爬取竞赛试题_上海高考网 (gaokao.com)这个页面下所有的试题文件
初出茅庐
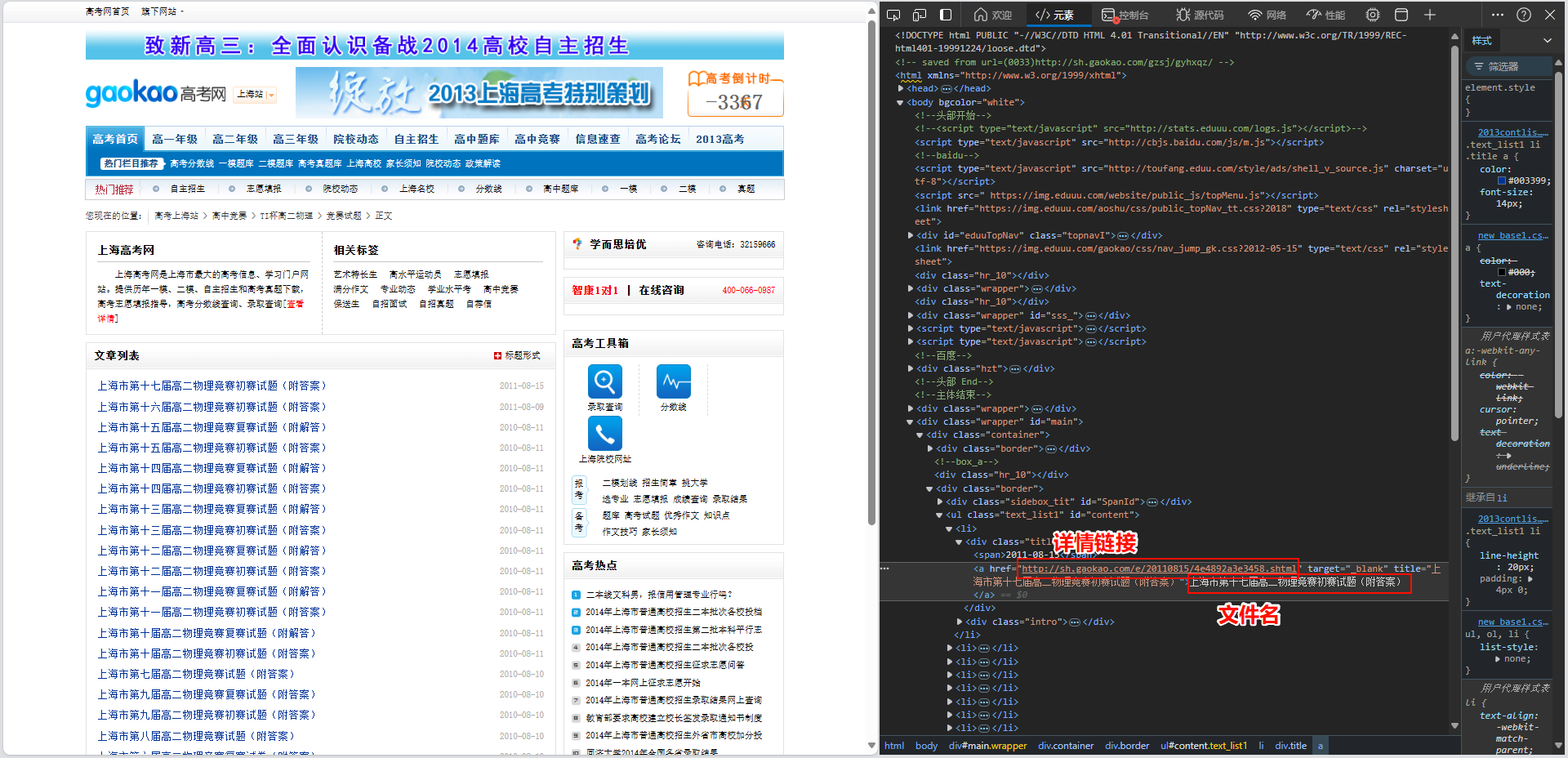
我们直接抓取这个页面,解析出每个详情链接和文件名称
# -*- coding:utf-8 -*-
import requests
from lxml import etree
url = 'http://sh.gaokao.com/gzjs/gewl/gewlst/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'
}
# 创建文件目录实例
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@id="main"]//ul[@class="text_list1"]/li')
for li in li_list:
detail_url = li.xpath('./div[@class="title"]/a/@href')[0] # 获取详情页链接
name = li.xpath('./div[@class="title"]/a/text()')[0] # 获取文件名
第一难: 乱码的中文
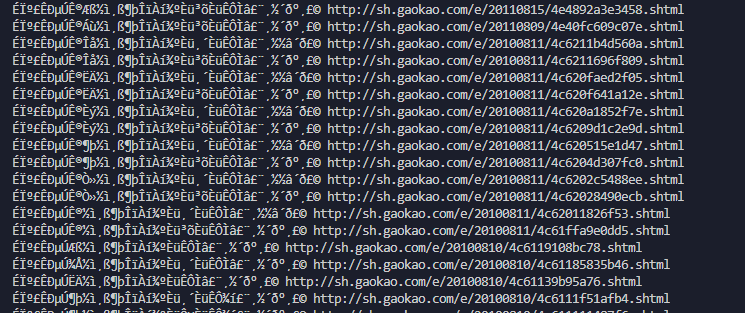
我们把名字和链接输出一下看看能不能正常获取
print(name, detail_url)
看一下结果,发现中文乱码了,但是应该都正确地获取了
我们来处理一下中文编码问题
打开网页源代码, 找到表头
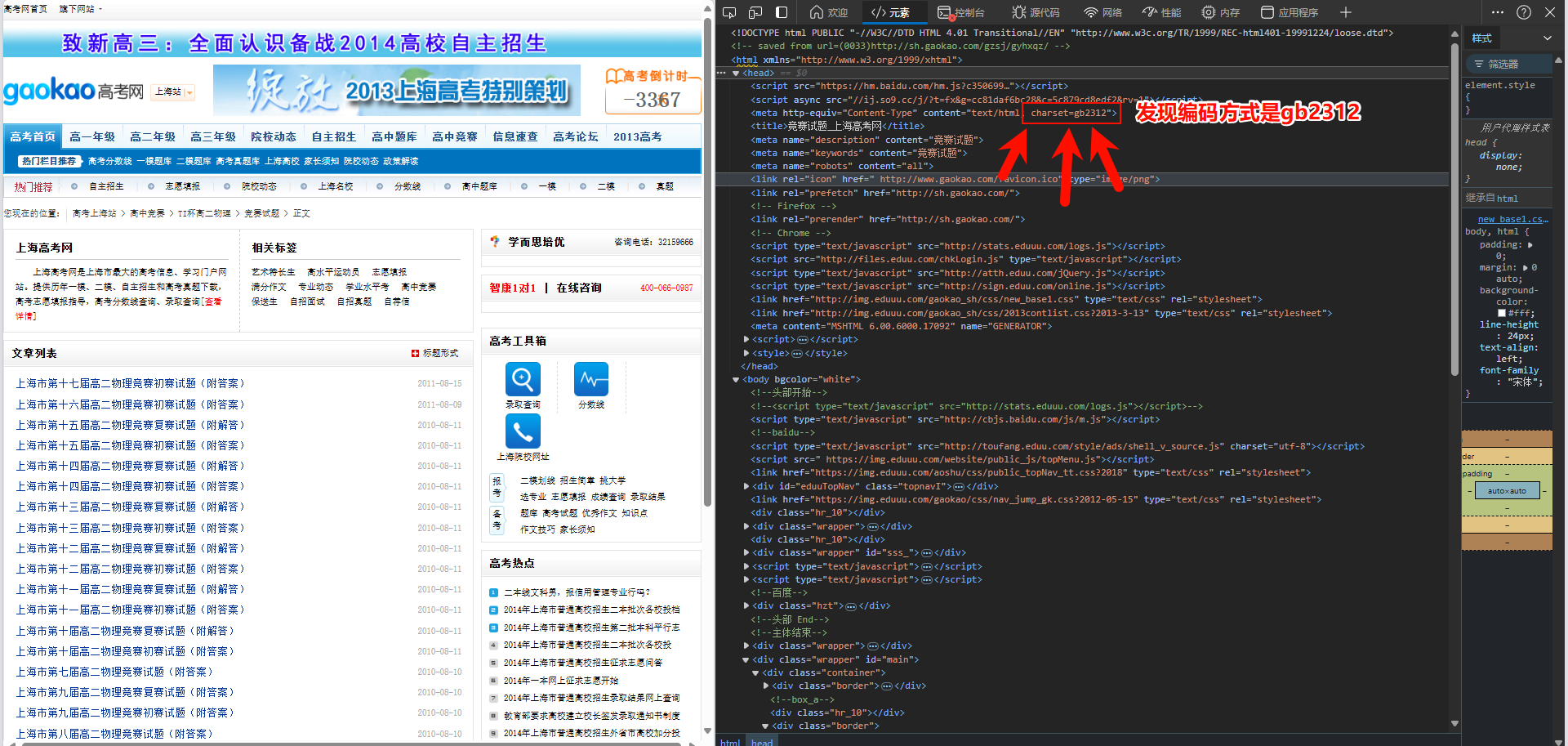
这就好办了, 改一下编码
response = requests.get(url=url, headers=headers)
response.encoding = 'gb2312'
page_text = response.text
重新运行程序, 乱码问题解决了
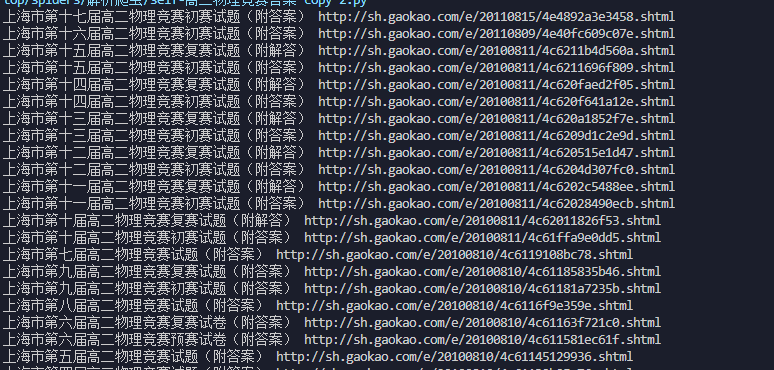
然后我们抓取详情页, 分析一下下载链接的位置
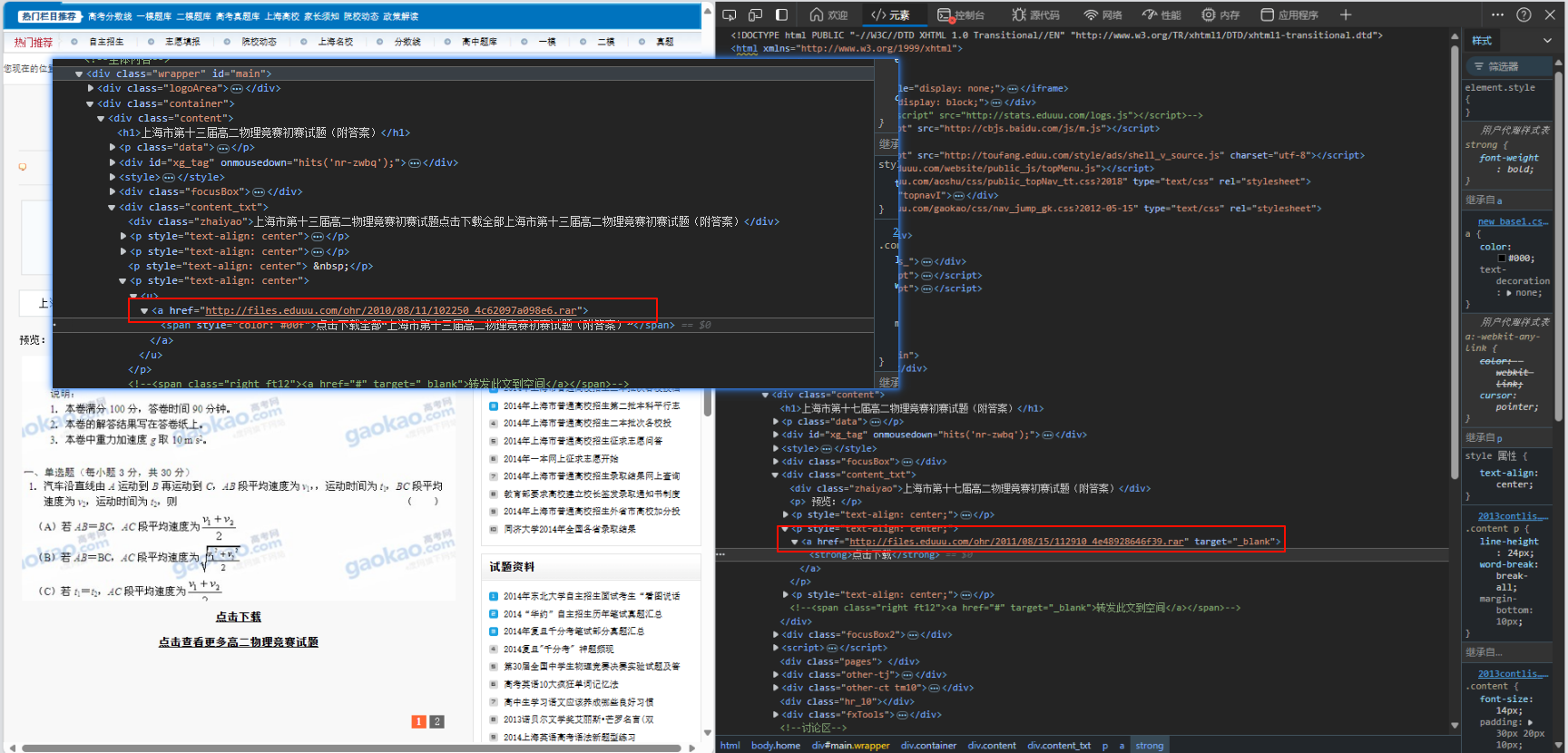
随便打开几个, 发现每个页面结构都有些不同, 但是好在只有一个rar文件下载链接, xpath已经不合适了, 考虑用正则表达式
import re
detail_text = requests.get(url=detail_url, headers=headers).text
down_url = re.findall('(http://files\.eduuu\.com/ohr/.*?\.rar)', detail_text, re.S)[0] # 发现每个页面框架不一样,但是只有一个rar文件
第二难: 超时的响应
输出一下下载链接, 看看有没有问题
print(down_url)
等了半天, 输出了几条, 最后报错了 (运气不好的话可能一条都没输出直接报错)
输出了部分说明语法和逻辑方面没什么问题
urllib3.exceptions.ProtocolError: Response ended prematurely
requests.exceptions.ChunkedEncodingError: Response ended prematurely
如果你注意到细节的话, 可以发现当你点进详情页的时候, 虽然内容很快呈现, 但是标签页上还在转圈, 这与你的网速有关, 但我认为更主要的是服务器不稳定
没有什么特别好的方法, 只能在GET请求的时候加一个长一点的超时
detail_text = requests.get(url=detail_url, headers=headers, timeout=300).text
第三难: 避免重复下载
既然超时无法避免, 我们需要一些策略来避免一些重复的操作, 比如将已经下载好的文件重新下载一遍
原本的下载文件:
# 下载并保存rar文件
data = requests.get(url=down_url, headers=headers, timeout=180).content
with open(ans_path, 'wb') as fp:
fp.write(data)
print(name, '下载成功')
我们直接在解析文件下载链接之前套一个简陋的if判断是否已经下载
if not os.path.exists(ans_path):
# 获取文件下载链接
detail_text = requests.get(url=detail_url, headers=headers, timeout=300).text
down_url = re.findall('(http://files\.eduuu\.com/ohr/.*?\.rar)', detail_text, re.S)[0] # 发现每个页面框架不一样,但是只有一个rar文件
# 下载并保存rar文件
data = requests.get(url=down_url, headers=headers, timeout=180).content
with open(ans_path, 'wb') as fp:
fp.write(data)
print(name, '下载成功')
else:
print(name, '已存在')
第四难: 用线程池增加成功率(玄学)
我们用多线程来下载, 先将我们的下载代码封装成一个函数
import os
def down(li):
detail_url = li.xpath('./div[@class="title"]/a/@href')[0] # 获取详情页链接
name = li.xpath('./div[@class="title"]/a/text()')[0] # 获取文件名
ans_path = './phy/' + name +'.rar' # 生成文件路径
if not os.path.exists(ans_path):
# 获取文件下载链接
detail_text = requests.get(url=detail_url, headers=headers, timeout=300).text
down_url = re.findall('(http://files\.eduuu\.com/ohr/.*?\.rar)', detail_text, re.S)[0] # 发现每个页面框架不一样,但是只有一个rar文件
# 下载并保存rar文件
data = requests.get(url=down_url, headers=headers, timeout=180).content
with open(ans_path, 'wb') as fp:
fp.write(data)
print(name, '下载成功')
else:
print(name, '已存在')
然后开10个线程来执行
from multiprocessing.dummy import Pool
pool = Pool(10)
pool.map(down, li_list)
pool.close()
pool.join()
这样可以提升一些执行成功率
第五难: 最后的BUG
当你下载得差不多的时候, 突然又报错了
IndexError: list index out of range
并且指向了这一行代码:
down_url = re.findall('(http://files\.eduuu\.com/ohr/.*?\.rar)', detail_text, re.S)[0]
索引已经是0了, 却仍然报这个错误, 说明在某一次执行中正则表达式啥都没匹配到
经过排查找到了罪魁祸首:
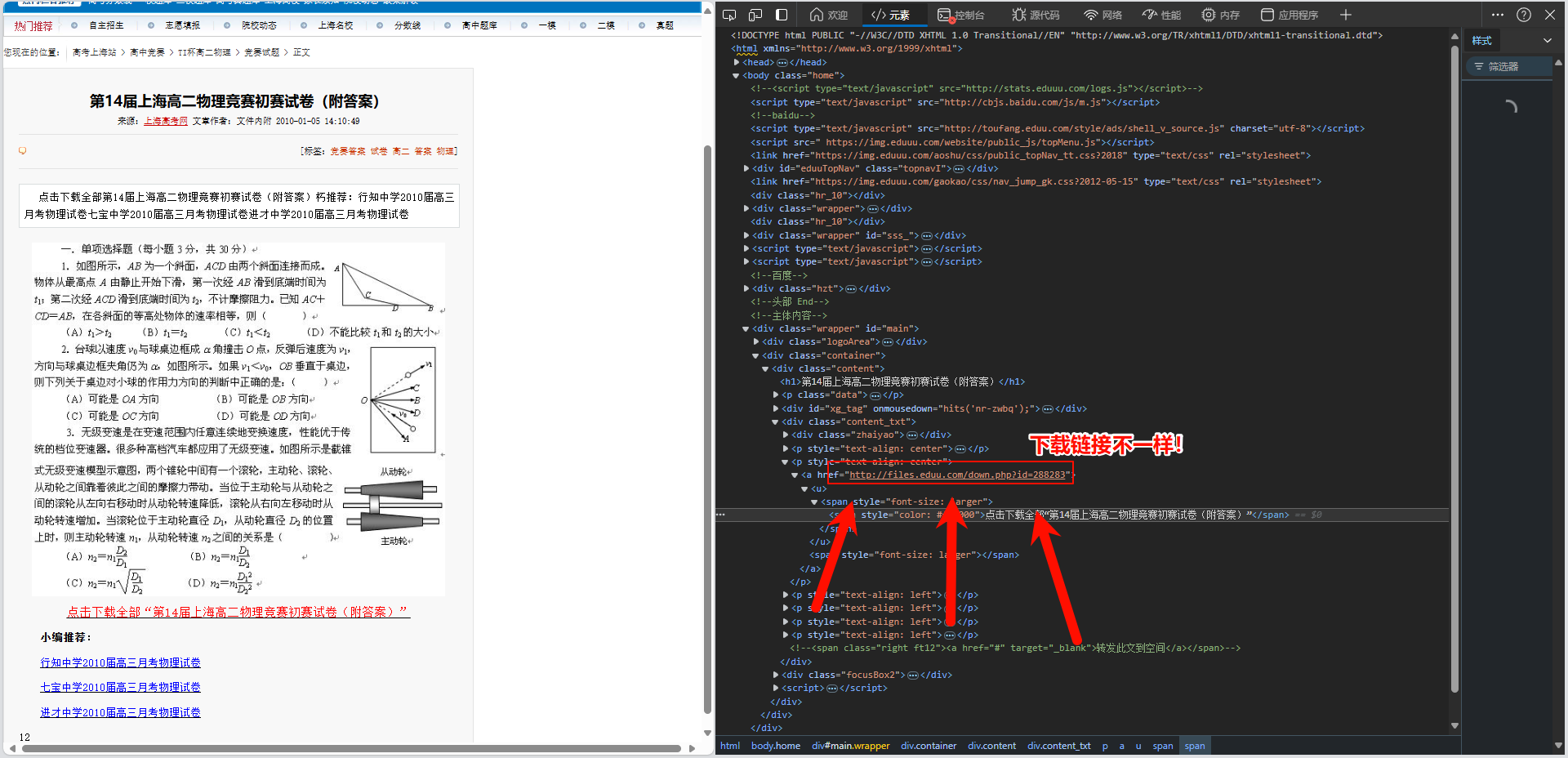
那么我们在正则表达式里给他加个特判就解决了
down_url = re.findall('(http://files\.eduuu\.com/ohr/.*?\.rar)|(http://files\.eduu\.com/down\.php\?id=288283)', detail_text, re.S)[0] # 发现每个页面框架不一样,但是只有一个rar文件, 第14届的要特判
但是这里要注意, 这样解析出的结果是一个列表(其中一项是空的, 一项是下载链接), 因为表达式中有两个捕获组, 如果直接这么写, requests模块无法解析正确的url, 所以要手动判断一下
解决方法为加入下面这段代码
if down_url[0]:
down_url = down_url[0]
else:
down_url = down_url[1]
第六难: 最后的美化
在各个主要的代码前后加入了输出提示
发现由于文件名长度差异大, 直接用\t无法实现对齐, 所以又写了个函数, 就不展开了
源码
最后附上全部源码!
# -*- coding:utf-8 -*-
import requests
from lxml import etree
import os
import re
from multiprocessing.dummy import Pool
import unicodedata
# 创建储存目录
if not os.path.exists('./phy'):
os.makedirs('./phy')
url = 'http://sh.gaokao.com/gzjs/gewl/gewlst/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'
}
# 创建文件目录实例
response = requests.get(url=url, headers=headers, timeout=120)
response.encoding = 'gb2312'
page_text = response.text
tree = etree.HTML(page_text)
# 输出对齐函数
width = 68
def get_display_width(text):
width = 0
for char in text:
if unicodedata.east_asian_width(char) in 'WF':
width += 2
else:
width += 1
return width
def format_text(text, width):
display_width = get_display_width(text)
padding = width - display_width
return text + ' ' * padding
# 解析li列表
li_list = tree.xpath('//div[@id="main"]//ul[@class="text_list1"]/li')
def down(li):
detail_url = li.xpath('./div[@class="title"]/a/@href')[0] # 获取详情页链接
name = li.xpath('./div[@class="title"]/a/text()')[0] # 获取文件名
ans_path = './phy/' + name +'.rar' # 生成文件路径
if not os.path.exists(ans_path):
# 获取文件下载链接
print(f"{format_text(name, width)}\t\033[0;36m\033[1m获取下载链接......\033[0m")
detail_text = requests.get(url=detail_url, headers=headers, timeout=300).text
down_url = re.findall('(http://files\.eduuu\.com/ohr/.*?\.rar)|(http://files\.eduu\.com/down\.php\?id=288283)', detail_text, re.S)[0] # 发现每个页面框架不一样,但是只有一个rar文件, 第14届的要特判
if down_url[0]:
down_url = down_url[0]
else:
down_url = down_url[1]
print(f"{format_text(name, width)}\t\033[0;32m\033[1m成功获取下载链接!\033[0m")
# 下载并保存rar文件
print(f"{format_text(name, width)}\t\033[0;36m\033[1m开始下载......\033[0m")
data = requests.get(url=down_url, headers=headers, timeout=180).content
with open(ans_path, 'wb') as fp:
fp.write(data)
print(f"{format_text(name, width)}\t\033[0;32m\033[1m下载成功!\033[0m")
else:
print(f"{format_text(name, width)}\t\033[0;35m\033[1m已存在!\033[0m")
temp_txt = '\033[0;37m\033[1m文件\033[0m'
print(f"{format_text(temp_txt, 85)}\t\033[0;34m\033[1m状态\033[0m")
pool = Pool(10)
pool.map(down, li_list)
pool.close()
pool.join()
print('\n\033[0;32m\033[1m\033[4m全部下载完成!\033[0m')
结语&注意事项
[ol]
[/ol]
