背景介绍
NotebookLM 原本在 AI 笔记方面比较平淡,在今年 10 月推出 AI 播客功能后大火,用它可以对论文、书籍、故事等转化成 AI 短音频。
AI 大佬 Andrej Karpathy 曾称赞 NotebookLM“点亮了 LLM 的新交互范式”。在很多网友看来,“NotebookLM 是一款非常适合学习的 AI 应用。”
说白了不就是文档理解+语音合成吗?这有何难。这里实现一个低配版的。
技术分析
笔记理解
这里首先是笔记的理解,这个比较简单了,首先是文本类型的笔记,是各家大模型的长处,至于各种文档的解析,这里大家可以使用@langchain/community,他封装了各种常见文档的解析,如果你不愿意安装它,也可以自行安装各个子解析器,@langchain/community其实也就是这些子解析器的封装。
至于图片笔记,推荐使用多模态模型进行理解,而不是传统的 OCR 技术,因为多模态模型可以理解语义(文档的重点)、表格、公式。
而音频、视频笔记,推荐使用 ASR ( Automatic Speech Recognition )技术进行语音识别,如果不了解可以看我写的 AI 做视频理解的文章
内容重写
这个没有任何技术难度了,写好题词,交给大模型去处理,不过题词要注意,语音合成,除了多音字等老大难问题(这个也很难解决),还有一个难点是数字的读法,这个可以在重写时交给大模型解决,这里提供一个题词,大家可以在此基础上优化,也欢迎大家给出自己的优化方案
请根据用户要求重新优化内容。
如果目标文字是中文,请遵循以下原则:
把文中的数字按中文习惯替换成中文,包括但不限于日期、时间、数字单位等。例如“2024 年”替换为“二零二四年”,“15.7 万人”替换为“十五点七万人”;
尽可能把文中不适合 TTS 识别的符号跟据语义替换为中文,例如“-”替换为“减”,但是不要强行替换;
直接返回优化后的内容,不要任何解释,不要使用 Markdown 格式。
语音合成
这里有 3 个方案
当然现在语音合成方案百花齐放,比如原来一直可以白嫖的 edge 的 TTS 服务(现在被微软针对了),阿里等巨头也在这块陆续发力,大家可以持续关注。
多人配音
这个其实也不难,只不过把之前的 3 样技术组合起来做的更细致一些,这个我个人就没有尝试了,给大家推荐一款做的不错的工具:视频翻译软件 pyVideoTrans-开源免费的视频翻译配音软件,也是我学语音技术的启蒙,在此感谢一下作者大佬。
代码实现
代码实现其实没有什么难点
对于使用 ChatGPT 来说,就是自己调用 API ,也没有什么参数可以调整
对于使用 GPT-SoVITS 来说,也是调用 API ,不过其 API 很丝滑,可以方便的提供类似听书一样的功能
对于使用 ChatTTS 来说,分句这些都要你自己来说,相对难度大一些,但是分句这些也不是很难,无外乎遇到标点就断句
效果展示
把语音识别翻译后的文本内容转为播客
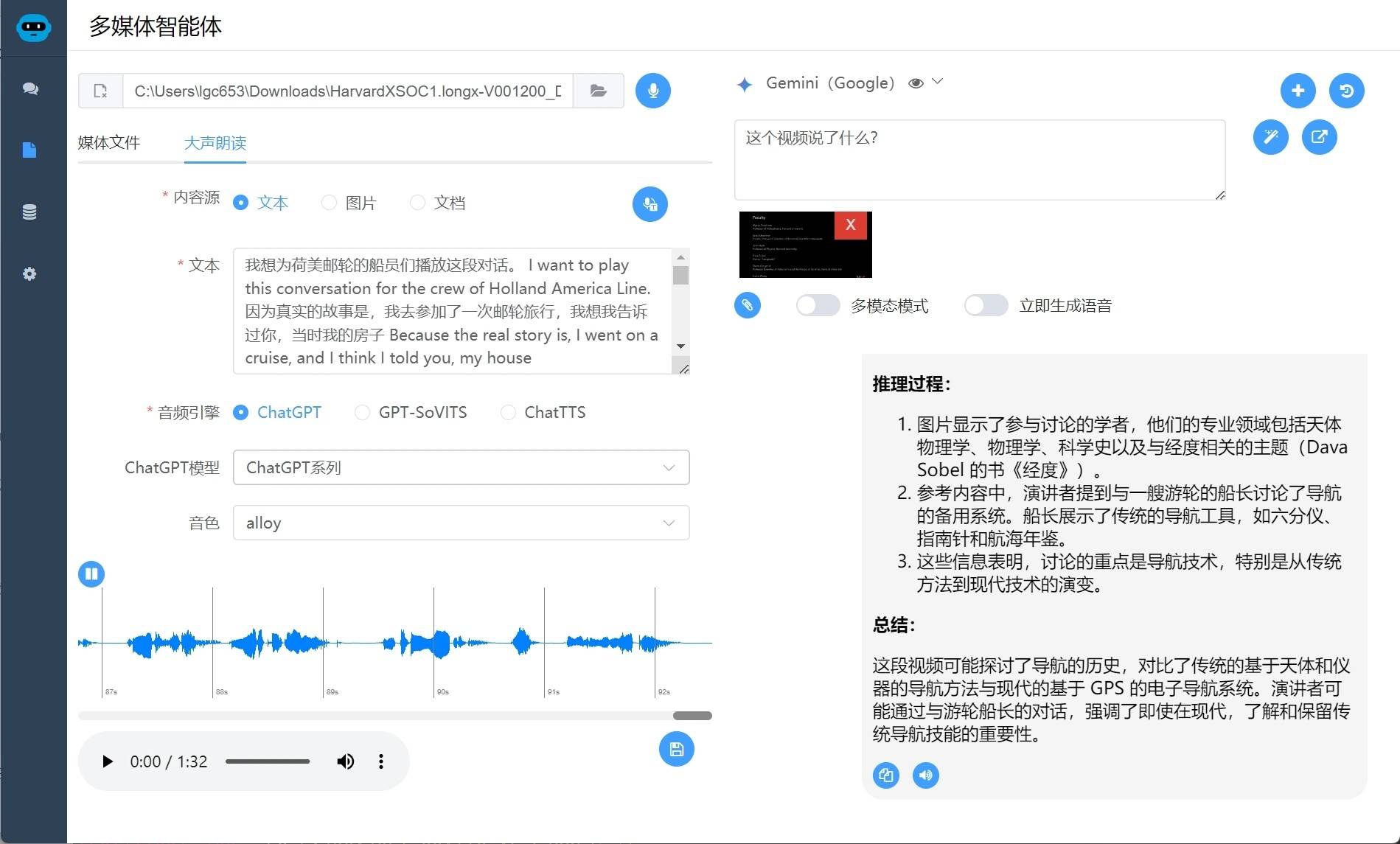
太长不想看,长图片一键转换成播客。
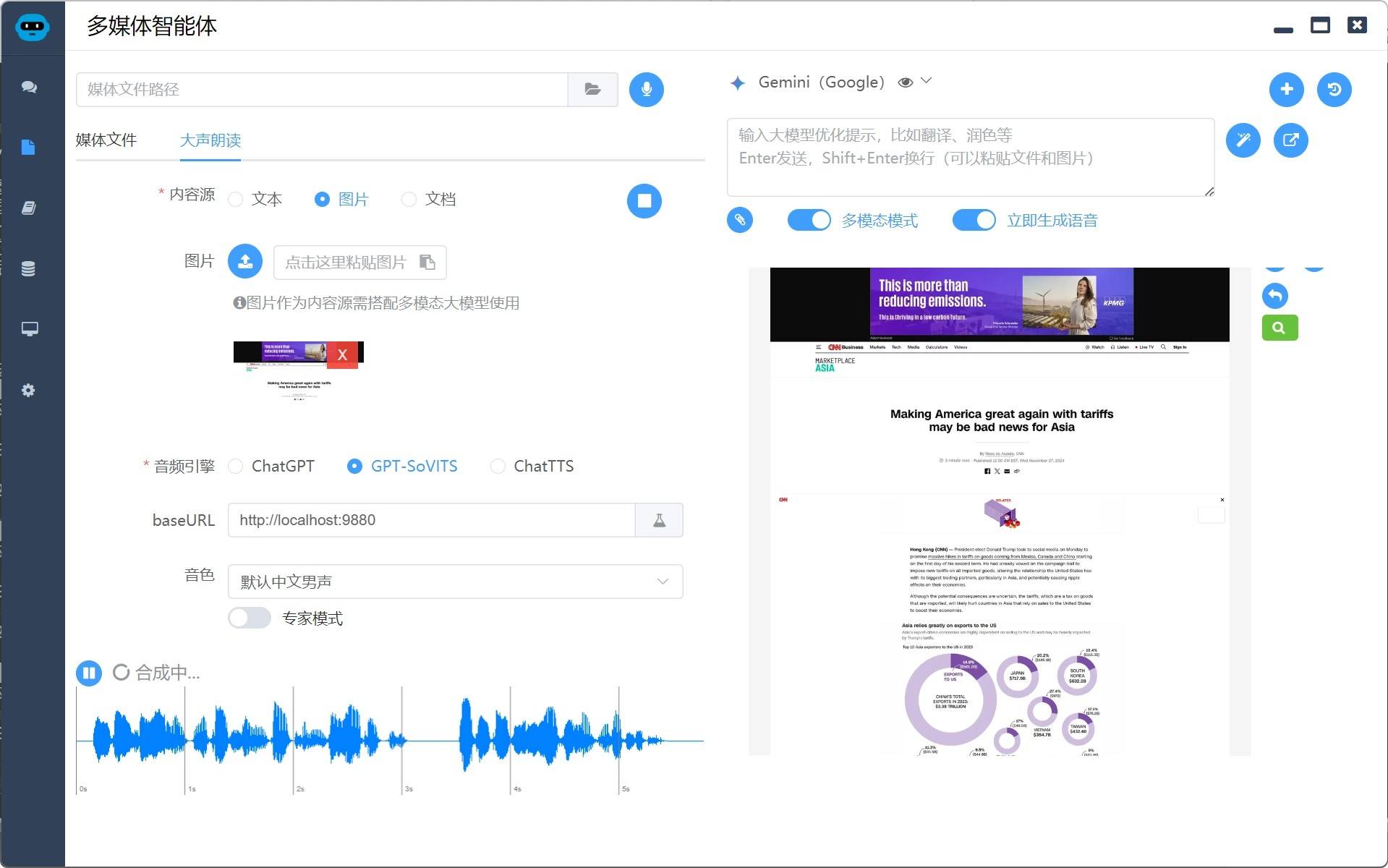
现在微信读书不能听本地书了,这里自己实现的 epub 的听书功能。