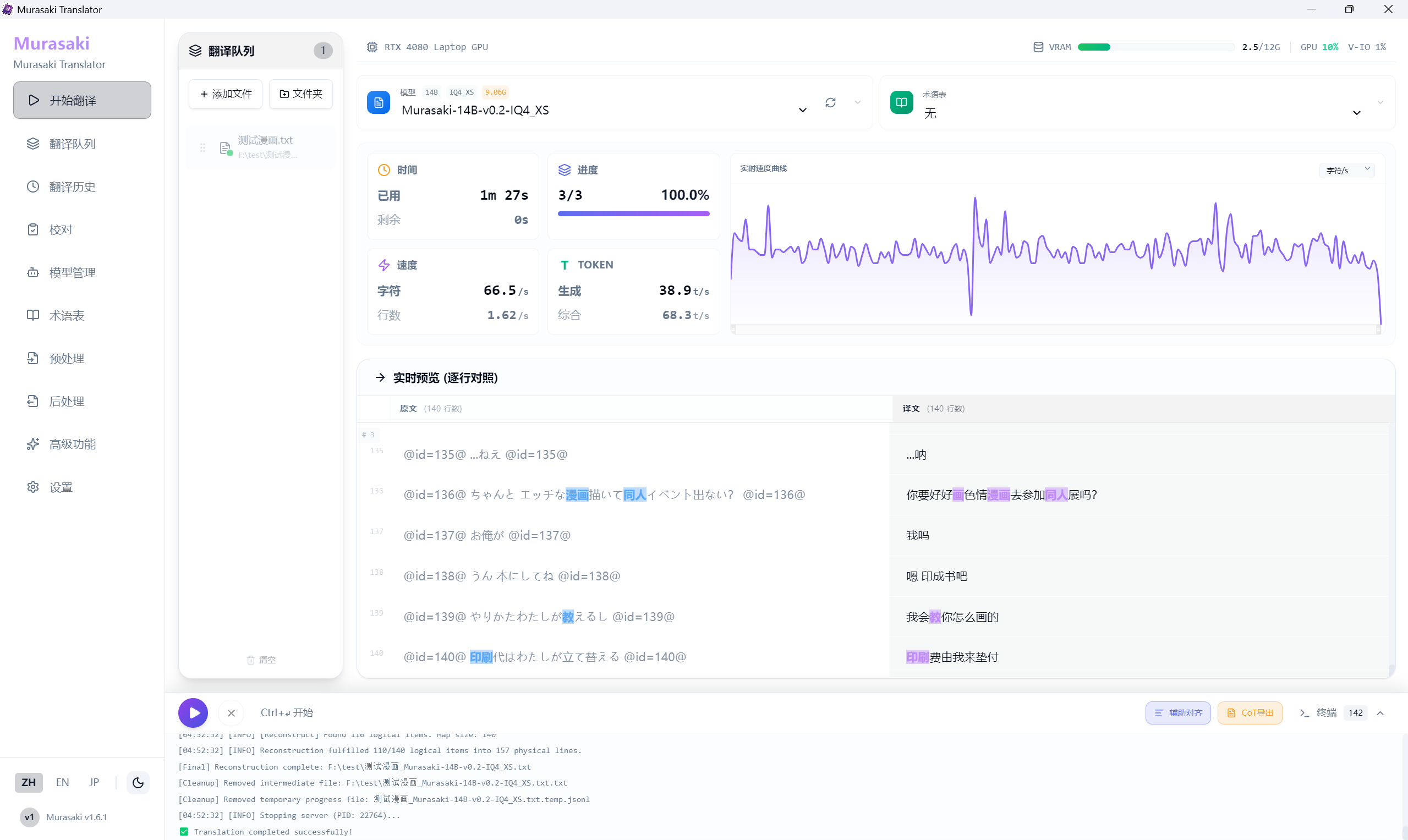
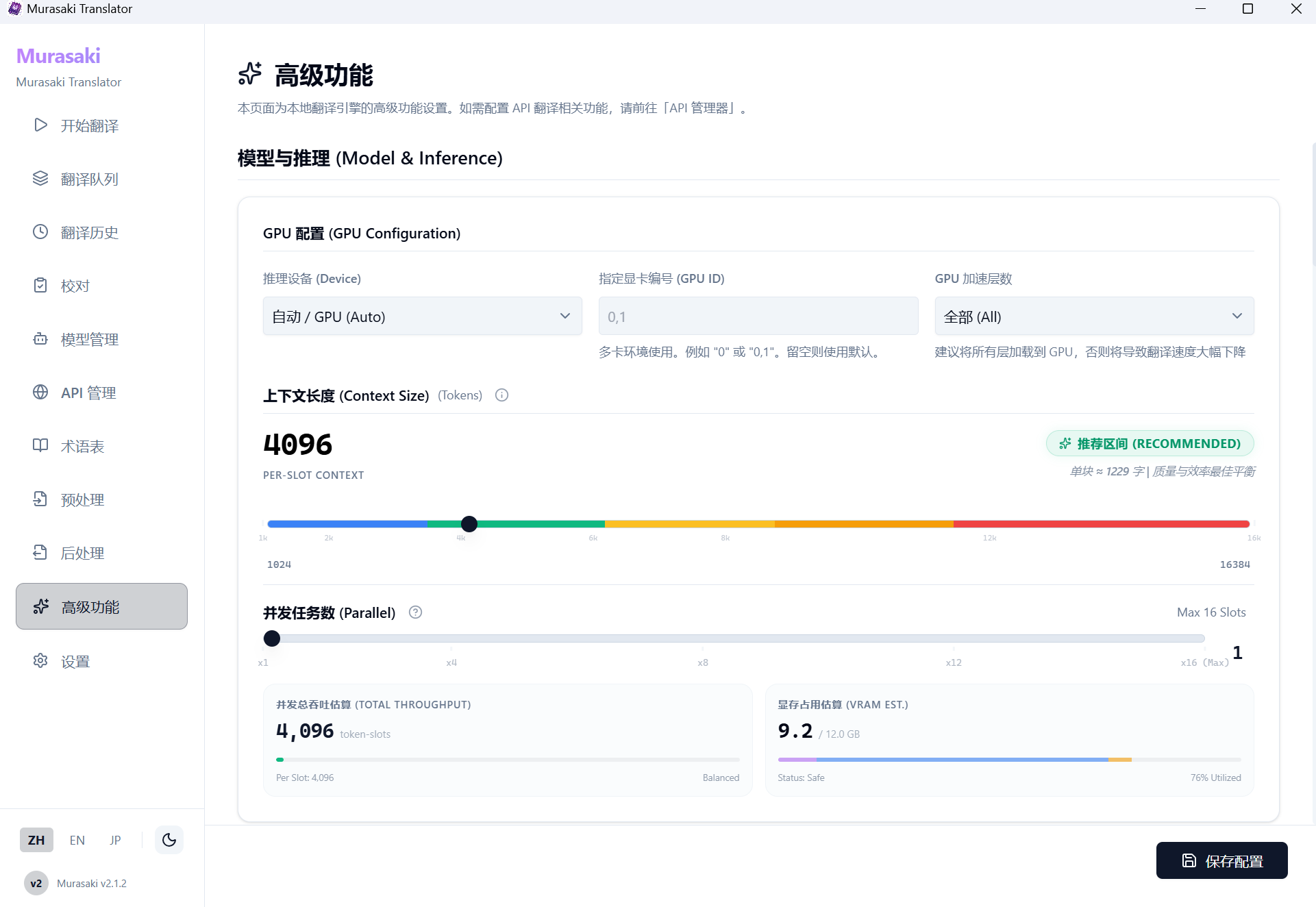
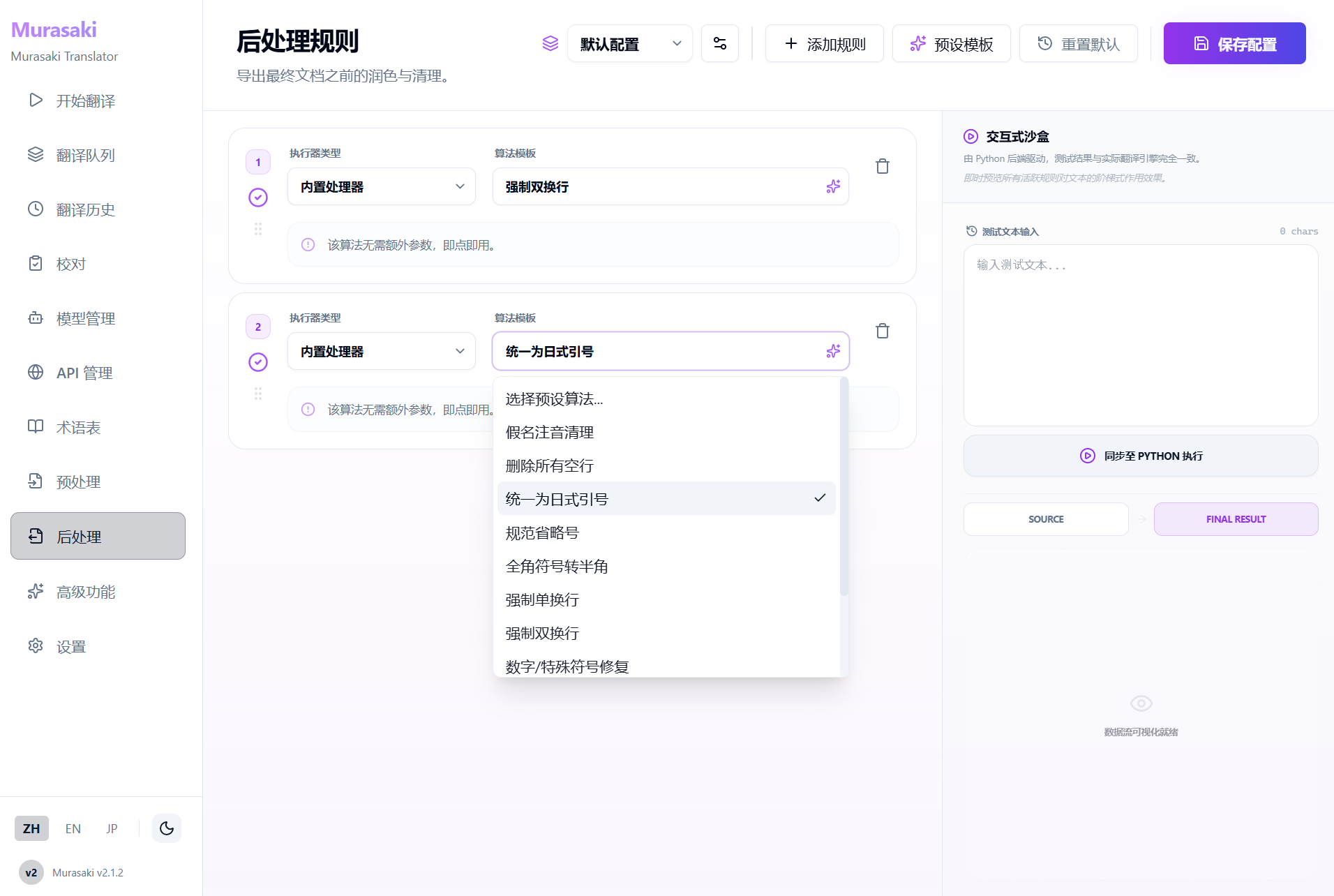
可以一键安装然后将日文 epub/txt/srt/ass 等文件翻译,原格式输出。配置简单,并且内置几乎完全可自定义的功能。
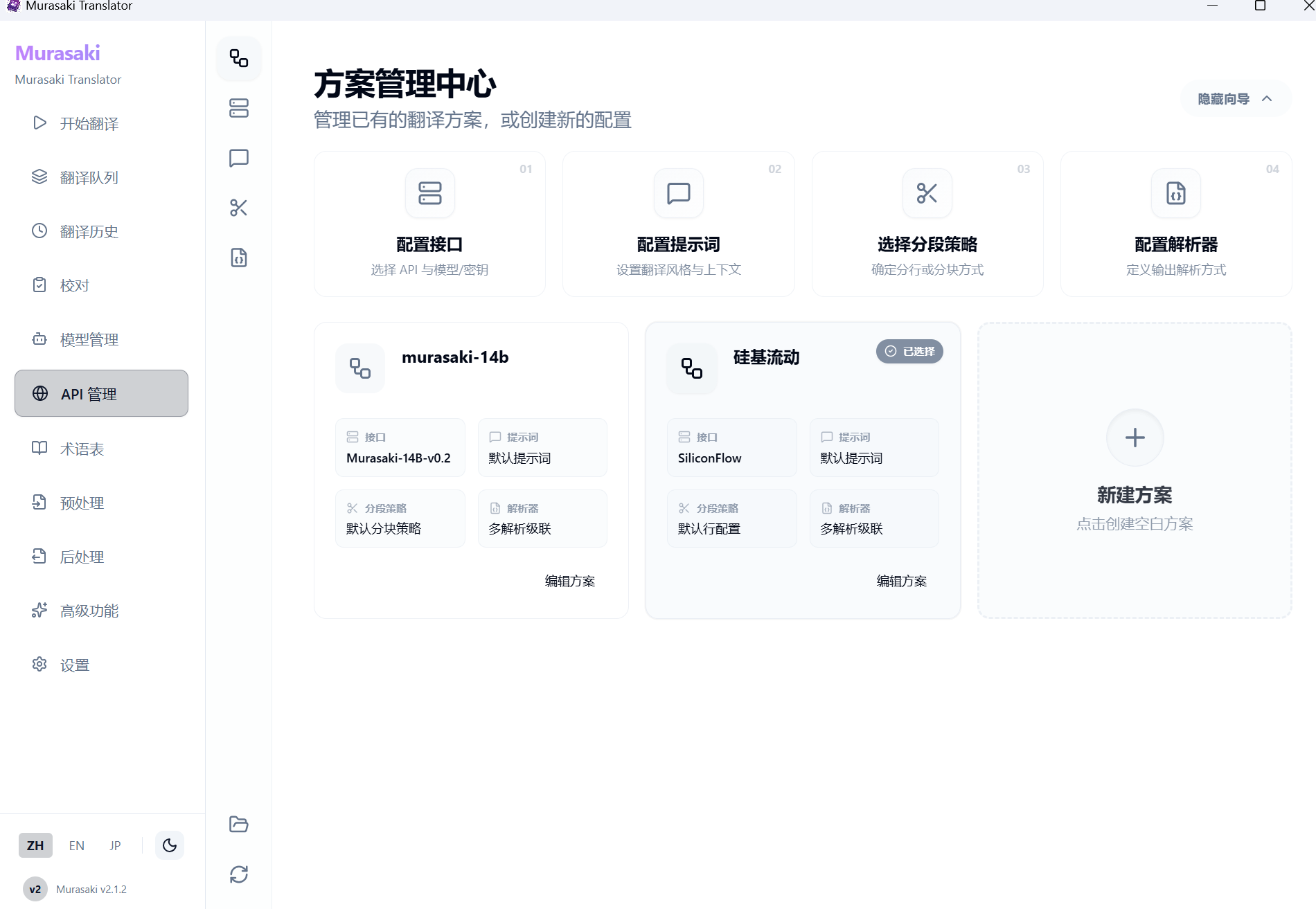
顺带一提使用第三方 API 也是可以用这个 GUI 进行翻译的,具体就不多说了贴几张图吧