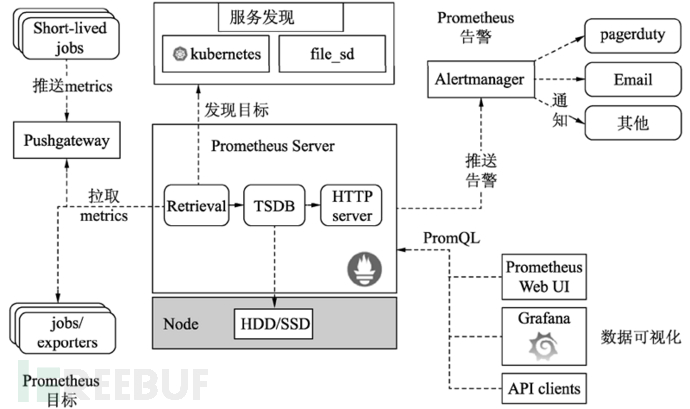
Prometheus 是一个开源的系统监控和警报工具包,用于收集和存储时间序列数据,包括指标信息、记录时间戳以及可选的键值对标签。许多公司使用 Prometheus 监控 K8s 集群。
2. 合适与不合适场景
合适场景
Prometheus 适用于记录各种数字时间序列,既适用于以机器为中心的监控,也适用于监控高度动态的面向服务的架构。在微服务环境中,其对多维数据收集和查询的支持是特别优势。设计用于可靠性,在中断期间仍可使用,能够快速诊断问题。每个 Prometheus 服务器都是独立的,不依赖于网络存储或其他远程服务。在基础设施的其他部分受损时,可以依赖 Prometheus ,而无需设置大量基础设施即可使用。
不合适场景
如果需要 100%准确性,例如按请求计费时,Prometheus 可能不太适合。在这种情况下,最好使用其他系统来收集和分析数据以进行计费。
3. 数据模型
由于监控数量庞大,Prometheus 采用了时间序列数据存储,即带有时间戳和值的数据。
3.1 Prometheus 本地存储:
Prometheus 的本地存储被称为 Prometheus TSDB (时间序列数据库)。TSDB 的设计核心包括两个主要部分:block 和 WAL 。
3.2 Prometheus 数据模型:
Prometheus 将监控数据存储为时间序列,包括标签(键值对)、时间戳和最终的值。表示法如下:
[{,}]
4. 指标
4.1 Counter
Counter 是指 Prometheus 实例接收的数据包总数。该指标一直在增加,用于计量累计事件的次数。
4.2 Gauge
Gauge 是一种测量指标,它在收集时对给定的测量进行快照,并可以增加或减少。例如,温度、磁盘空间、内存使用量等都可以使用 Gauge 进行测量。
4.3 Histogram
Histogram 常用于观察某时间段内的百分比或请求数量。一个 Histogram 包含合并的值,用于描述事件的分布。
5. 指标的摘要和聚合
5.1 指标摘要
单个指标对于我们来说价值较小,通常需要联合并可视化多个指标。这涉及一些数学变换,例如统计函数应用于指标或指标组。常见函数包括计数、求和、平均值、中位数、百分位数、标准差、变化率等。
5.2 指标聚合
指标聚合提供了来自多个源的指标的综合视图,使得整体系统状态更加清晰可见。
6. NodeExporter 部署
Prometheus 使用 exporter 工具来暴露主机和应用程序上的指标。NodeExporter 是一种用于暴露主机相关指标的工具,有多种类型的 exporter 可供选择。
7. cAdvisor 监控 Docker 容器
cAdvisor ( Container Advisor )是由谷歌开发的项目,用于收集、聚合、分析和导出运行中容器的数据。该工具提供丰富的数据,涵盖从内存限制到 GPU 指标等几乎所有可能需要的内容。cAdvisor 通过容器守护进程和 Linux cgroups 收集数据,与 Docker 容器的发现透明且完全自动化。除了以 Prometheus 格式公开指标外,cAdvisor 还提供了一个有用的 Web 界面,可视化展示主机及其容器的状态。
8. 捕获目标生命周期
[ol]
[/ol]
9. PromQL 查询语言
9.1 选择器和标签匹配器:
选择器
示例:
$ prometheus_build_info{version="2.17.0"}
标签匹配器
范围、偏移、子查询
PromQL 操作符
PromQL 函数
10. 计算 CPU 使用率
示例:avg(irate(node_cpu_seconds_total{job="node"}[5m] by (instance) * 100))
11. 计算 CPU 负载(饱和度)
要监控 CPU 饱和度,跟踪平均负载是一种方法。公式将 1 分钟负载与 CPU 数量的两倍进行比较。
示例:
promQLCopy codenode_load1 > on (instance) 2 * count by (instance)(node_cpu_seconds_total{mode="idle"})
12. 计算内存使用率
使用 Node Exporter 的内存指标可计算内存使用百分比。
示例:
promQLCopy code (总内存 - 可用内存 - 缓冲 - 缓存)/ 总内存 * 100
13. 计算内存饱和度
通过检查读写活动来监控内存饱和度。使用 node_vmstat_pswpin和 node_vmstat_pswpout指标。
示例:
promQLCopy code1024 * sum by (instance) ((rate(node_vmstat_pswpin[1m]) + rate(node_vmstat_pswpout[1m])))
14. 磁盘使用率
仅测量磁盘空间使用情况而不是速率、饱和度或错误。这是因为在大多数情况下,这是最有用的可视化和警报数据。
示例:
promQLCopy code(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
根据特定挂载点进行自定义:
promQLCopy code(node_filesystem_size_bytes{mountpoint="/data"} - node_filesystem_free_bytes{mountpoint="/data"}) / node_filesystem_size_bytes{mountpoint="/data"} * 100
15.预测磁盘空间耗尽
预测磁盘空间是否在未来四小时内耗尽。
示例:
promQLCopy codepredict_linear(node_filesystem_free_bytes{mountpoint="/
span, prometheus, 指标, mountpoint
