最近呢,学了一点js逆向的知识,一直想找个可以实践一下的平台来试试学习效果。偶然间看到了这个平台,发现很适合拿来练手,不过由于这个网站视频开始播放前都有那种不和谐的广告,所以地址就不能贴了,贴图也做了一些脱敏处理!
需要准备的工具:
第一次分析
打开目标网站首页,选择任意一个视频信息点击进入后:
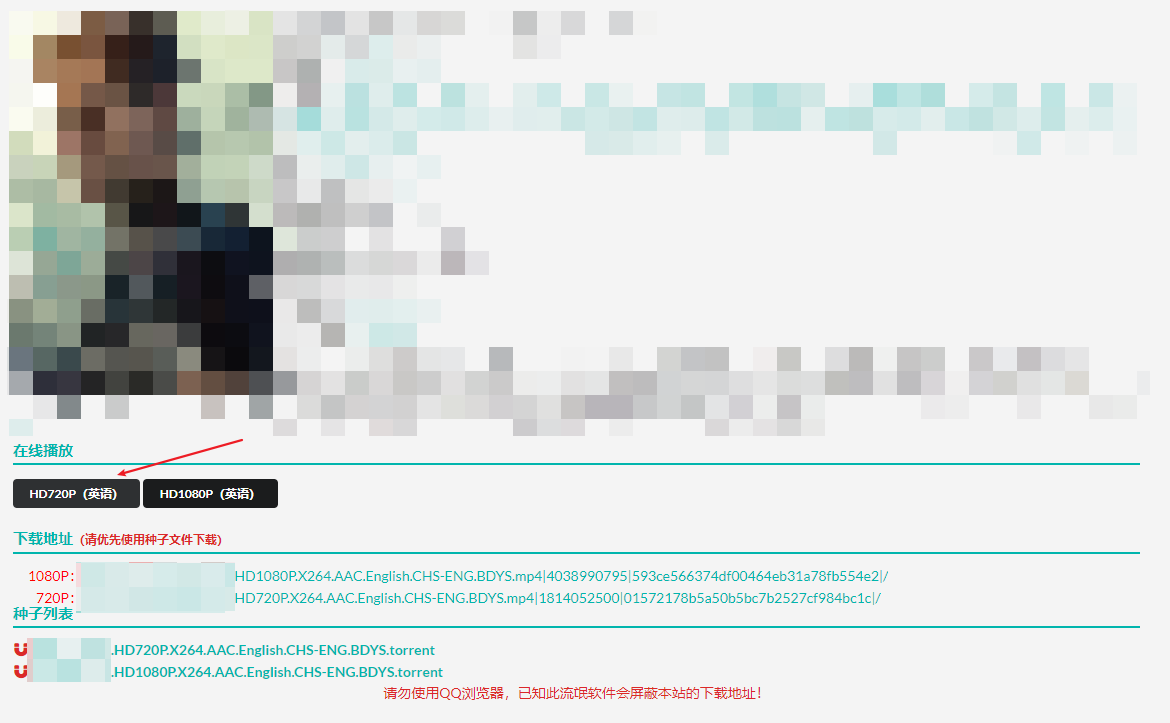
可以直接看到资源下载地址,不过这次目的是来逆向的,所以看不到!看不到!看不到!
1.1 过控制台检测
接下来就到了我们的分析时间,点击【在线播放】后尝试使用快捷键F12打开控制台,然后就弹出了以下提示:

打不开控制台不要紧,选择浏览器右上角的三个小点,从更多工具中打开控制台:
1.2 过无限debug
控制台一打开,立马跳出个无限debuuger,看来还是做了一些反调试措施的:
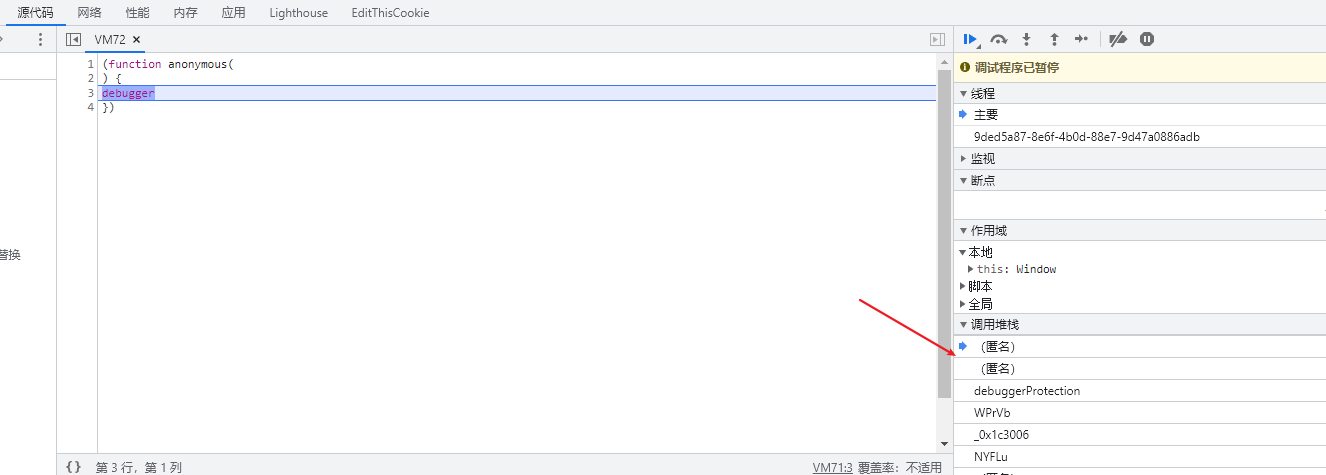
从右边的堆栈中向下查找入口,从上到下依次点击看看:
很显然这个并不是,再往下点时,就发现了非常关键的函数调用:
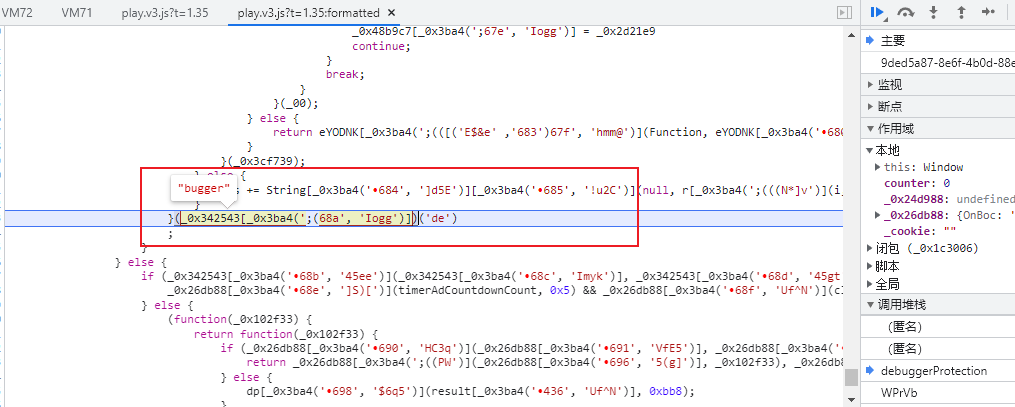
其实这个无限debugger卡了挺长时间的,一开始开始尝试删除这个关键位置的调用,删除整个debugger的自调用函数,甚至删除整个外层的debugger函数,但是发现这些操作会导致视频无法正常加载,控制台过段时间就会直接卡死等莫名其妙的问题,说明这些函数中有些关键地方还是有用的,那看不懂这些混淆的代码又该怎么办呢?难道此次实战就此终结!!!
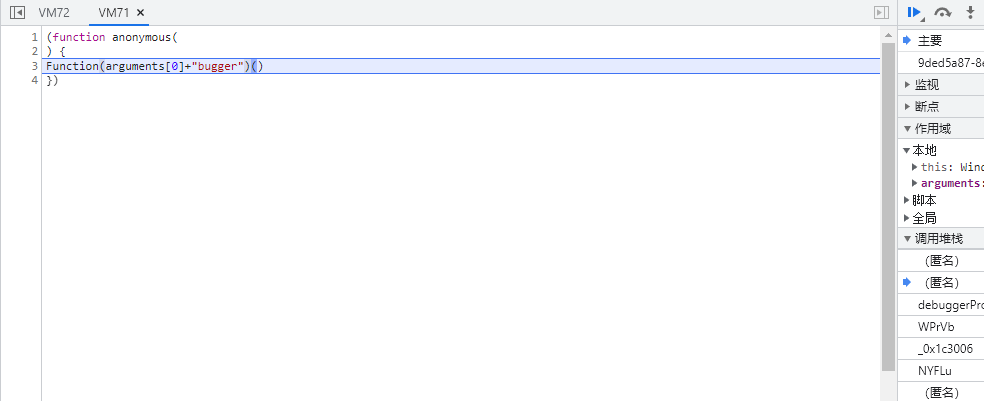
在前思来想去后,突然想到既然debugger关键字会触发断点,那要是我把这个关键字给改了是不是就停不下了?说干就干,把含有无限debugger的js文件在源代码中直接另存为或者从Fiddler另存为一份到本地,方便进行修改。
从上图可以看到前面的内容为“bugger”,后面的内容为“de”,要修改的关键就在这里里,以文本方式打开对应的js,直接搜“de”,发现有5个地方有这个信息:
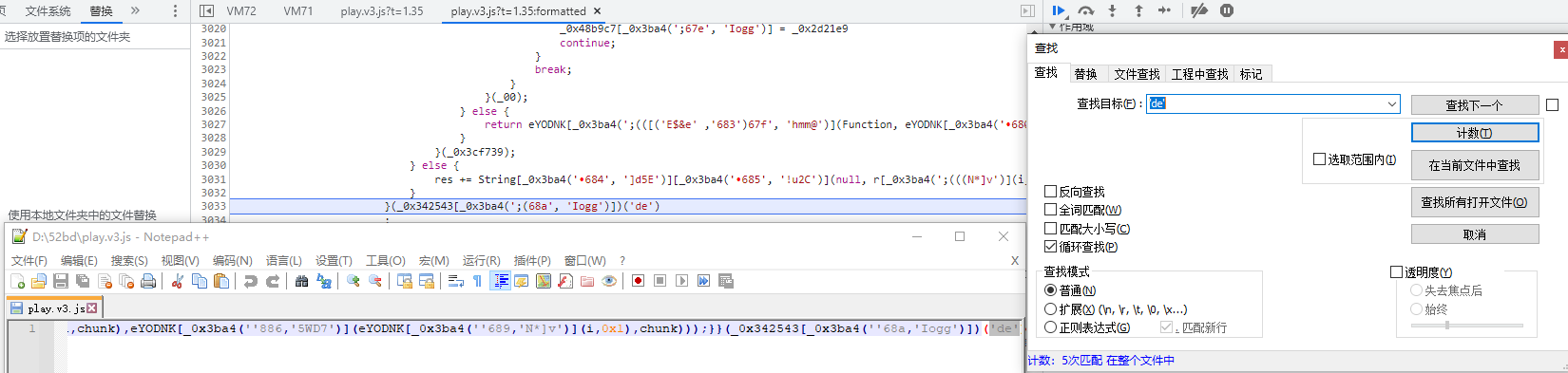
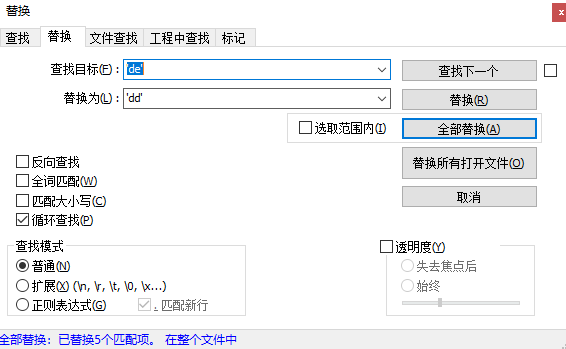
全部替换,这里我替换成“dd”,替换后保存:
打开Fiddler工具,右边选择自动响应,勾选启用规则和请求传递,填写js网络地址和本地js地址,并保存:
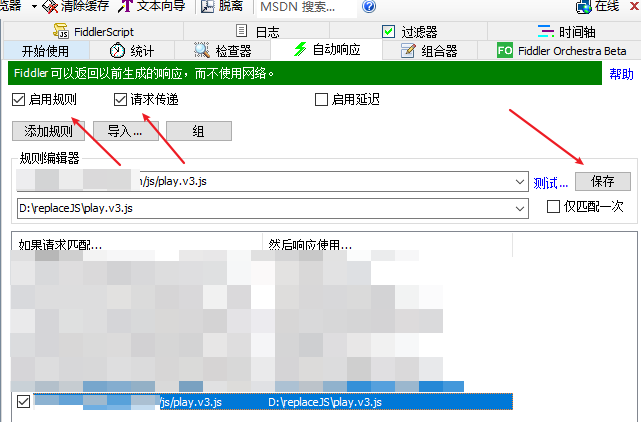
确认Fiddler能获取浏览器请求后,打开浏览器里的设置,选择清空之前的数据,这样才会重新加载本地替换的js文件:
重新打开播放页面后,再次打开控制台,发现不仅无限debugger没了,控制台也正常了,视频也能正常加载了,很好!可以愉快的玩耍了。
1.3 寻找m3u8地址
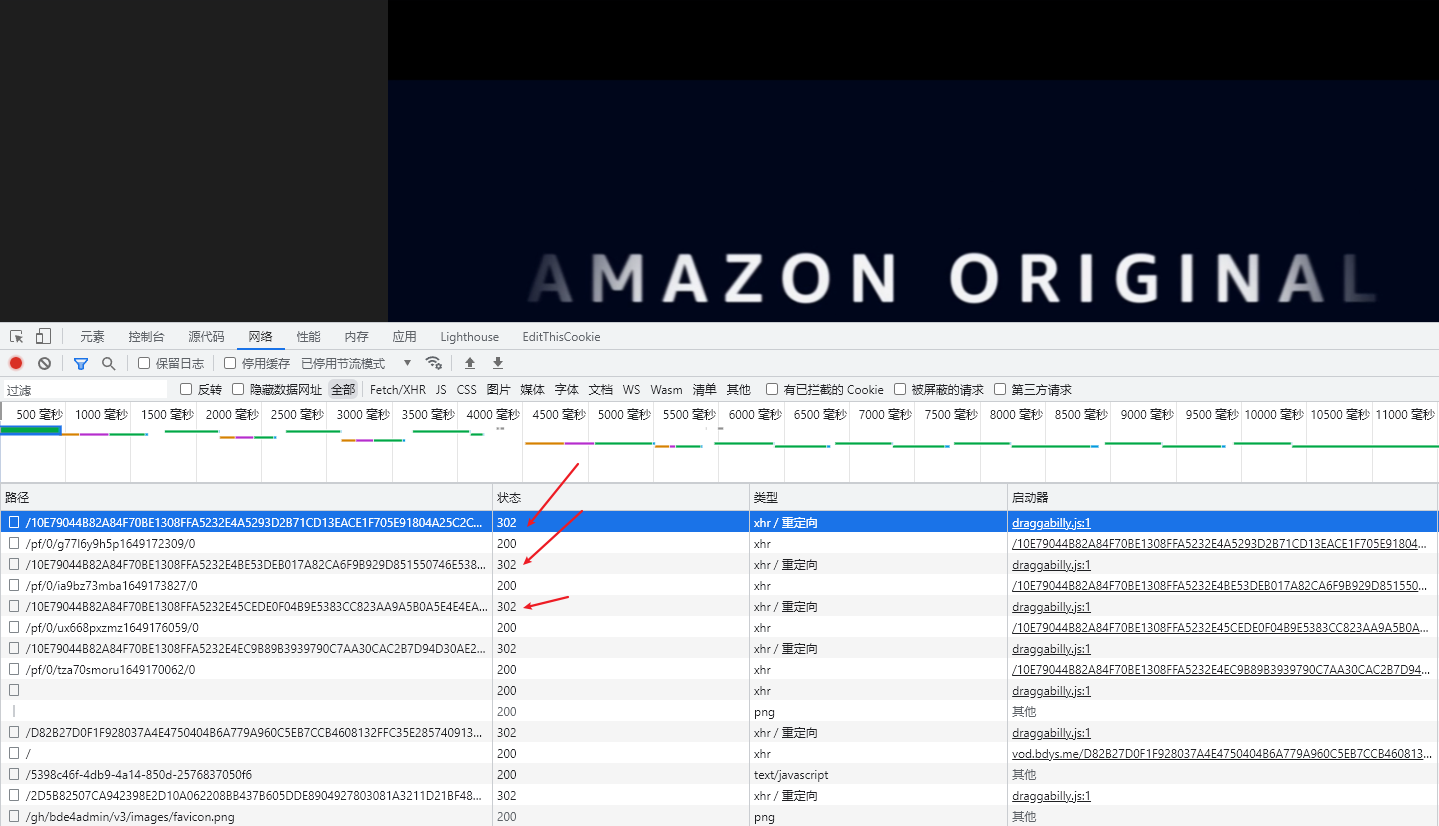
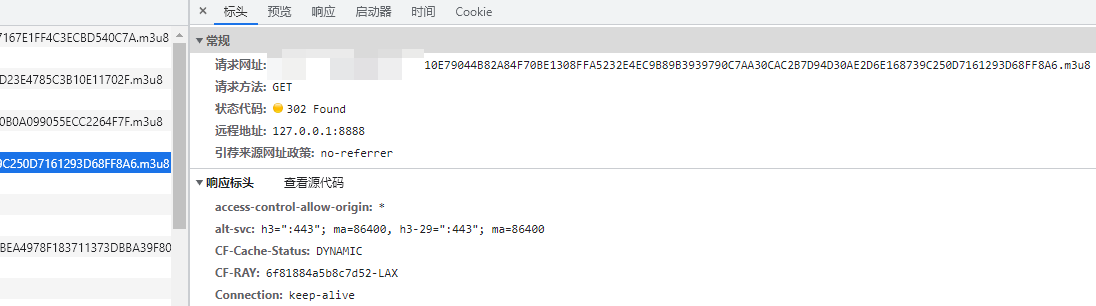
打开网络面板,会发现很多的302请求,302表示重定向,这个请求会在响应中返回一个新的地址。开始查找视频文件地址,发现m3u8文件也被重定向了:
用IDM工具下载这个m3u8文件看看,可以看到返回的居然是一个张图片???
打开看看,额,居然是二维码,扫了一下返回是视频网址,那m3u8信息哪去了?

用winhex打开看看,看这个头信息好像就是一个图片
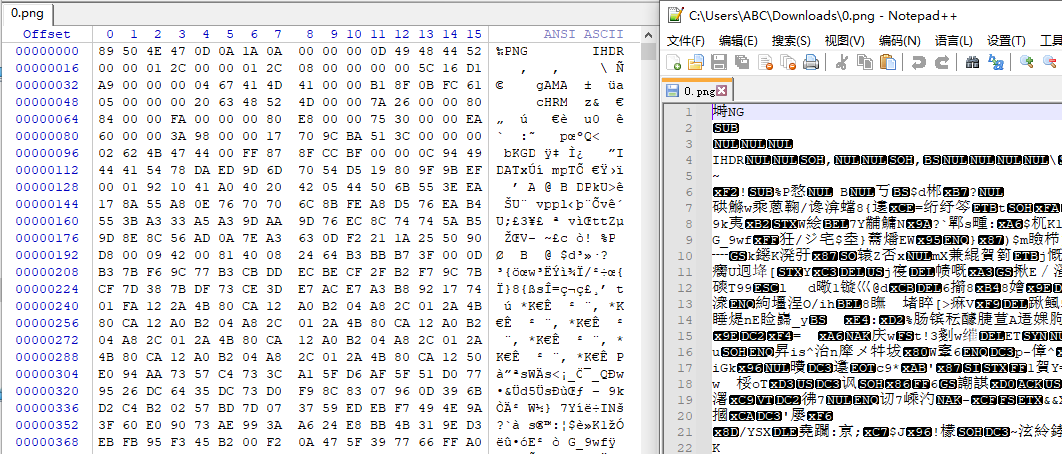
查找一个关键内容看看,winhex直接搜m3u8:
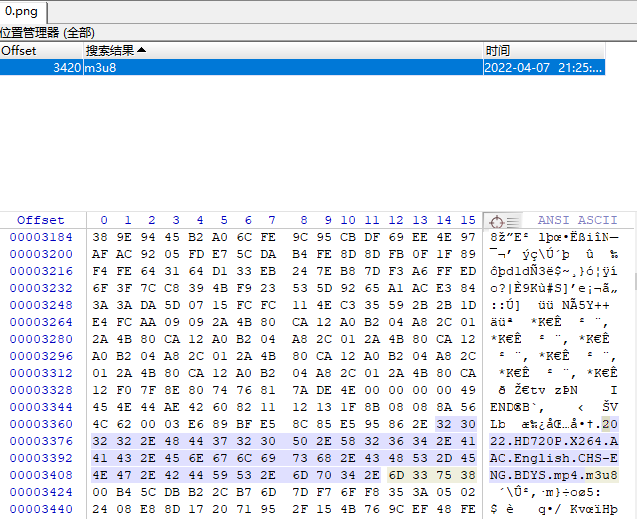
发现并不是想要的内容,用winhex前后翻看发现基本都是乱码,那么极有可能m3u8的内容被加密了,存放在这个图片中。尝试在源代码中查找m3u8文件的调用堆栈发现事情并不简单,很多地方的js代码都被混淆了,所以要找到还原方法实属头大,可是没有代码就不能还原出m3u8的内容怎么办?于是想到加载ts文件不是也得从m3u8的内容中读取吗?所以开始尝试查找ts的调用堆栈,这里可以看到ts的请求也是302状态码,先不管:

把鼠标放在其中一个ts请求的启动器上,点击浮窗中展示的js文件进入调式:
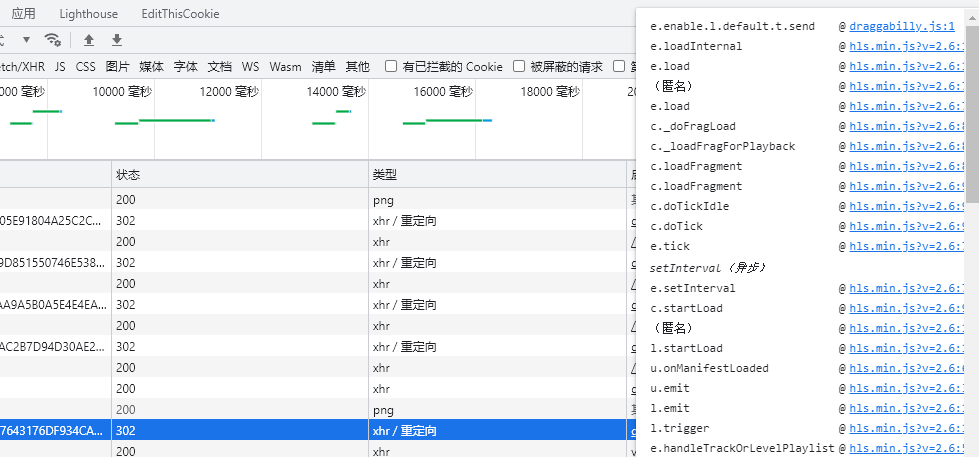
这里会自动跳转到源代码中js的点击位置,先在这里打上一个断点,免得调试过头了。
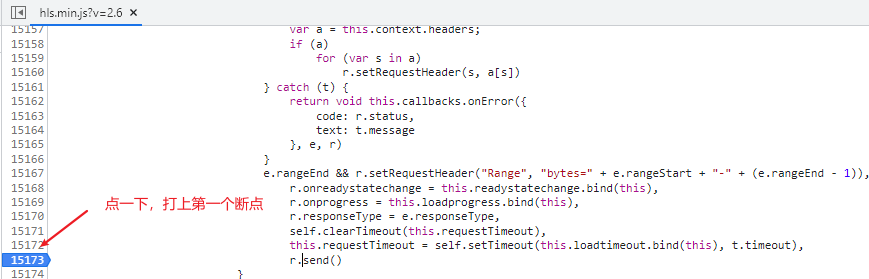
从右下角的
堆栈从上往下依次点击看看,在每个堆栈位置前后翻翻,然后发现了一个有关m3u8的信息,在这里下断点:
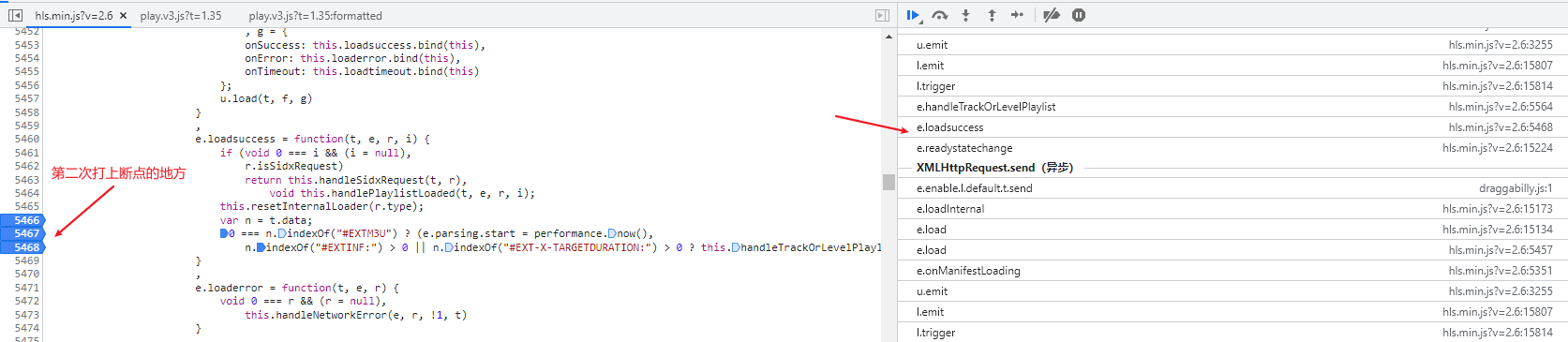
F5重新加载页面,可以看到m3u8的内容此时已经被加载了:

尝试把这个m3u8信息保存下来,打开控制台输入了以下代码:
const data = t.data; // 这里填内容的字符串
const blob = new Blob([data], {type: "text/plain"});
const a= document.createElement("a");
a.href = URL.createObjectURL(blob);
a.download = "demo.m3u8"; // 这里填保存的文件名
a.click();
URL.revokeObjectURL(a.href);
a.remove();
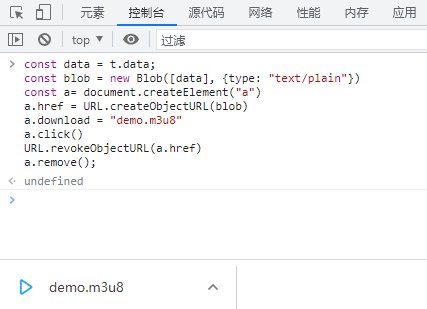
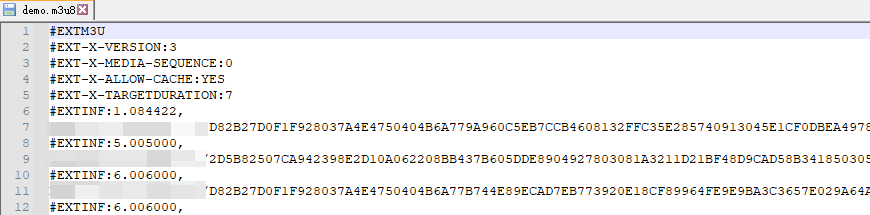
成功保存,打开看看,正好是m3u8的内容:
1.4 ts解密
尝试用IDM访问前面一两个ts链接看看有没有加密:
怎么返回的又是图片?直接打开看看:

啥呀这是,一张花屏的图片,用winhex打开看看:

上下拖动内容后发现并不是常规的图片内容,果然有猫腻,在图片的下面发现了视频相关的头信息,难道这是图片伪装的视频文件?从其它平台找一个正常的ts文件对比看看:
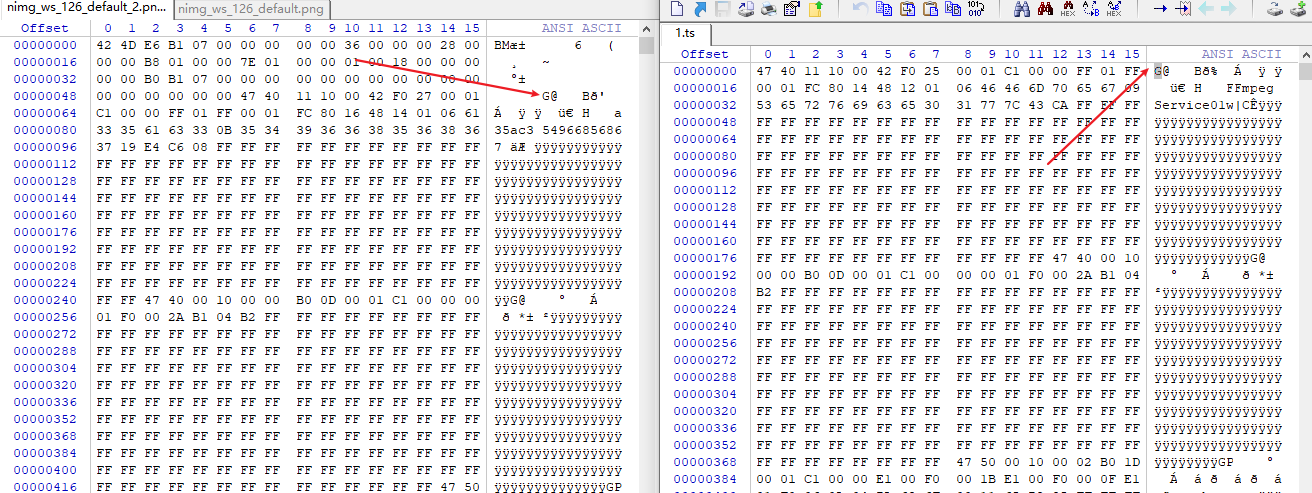
哦豁,原来后面的内容确实是视频文件,只是前面一小部分是BMP文件的头信息,那简单了,直接删了试试:
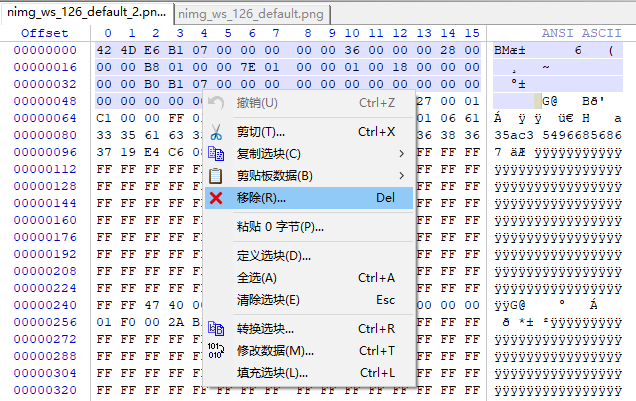
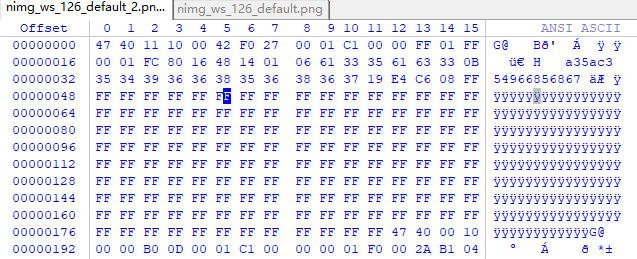
修改后另存为一份,后缀改为ts,避免修改错误导致源文件信息丢失

打开修改后的ts文件,正常播放:

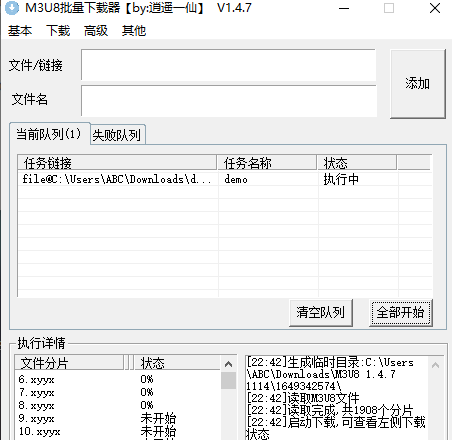
PS:后来发现论坛里,逍遥大佬写的m3u8下载器可以自动去除这种不是ts内容的信息:
至此第一阶段分析结束,我以为也就这样了,但是再尝试打开几个视频后,发发发现居然有不一样的加密!!!
OK,既然被发现了,那必须得再分析看看=>
第二次分析
2.1 获取m3u8和key
有了前面那些踩坑,这次分析起来就快多了,再次尝试打开视频页面,通过调试再次拿到m3u8文件,拖入m3u8下载器看看:
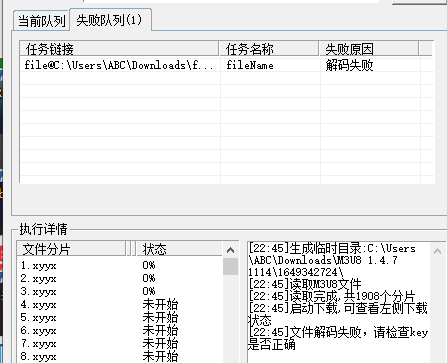
发现这次需要key,通过不断的调试终于hook到key的位置,这里先把key拿来用一下,填入key,发现又解码失败了:
2.2 ts解密
难道这个ts与众不同?打开m3u8文件后发现ts的链接长度明显变短了,下载ts后再次打开文件看看:

又是熟悉的花屏图片,用winhex打开看看:
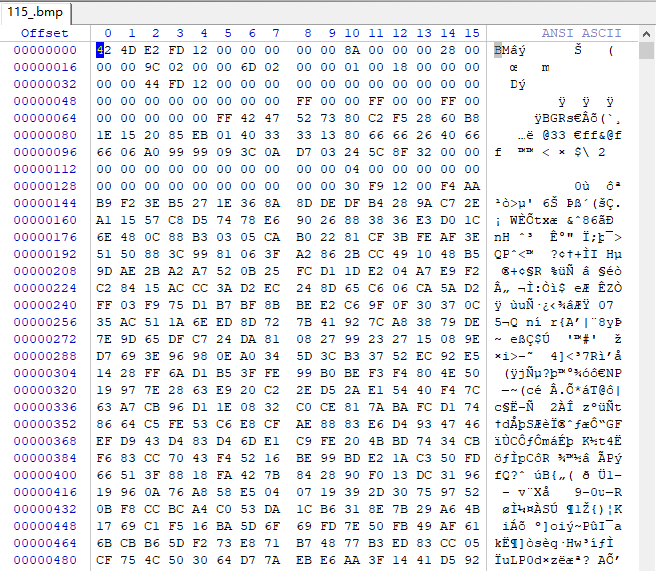
发现这次怎么也找不到ts头信息了,搜也搜不到了,而且内容非常乱,看起来应该是被加密了,这样只能调试代码看看怎么回事了。这次换个方法找,直接搜,为啥呢,因为调试了半天也跳到解密位置,直接搜碰碰运气:
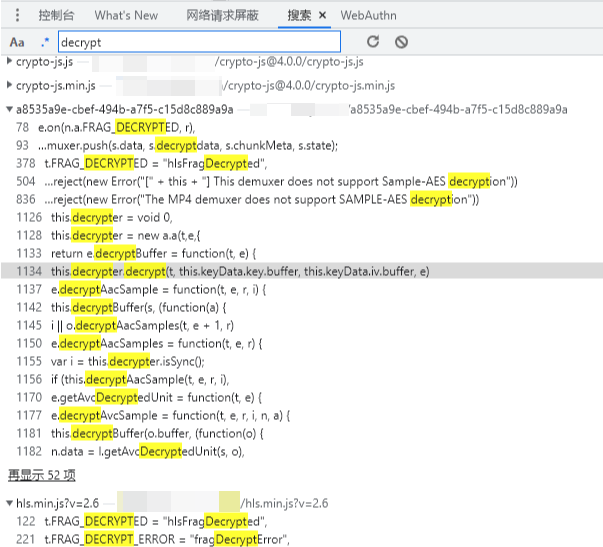
看到有很多结果,前面两个js可以忽略,第3、4个js文件很可疑,打开相应的js再次搜索关键字,发现有很多结果,从上到下依次都大概看一下。然后发现这个位置很可疑,其它地方都没混淆代码,偏偏这里有混淆,此地无银三百两,打上断点试试:
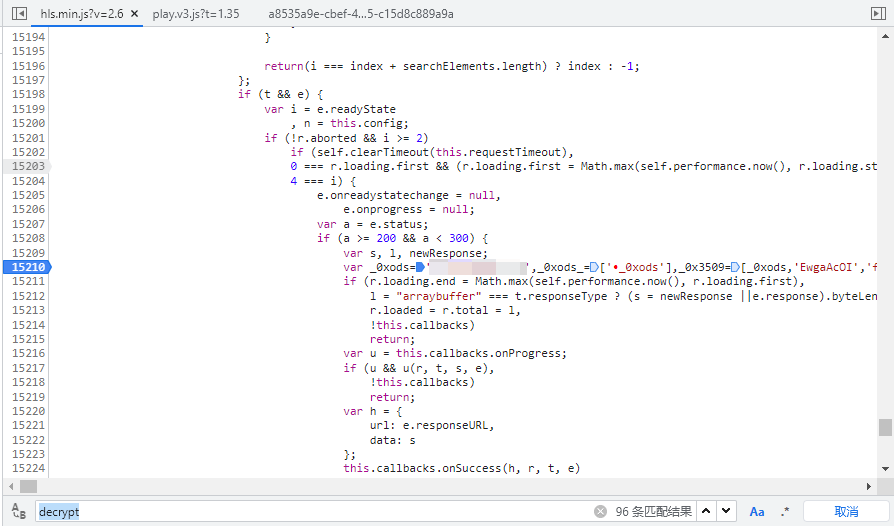
再次F5加载页面或者继续播放,点击格式化后再搜关键字,可以看到代码都被混淆了,但是有些关键信息还是可以看到的:
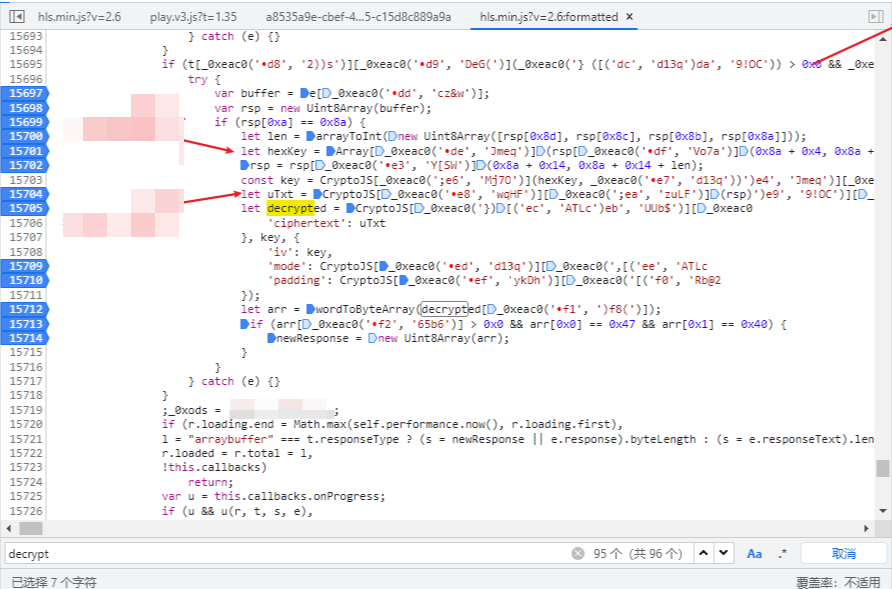
统统打上断点看看,F8依次执行,可以看到rsp就是网站加载的原始ts文件,大小一模一样,这里我从Fiddler保存了一份做对比:
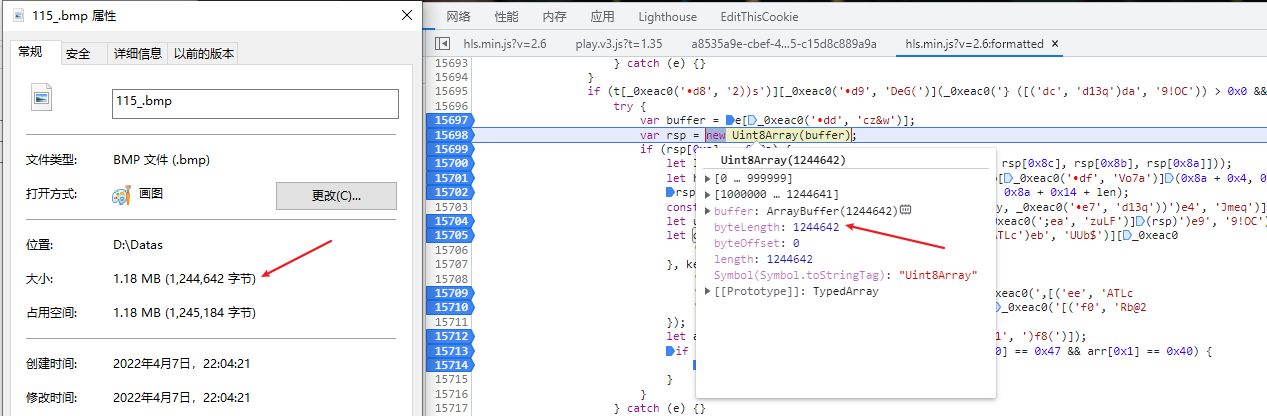
F8继续执行,发现len变量的值为1243440,应该是确定加密范围的:
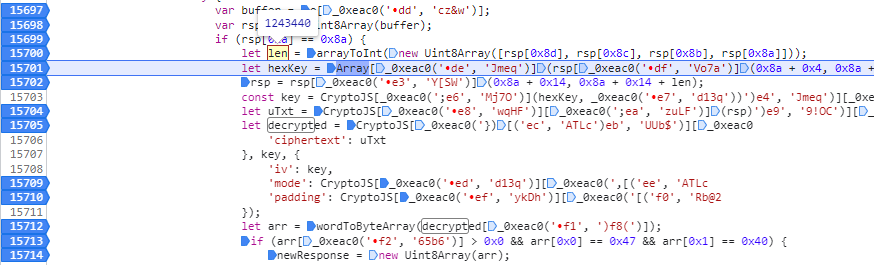
点击继续下一个断点,发现rsp变了,长度不是1244642,而是1243440了:
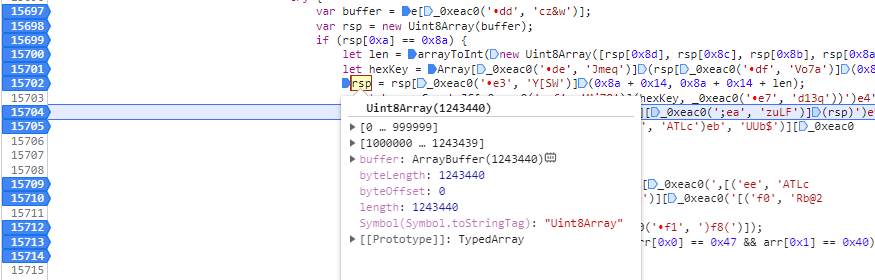
依葫芦画瓢,这里先保存一下rsp内容,此时的rsp是不能播放的:
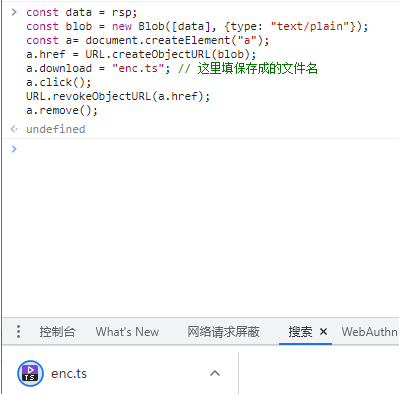
打开本地保存的后缀为.bmp的ts文件和这个enc.ts进行对比,并搜搜看:
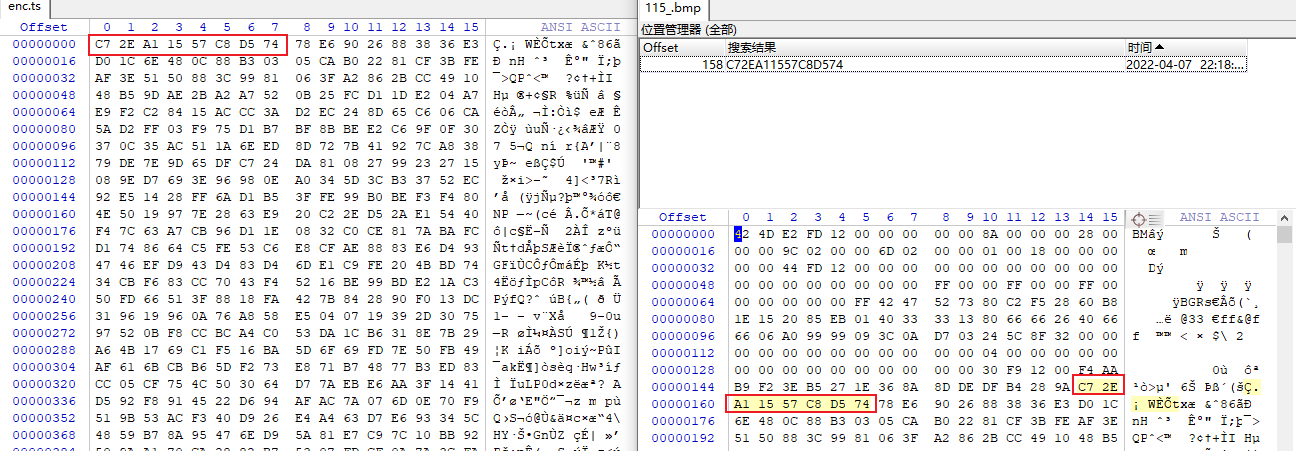
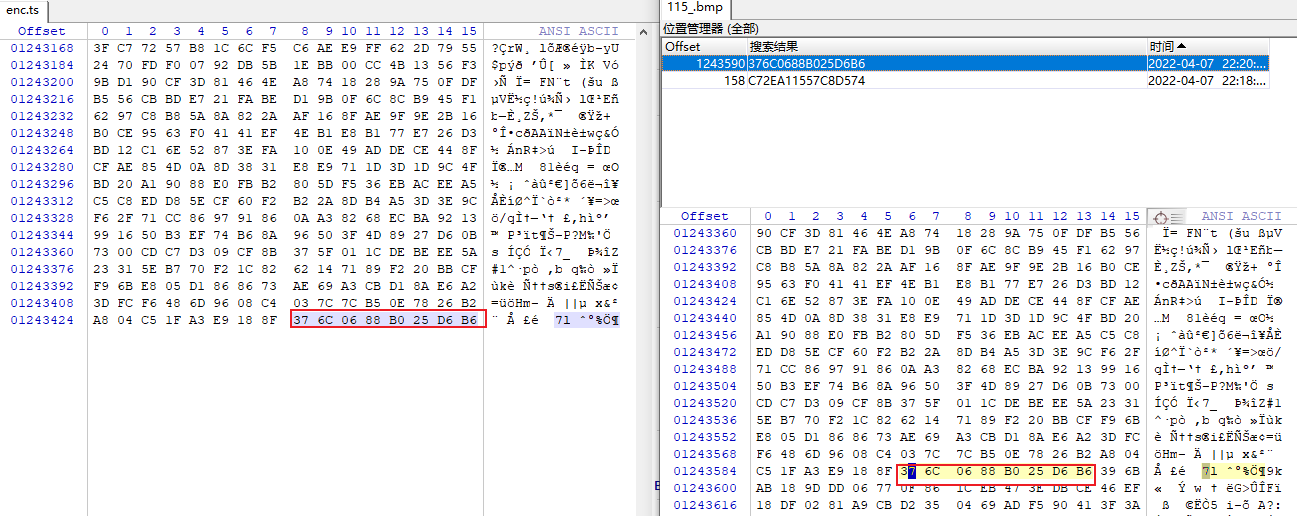
原来是通过一定的算法把前面和后面一部分内容给去掉了,那么剩下的应该就是被加密的视频文件了,删除后大小刚好就是enc.ts的大小。下一个断点,来到uText这个变量,发现这个变量的长度刚好和前面的rsp长度是一样的,这里应该就是做了转换,为解密做准备:
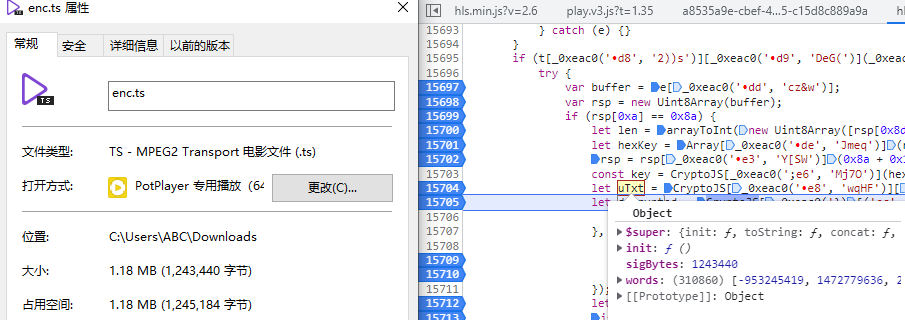
下一个断点,来到解密函数,这里可以清楚看到加密的内容uTxt、key、iv,虽然看不太懂混淆的代码,但这显然是一个标准的AES-CBC解密操作:
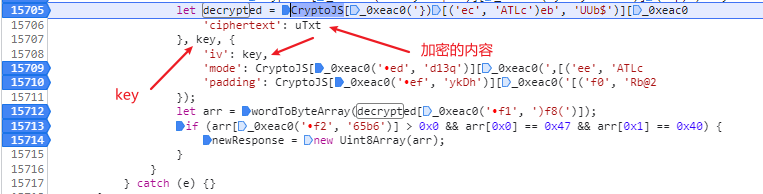
而最后的newRresponse=new Uint8Array(arr);就是解密好的视频流,当然这里可以用代码来实现,这里的key和iv都是同一个值,控制台输出一下:
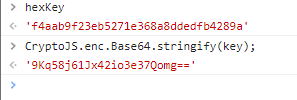
这里用Python代码实现解密:
from Crypto.Cipher import AES
import base64
fr = open(r'enc.ts', 'rb')
content = fr.read()
key = iv = base64.b64decode("9Kq58j61Jx42io3e37Qomg==")
cipher = AES.new(key, AES.MODE_CBC, iv)
data = cipher.decrypt(content)
with open(r'dec.ts', 'wb') as fw:
fw.write(data)
成果展示

总结
通过这次实战见识到了很多花里胡哨的操作,还是相当有收获的。也明白还是需要不断学习才能走的更远,再接再厉!当某种逆向思路不行就得尝试换种思路,还有一点就是逆向一定要有耐心!
不足:
由于还没学会如何使用AST解这些混淆代码,导致看不懂核心逻辑,所以以下问题暂时没有得到解决
[ol]
[/ol]

