代码如下
import asyncio
import os.path
import aiofiles as aiofiles
import aiohttp as aiohttp
import requests as requests
from pyquery import PyQuery as q
def get_all_chapter():
response = requests.get("https://www.mingchaonaxieshier.com/")
pq = q(response.content)
books = [i for i in pq("div.mulu table").items()]
books_data = []
for book in books:
trs = [i for i in book('tr').items()]
book_chapters = []
# build chapters of every book
for i in trs[1:]:
for j in i('a').items():
book_chapters.append({
"title": j.text(),
"href": j.attr('href')
})
books_data.append({
"book_title": trs[0].text(),
"chapters": book_chapters
})
return books_data
def build_tasks(books):
task_list = []
for book in books:
for chapter in book['chapters']:
task_list.append(asyncio.ensure_future(download_chapter(chapter, book['book_title'])))
return task_list
async def download_chapter(chapter, book_title):
if not os.path.exists(f"./{book_title}/"):
os.mkdir(f"./{book_title}/")
print(f'下载:{book_title}/{chapter["title"]}')
async with aiohttp.ClientSession() as session:
async with session.get(chapter['href']) as response:
src = await response.text()
pq = q(src)
content__text = pq('div.content p').text()
async with aiofiles.open(f'./{book_title}/{chapter["title"]}.txt', mode='w', encoding='utf-8') as f:
await f.write(content__text)
def main():
books = get_all_chapter()
tasks = build_tasks(books)
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
main()
爬虫效果如下
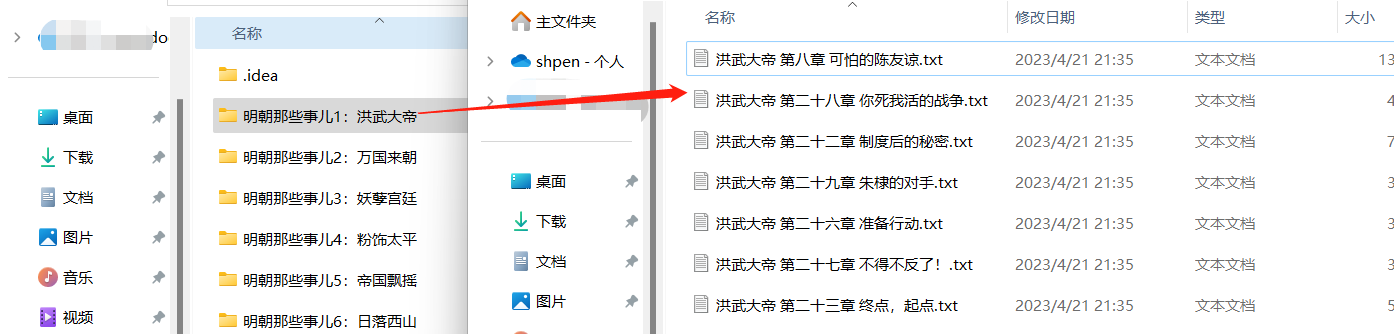
录制教程时这个小说网站文章内容还是挺有规律的,但是新版没有规律了,所以爬出来相当不好看,不知道大佬们有没有更好的想法
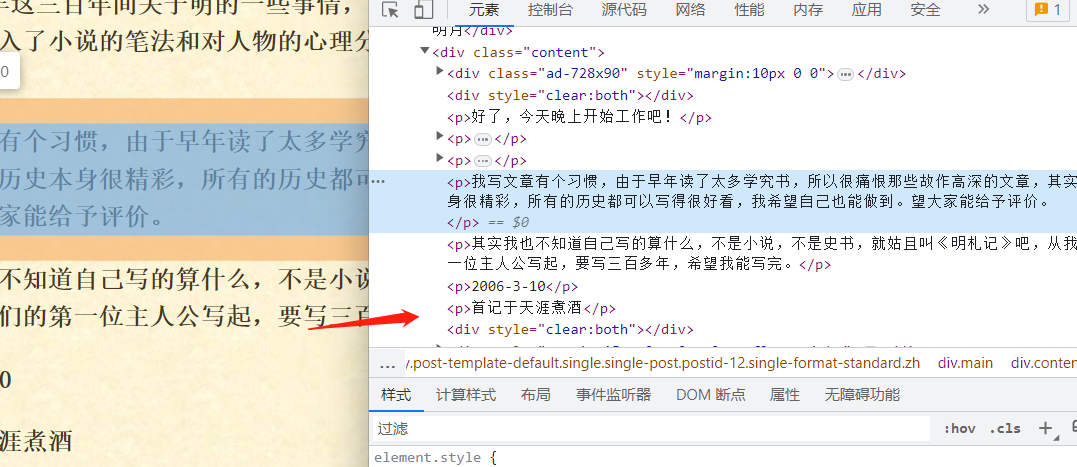
如上图所示,文章内容和评论等内容全放一块了,不太好提取内容,也没有更小单位的元素。
由于我使用的python版本是3.10.11,在使用协程的时候与教程内容有较大的差异,总结如下:
[ol]
[/ol]
以上问题如果有大佬看到麻烦请指点我一下,谢谢了
