1、更新指定链接弹幕
2、更新指定剧集弹幕
3、更新onelist所有弹幕
onelist见:基于alist的影视墙-可加载弹幕
https://www.52pojie.cn/thread-1931639-1-1.html
(出处: 吾爱破解论坛)
获取后会自动上传到alist对应的目录
一、使用教程
为了方便打包exe,我把所有的代码都放在了一个py文件内,所以代码会比较乱
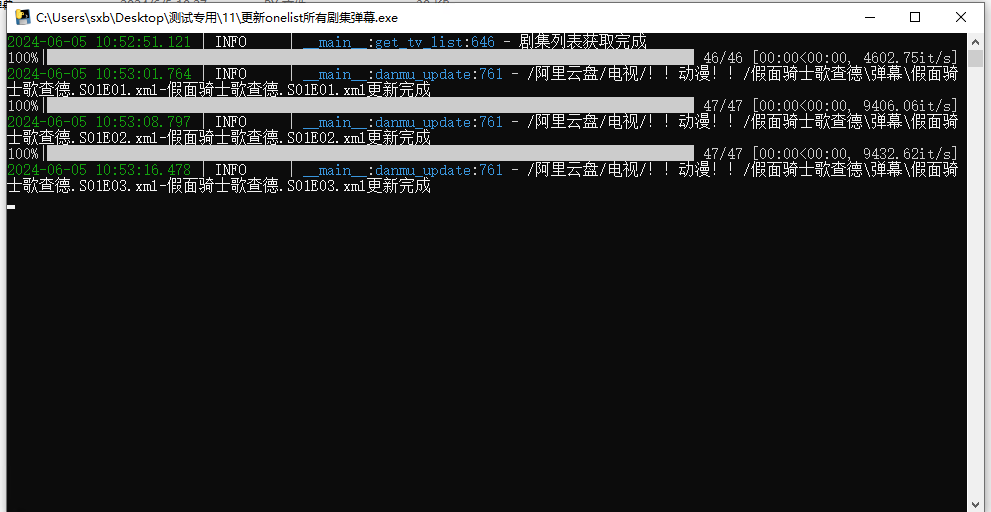
1、使用更新onelist所有弹幕
①、配置config.ini文件
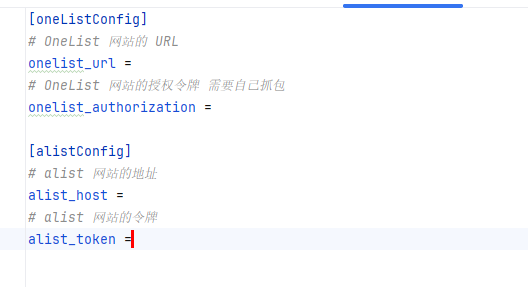
onelist_url:如你在本地搭建的,那么访问网址就是http://127.0.0.1:5246/
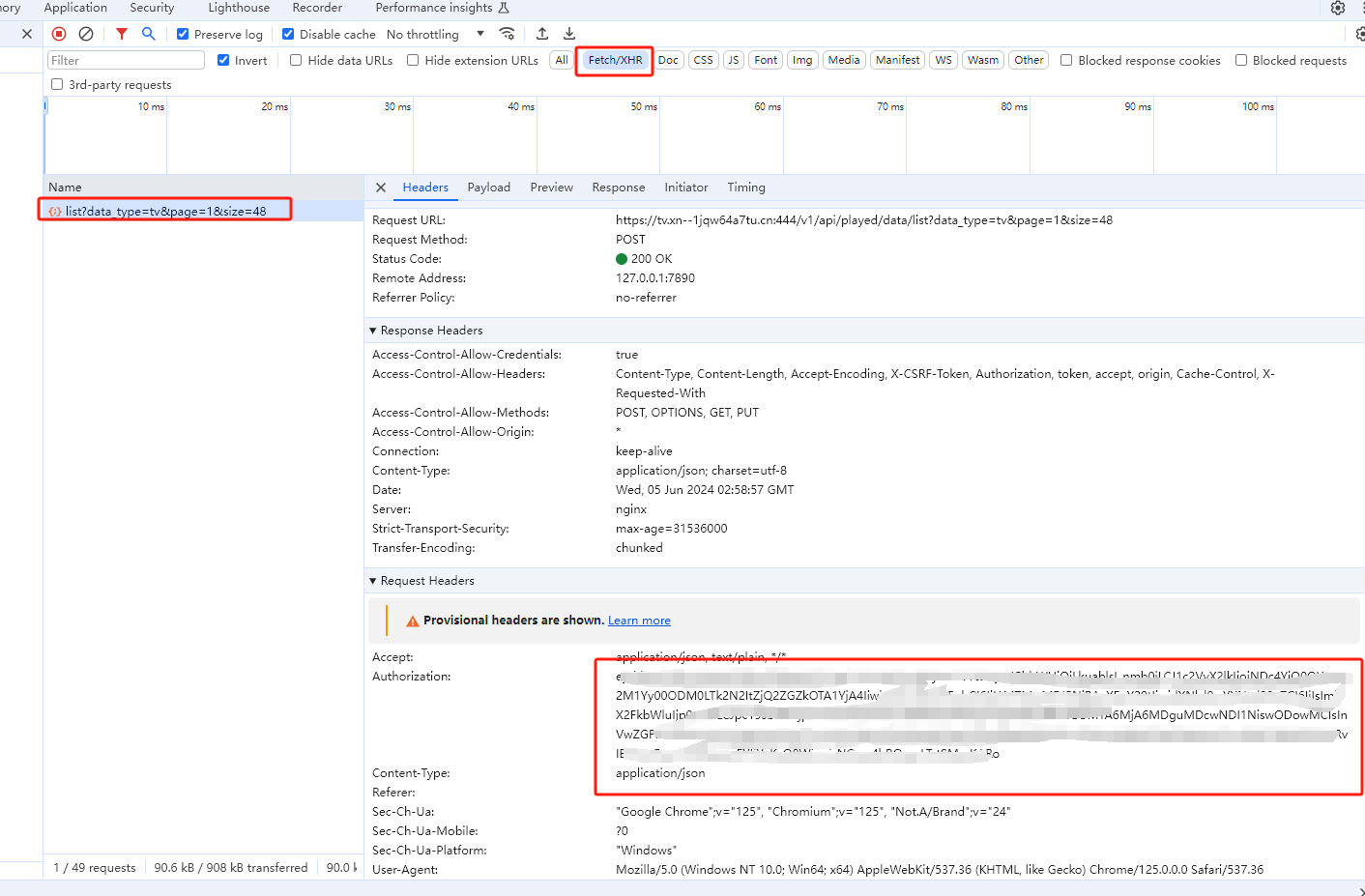
onelist_authorization:抓包获取,F12随便找一个接口就可以看到了
alist_host:alist的主页网址
alist_token:在alist的管理-设置-其他可以看到令牌选项
②、双击exe或运行py文件即可
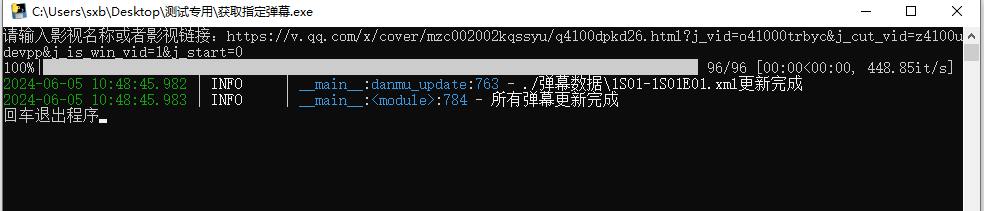
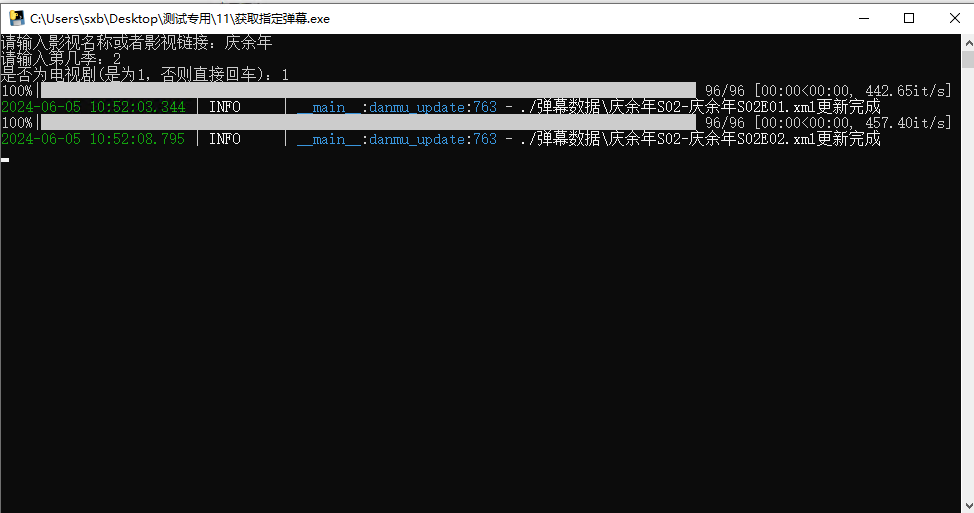
2、更新指定弹幕
双击exe或运行py文件即可
输入影视名的话需要输入第几季和是否为电视剧
第几季为[forecolor=red]数字[/forecolor]
是否为电视剧:电视剧为1.其他直接回车
输入链接直接回车即可,这个链接是影视平台的链接
三、主要代码
# region 弹幕获取相关函数
class GetDanmuBase(object):
base_xml = '''
{}
'''
data_list = []
name = ""
domain = ""
def error(self, msg):
return {
"msg": msg,
"start": 500,
"data": None,
"name": self.name
}
def success(self, data):
return {
"msg": "success",
"start": 0,
"data": data,
"name": self.name
}
def get_data_dict(self):
return dict(
timepoint=0, # 弹幕发送时间(秒)
ct=1, # 弹幕类型,1-3 为滚动弹幕、4 为底部、5 为顶端、6 为逆向、7 为精确、8 为高级
size=25, # 字体大小,25 为中,18 为小
color=16777215, # 弹幕颜色,RGB 颜色转为十进制后的值,16777215 为白色
unixtime=int(time.time()), # Unix 时间戳格式
uid=0, # 发送人的 id
content=""
)
def main(self, url, _type):
"""
获取弹幕的主逻辑
"""
pass
def parse(self, _type):
"""
解析返回的原始数据
:param _type: 数据类型,xml 或 list
"""
pass
def get(self, url, _type='xml'):
self.data_list = []
try:
return self.main(url, _type)
except Exception as e:
return self.error(f"程序出现错误:{traceback.print_exc()}")
def getImg(self, url):
"""
获取弹幕的表情链接
"""
return []
def list2xml(self, data):
xml_str = f' {data.get("content")}'
return xml_str
def time_to_second(self, _time: list):
s = 0
m = 1
for d in _time[::-1]:
s += m * int(d)
m *= 60
return s
class GetDanmuTencent(GetDanmuBase):
name = "腾讯视频"
domain = "v.qq.com"
def __init__(self):
self.api_danmaku_base = "https://dm.video.qq.com/barrage/base/"
self.api_danmaku_segment = "https://dm.video.qq.com/barrage/segment/"
def parse(self, _type):
data_list = []
for data in tqdm(self.data_list):
for item in data.get("barrage_list", []):
_d = self.get_data_dict()
_d['timepoint'] = int(item.get("time_offset", 0)) / 1000
_d["content"] = item.get("content", "")
_d['unixtime'] = item.get('create_time')
if item.get("content_style") != "":
content_style = json.loads(item.get("content_style"))
if content_style.get("color") != "ffffff":
_d['color'] = int(content_style.get("color", "ffffff"), 16)
if _type == "xml":
data_list.append(self.list2xml(_d))
else:
data_list.append(_d)
return data_list
def main(self, url, _type):
self.data_list = []
# res = request_data("GET", url)
# sel = parsel.Selector(res.text)
# title = sel.xpath('//title/text()').get()
# vid = re.findall(f'"title":"{title}","vid":"(.*?)"', res.text)[-1]
# if not vid:
vid = re.search("/([a-zA-Z0-9]+)\.html", url)
if vid:
vid = vid.group(1)
if not vid:
return self.error("解析vid失败,请检查链接是否正确")
res = request_data("GET", urljoin(self.api_danmaku_base, vid))
if res.status_code != 200:
return self.error("获取弹幕详情失败")
for k, segment_index in res.json().get("segment_index", {}).items():
self.data_list.append(
request_data("GET",
urljoin(self.api_danmaku_segment,
vid + "/" + segment_index.get("segment_name", "/"))).json())
parse_data = self.parse(_type)
if _type == 'xml':
return self.base_xml.format('\n'.join(parse_data))
return parse_data
def getImg(self, url):
vid = re.search("/([a-zA-Z0-9]+)\.html", url)
if vid:
vid = vid.group(1)
if not vid:
return self.error("解析vid失败,请检查链接是否正确")
cid = url.split('/')[-2]
data = {
"vid": vid,
"cid": cid,
"lid": "",
"bIsGetUserCfg": True
}
res = request_data("POST",
"https://pbaccess.video.qq.com/trpc.danmu.danmu_switch_comm.DanmuSwitch/getVideoDanmuSwitch",
json=data)
danmukey = res.json().get('data', {}).get('registResultInfo', {}).get('dataKey')
res = request_data("POST", "https://pbaccess.video.qq.com/trpc.message.danmu_richdata.Richdata/GetRichData",
json={
"danmu_key": danmukey,
"vip_degree": 0
},
headers={
'origin': "https://v.qq.com",
'referer': "https://v.qq.com",
})
emoji_infos = res.json().get('data', {}).get('emoji_configs', {}).get('emoji_infos', [])
emoji_data_list = []
for emoji_info in emoji_infos:
emoji_data_list.append(
{
'emoji_code': emoji_info.get('emoji_code'),
'emoji_url': emoji_info.get('emoji_url'),
}
)
return emoji_data_list
class GetDanmuBilibili(GetDanmuBase):
name = "B站"
domain = "bilibili.com"
def __init__(self):
self.api_video_info = "https://api.bilibili.com/x/web-interface/view"
self.api_epid_cid = "https://api.bilibili.com/pgc/view/web/season"
def parsel(self, xml_data):
data_list = re.findall('(.*?)', xml_data)
for data in tqdm(data_list):
_d = self.get_data_dict()
_d['content'] = data[1]
data_time = data[0].split(",")
_d["timepoint"] = float(data_time[0])
_d['ct'] = data_time[1]
_d['size'] = data_time[2]
_d['color'] = data_time[3]
_d['unixtime'] = data_time[4]
_d['uid'] = data_time[6]
self.data_list.append(_d)
return self.data_list
def main(self, url: str, _type):
# 番剧
if url.find("bangumi/") != -1 and url.find("ep") != -1:
epid = url.split('?')[0].split('/')[-1]
params = {
"ep_id": epid[2:]
}
res = request_data("GET", url=self.api_epid_cid, params=params, headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
})
res_json = res.json()
if res_json.get("code") != 0:
return self.error("获取番剧信息失败")
for episode in res_json.get("result", {}).get("episodes", []):
if episode.get("id", 0) == int(epid[2:]):
xml_data = request_data("GET", f'https://comment.bilibili.com/{episode.get("cid")}.xml').text
if _type == 'xml':
return xml_data
else:
return self.parsel(xml_data)
class GetDanmuIqiyi(GetDanmuBase):
name = "爱奇艺"
domain = "iqiyi.com"
def parse(self, _type):
data_list = []
for data in tqdm(self.data_list):
# 解压缩数据
decompressed_data = zlib.decompress(data)
data = decompressed_data.decode('utf-8')
for d in re.findall('.*?', data, re.S):
d_dict = xmltodict.parse(d).get("bulletInfo")
_d = self.get_data_dict()
_d["timepoint"] = int(d_dict.get("showTime"))
_d["content"] = d_dict.get("content")
_d["color"] = int(d_dict.get("color"), 16)
_d["size"] = int(d_dict.get("font"))
if _type == "xml":
data_list.append(self.list2xml(_d))
else:
data_list.append(_d)
return data_list
def main(self, url, _type):
res = request_data("GET", url=url, headers={
"Accept-Encoding": "gzip,deflate,compress"
})
tv_id = re.findall('"tvId":([0-9]+)', res.text)[0]
album_id = int(re.findall('"albumId":([0-9]+)', res.text)[0])
category_id = re.findall('"channelId":([0-9]+)', res.text)[0]
duration = re.findall('"duration":"([0-9]+):([0-9]+)"', res.text)[0]
s = self.time_to_second(duration)
page = round(s / (60 * 5))
for i in range(0, page):
url = f"https://cmts.iqiyi.com/bullet/{tv_id[-4:-2]}/{tv_id[-2:]}/{tv_id}_300_{i + 1}.z"
params = {
'rn': "0.0123456789123456",
'business': "danmu",
'is_iqiyi': "true",
'is_video_page': "true",
'tvid': tv_id,
'albumid': album_id,
'categoryid': category_id,
'qypid': '01010021010000000000',
}
r = request_data("GET", url=url, params=params,
headers={'Content-Type': 'application/octet-stream'}).content
self.data_list.append(r)
parse_data = self.parse(_type)
if _type == "xml":
return self.base_xml.format('\n'.join(parse_data))
return parse_data
class GetDanmuMgtv(GetDanmuBase):
name = "芒果TV"
domain = "mgtv.com"
def __init__(self):
self.api_video_info = "https://pcweb.api.mgtv.com/video/info"
self.api_danmaku = "https://galaxy.bz.mgtv.com/rdbarrage"
def parse(self, _type):
data_list = []
for data in tqdm(self.data_list):
if data.get("data", {}).get("items", []) is None:
continue
for d in data.get("data", {}).get("items", []):
_d = self.get_data_dict()
_d['timepoint'] = d.get('time', 0) / 1000
_d['content'] = d.get('content', '')
_d['uid'] = d.get('uid', '')
if _type == "xml":
data_list.append(self.list2xml(_d))
else:
data_list.append(_d)
return data_list
def main(self, url, _type):
_u = url.split(".")[-2].split("/")
cid = _u[-2]
vid = _u[-1]
params = {
'cid': cid,
'vid': vid,
}
res = request_data("GET", url=self.api_video_info, params=params)
_time = res.json().get("data", {}).get("info", {}).get("time")
end_time = self.time_to_second(_time.split(":")) * 1000
for _t in range(0, end_time, 60 * 1000):
self.data_list.append(
request_data("GET", self.api_danmaku, params={
'vid': vid,
"cid": cid,
"time": _t
}).json()
)
parse_data = self.parse(_type)
if _type == "xml":
return self.base_xml.format('\n'.join(parse_data))
return parse_data
class GetDanmuYouku(GetDanmuBase):
name = "优酷"
domain = "v.youku.com"
def __init__(self):
self.req = requests.Session()
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
@retry(stop_max_attempt_number=5, wait_random_min=1000, wait_random_max=2000)
def request_data(self, method, url, status_code=None, **kwargs):
"""
发送请求
:param method: 请求方式
:param url: 请求URL
:param status_code: 成功的状态码
:param kwargs:
:return:
"""
res = self.req.request(method, url, **kwargs)
# res.encoding = res.apparent_encoding
if status_code:
if res.status_code == status_code:
return res
else:
return
return res
def get_cna(self):
url = "https://log.mmstat.com/eg.js"
res = self.request_data("GET", url, headers=self.headers)
def get_tk_enc(self):
res = self.request_data("GET",
"https://acs.youku.com/h5/mtop.com.youku.aplatform.weakget/1.0/?jsv=2.5.1&appKey=24679788",
headers=self.headers)
if '_m_h5_tk' in res.cookies.keys() and '_m_h5_tk_enc' in res.cookies.keys():
return True
return False
def get_vinfos_by_video_id(self, video_id):
url = "https://openapi.youku.com/v2/videos/show.json"
params = {
'client_id': '53e6cc67237fc59a',
'video_id': video_id,
'package': 'com.huawei.hwvplayer.youku',
'ext': 'show',
}
res = self.request_data("GET", url, params=params, headers=self.headers)
return res.json().get('duration')
def get_msg_sign(self, msg_base64):
secret_key = 'MkmC9SoIw6xCkSKHhJ7b5D2r51kBiREr'
combined_msg = msg_base64 + secret_key
hash_object = hashlib.md5(combined_msg.encode())
return hash_object.hexdigest()
def yk_t_sign(self, token, t, appkey, data):
text = '&'.join([token, t, appkey, data])
md5_hash = hashlib.md5(text.encode())
return md5_hash.hexdigest()
def parse(self, _type):
data_list = []
for data in tqdm(self.data_list):
result = json.loads(data.get('data', {}).get('result', {}))
if result.get('code', '-1') == '-1':
continue
danmus = result.get('data', {}).get('result', [])
for danmu in danmus:
_d = self.get_data_dict()
_d['timepoint'] = danmu.get('playat') / 1000
_d['color'] = json.loads(danmu.get('propertis', '{}')).get('color', _d['color'])
_d['content'] = danmu.get('content')
if _type == "xml":
data_list.append(self.list2xml(_d))
else:
data_list.append(_d)
return data_list
def main(self, url, _type):
self.get_cna()
self.get_tk_enc()
video_id = url.split('?')[0].split('/')[-1].replace("id_", '').split('.html')[0]
max_mat = self.get_vinfos_by_video_id(video_id)
for mat in range(0, int(float(max_mat) / 60) + 1):
url = "https://acs.youku.com/h5/mopen.youku.danmu.list/1.0/"
msg = {
'ctime': int(time.time() * 1000),
'ctype': 10004,
'cver': 'v1.0',
'guid': self.req.cookies.get('cna'),
'mat': mat,
'mcount': 1,
'pid': 0,
'sver': '3.1.0',
'type': 1,
'vid': video_id
}
msg['msg'] = base64.b64encode(json.dumps(msg).replace(' ', '').encode('utf-8')).decode('utf-8')
msg['sign'] = self.get_msg_sign(msg['msg'])
t = int(time.time() * 1000)
params = {
'jsv': '2.5.6',
'appKey': '24679788',
't': t,
'sign': self.yk_t_sign(self.req.cookies.get('_m_h5_tk')[:32], str(t), '24679788',
json.dumps(msg).replace(' ', '')),
'api': 'mopen.youku.danmu.list',
'v': '1.0',
'type': 'originaljson',
'dataType': 'jsonp',
'timeout': '20000',
'jsonpIncPrefix': 'utility'
}
headers = self.headers.copy()
headers['Content-Type'] = 'application/x-www-form-urlencoded'
headers['Referer'] = 'https://v.youku.com'
res = self.request_data("POST", url, data={"data": json.dumps(msg).replace(' ', '')}, headers=headers,
params=params)
self.data_list.append(res.json())
parse_data = self.parse(_type)
if _type == "xml":
return self.base_xml.format('\n'.join(parse_data))
return parse_data
# endregion
下载链接:https://shuxiaobai.lanzouw.com/i60FY20vtvfe
