ES 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
面试官心理分析
在涉及 Elasticsearch (简称 ES )的应用场景中,性能问题往往是一个不可回避的话题。尽管 ES 是一个强大的分布式搜索和分析引擎,但其实际性能并不总是如人们想象的那么理想。特别是在处理大规模数据集时,如几亿条记录,开发者可能会遇到一些令人头疼的性能瓶颈。
一个常见的体验是,在进行第一次搜索查询时,响应时间可能会达到 5 到 10 秒,这对于用户来说无疑是一个糟糕的体验。然而,令人困惑的是,随后的查询通常会变得非常快,可能只需要几百毫秒。这种差异可能会让开发者感到困惑,为什么第一次查询会如此缓慢,而后续的查询则能迅速完成?
这种现象背后的原因可能涉及 ES 的多种机制,包括索引的创建、缓存的使用、数据在集群中的分布等。对于没有实际 ES 使用经验或仅通过演示程序了解 ES 的开发者来说,面对这样的性能问题时,可能会感到不知所措。这种反应可能会让面试官或技术团队怀疑开发者对 ES 的实际应用能力和深入理解。
因此,在准备使用 ES 或面试涉及 ES 的职位时,了解并熟悉其性能特点、优化策略和实际应用中的常见问题是非常重要的。这样,当面对性能挑战时,开发者能够迅速找到问题的根源并采取有效的措施来解决它,从而确保 ES 能够在生产环境中提供稳定、高效的搜索和分析功能。
面试题剖析
Elasticsearch ( ES )的性能优化是一个复杂且多维度的任务,它没有一种“银弹”解决方案,可以简单地通过调整一个参数或改变语法来应对所有性能问题。这意味着,在面对 ES 性能挑战时,我们不能依赖单一、快速的解决方案来解决所有问题。
实际上,ES 的性能优化是一个涉及多个方面的综合过程。它可能包括调整索引设计、优化查询语句、增加硬件资源、调整集群配置、利用缓存机制、监控和分析瓶颈等多个方面。每个场景的性能问题可能都有其特定的原因和解决方案,因此,我们需要对 ES 的工作原理和性能特点有深入的理解,才能有效地解决性能问题。
此外,ES 的性能优化也需要考虑到业务场景和需求。不同的业务场景可能对性能有不同的要求,因此,我们需要在理解业务需求的基础上,有针对性地进行性能优化。
内存与磁盘的博弈
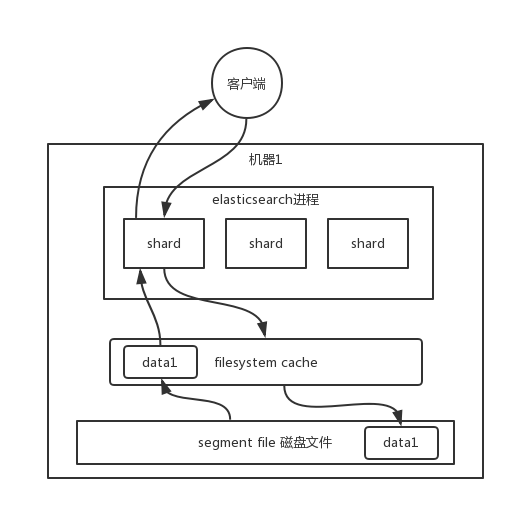
Elasticsearch 的搜索引擎性能在很大程度上依赖于底层的filesystem cache。简而言之,当你向 Elasticsearch 中写入数据时,这些数据最终会被存储在磁盘上的文件中。但是,当这些文件被读取以响应查询时,操作系统会智能地将这些文件的内容缓存到filesystem cache中,这样后续的读取操作就可以直接从内存中完成,从而大大提高了性能。
这种内存与磁盘的交互对性能的影响是巨大的。如果我们考虑一个场景,其中 Elasticsearch 的数据完全位于磁盘上,每次查询都可能涉及到磁盘 I/O ,那么查询性能可能会受到严重的限制,搜索可能需要几秒甚至更长的时间来完成。相反,如果数据已经被加载到filesystem cache中,并且查询可以完全在内存中执行,那么性能通常会提高一个数量级,查询时间可以从毫秒级别完成。
然而,filesystem cache的大小是有限的,这通常取决于可用的物理内存。如果索引数据文件的大小超过了可用内存,那么只有部分数据能够被缓存,而其他数据则必须从磁盘读取,这会导致性能下降。
为了确保 Elasticsearch 的最佳性能,理想的情况是将机器的内存配置为至少可以容纳总数据量的一半。这样,大部分数据都可以被缓存在内存中,从而提高查询性能。
此外,优化写入 Elasticsearch 的数据也很重要。只存储那些真正需要用于搜索的字段,而不是整个数据行的所有字段。这可以减少单条数据的大小,从而允许filesystem cache缓存更多的数据。
在实际应用中,结合使用 Elasticsearch 和其他存储解决方案(如 HBase )是一种常见的做法。Elasticsearch 用于高效的搜索和检索操作,而 HBase 或其他类似的存储系统则用于存储和检索完整的数据记录。通过这种方式,可以充分利用各自的优势,实现高性能的搜索和数据存储。
数据预热策略
即使在遵循最佳实践并优化了 Elasticsearch 集群的内存分配后,仍然可能会遇到数据量超过filesystem cache容量的情况。这意味着部分数据将驻留在磁盘上,而不是在内存中,从而可能降低查询性能。在这种情况下,一个有效的策略是实施数据预热。
数据预热是指通过预先加载和缓存预期会被频繁访问的数据,从而优化系统性能的过程。在 Elasticsearch 的上下文中,这意味着在数据实际被用户查询之前,通过后台系统或进程主动触发对这些数据的访问,使它们被加载到filesystem cache中。
以社交媒体平台为例,大 V 用户或热门话题通常会吸引大量用户的关注。通过后台系统定期(如每隔一段时间)对这些热门内容进行搜索或访问,可以确保它们的数据被加载到内存缓存中。当真实用户发起对这些内容的查询时,由于数据已经在缓存中,查询将迅速得到响应,从而提升了用户体验。
同样,在电子商务网站中,热门商品或高流量商品页面也可以采用这种预热策略。通过后台程序定期访问这些商品的数据,可以确保它们被缓存在内存中,从而加快用户的搜索和浏览速度。
为了实施这一策略,可以开发一个专门的缓存预热子系统。这个子系统可以基于历史数据访问模式、用户行为分析或实时流量统计来确定哪些数据是“热门”的。然后,它可以定期或基于触发条件(如数据更新)来主动访问这些数据,使它们保持在filesystem cache中。
需要注意的是,数据预热策略并不是万能的。它可能不适用于所有场景,特别是当数据访问模式非常动态或不可预测时。此外,过度预热也可能导致缓存污染,即不常用的数据占据了宝贵的缓存空间。因此,在实施预热策略时,需要根据具体的应用场景和需求进行权衡和调整。
冷热分离策略
Elasticsearch 可以借鉴 MySQL 的水平拆分策略,通过数据冷热分离来提高性能。这意味着将频繁访问的“热”数据与访问频率较低的“冷”数据分别存储在不同的索引中。这种策略有助于确保热数据常驻于 filesystem cache 中,从而避免被冷数据冲刷掉。
在实际部署中,如果你有 6 台机器的资源,可以创建两个索引:一个专门用于存储热数据,另一个用于存储冷数据。每个索引可以分为 3 个 shard ,并且分别部署在 3 台不同的机器上。这样,热数据索引将部署在 3 台机器上,而冷数据索引则部署在另外 3 台机器上。
由于热数据通常只占总数据量的很小一部分(例如 10%),这些数据可以几乎完全保留在 filesystem cache 中。这意味着当大多数用户都在访问热数据时,这些请求可以非常快速地得到响应,因为所需的数据都在内存中。
相比之下,冷数据索引可能包含大量不常访问的数据。当用户需要访问这些数据时,由于它们不太可能被缓存在内存中,因此可能需要从磁盘读取。但由于只有较少的用户(例如 10%)会访问冷数据,因此这种性能下降对整体系统性能的影响相对较小。
通过实施数据冷热分离策略,您可以优化 Elasticsearch 集群的性能,确保热数据的高效访问,同时平衡冷数据的存储和访问需求。这种策略在许多实际场景中都是有效的,特别是当您需要处理大量数据并希望优化最常用数据的访问性能时。
复杂关联查询与数据模型设计
在关系型数据库如 MySQL 中,复杂的关联查询是非常常见的。然而,在 Elasticsearch (简称 ES )这样的 NoSQL 数据库中,复杂的关联查询通常不被推荐,因为它们的性能通常不如在关系型数据库中。Elasticsearch 是为了高效的全文搜索和聚合而设计的,而不是为了复杂的关联查询。
因此,当涉及到需要在多个文档或索引之间进行关联查询的场景时,最佳的做法是在数据写入 Elasticsearch 之前,在应用程序层面(如使用 Java )就已经完成了必要的关联操作。这意味着你应该在应用程序中执行必要的数据库查询,将关联的数据组装成合适的格式,然后将这些数据作为单个文档写入 Elasticsearch 。
在 Elasticsearch 中,文档( document )是数据的基本单位,每个文档都是一个 JSON 对象。设计良好的文档模型对于提高 Elasticsearch 的性能至关重要。你应该尽量避免在搜索时执行复杂的、Elasticsearch 不擅长的操作。这意味着在数据写入 Elasticsearch 时,你应该考虑好如何组织数据,以便在后续的搜索和聚合操作中能够高效地利用这些数据。
对于某些确实需要在 Elasticsearch 中执行的操作,例如 join 、nested 或 parent-child 关系,也应该谨慎使用。这些操作在 Elasticsearch 中的性能通常不如简单的搜索和聚合操作。如果可能的话,最好通过重新设计数据模型或查询逻辑来避免使用这些复杂的操作。
总之,在使用 Elasticsearch 时,应该充分利用其擅长的全文搜索和聚合功能,并在数据模型设计和查询逻辑上做出相应的调整,以最大程度地提高性能和效率。
分页查询的性能问题与解决方案
Elasticsearch (简称 ES )作为一个分布式搜索和分析引擎,虽然提供了强大的全文搜索和聚合功能,但在处理深度分页查询时却经常遇到性能瓶颈。这是因为 ES 的分页机制是基于“from + size”的方式实现的,当查询的页数较深时,会导致大量的数据被加载到协调节点进行合并和处理,从而显著增加了查询的延迟。
以每页 10 条数据为例,当查询第 100 页时,ES 实际上会从每个分片( shard )上获取前 1000 条数据,如果集群中有 5 个分片,那么就需要获取 5000 条数据到协调节点。协调节点需要对这些数据进行排序、筛选等操作,然后再次进行分页,最终返回第 100 页的 10 条数据。随着查询页数的增加,每个分片返回的数据量也会增加,协调节点处理的时间也会相应增长,导致查询性能下降。
这种性能问题在实际应用中非常常见。例如,在某些场景下,用户可能需要翻阅大量的数据页,而随着页数的增加,查询的延迟也会逐渐增加,严重影响了用户体验。
为了解决这个问题,可以采取以下几种策略:
[ol]
[/ol]
综上所述,虽然 ES 在处理深度分页查询时存在性能问题,但通过合理的策略和优化,仍然可以有效地提高查询性能并满足实际应用需求。
数据, 查询, 性能, FileSystem
