反爬例子
来看几个例子:
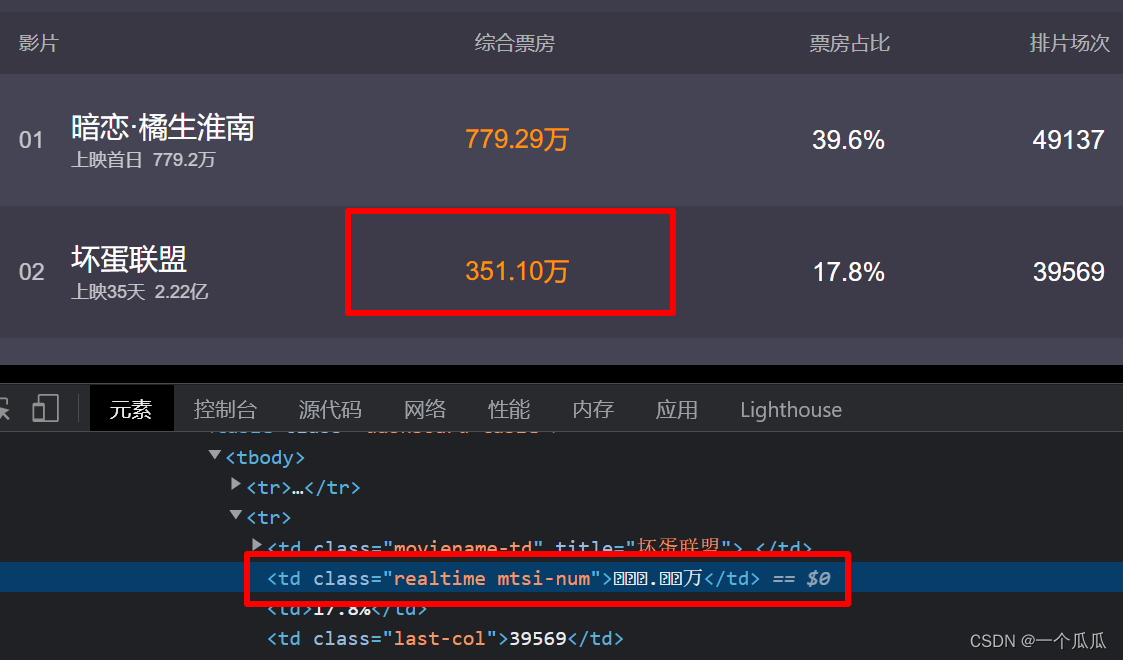
其中处理比较好的是汽车之家的字体反爬,一起来看一下他的处理。以下是他页面的源码,可以看到,font文字是空白的,不容易分析出特征,你去读取他字体文件的时候,是没有unicode码的,不过呢,他强任他强,这不妨碍我们的破解工作。文末会说一下我对某车之家的处理,仅供参考

我们再来对比其他的。
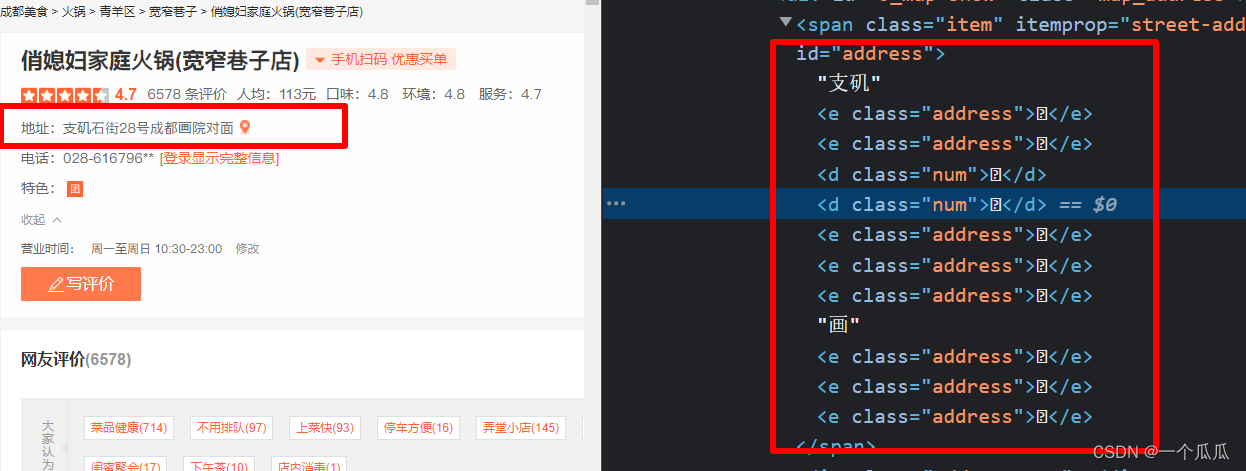
下面是大众点评的处理,可以看到他用的是unicode图标,没有对字符特征做处理

以上就是对字体反爬的简(敷)单(衍)介绍,直接进入正题。
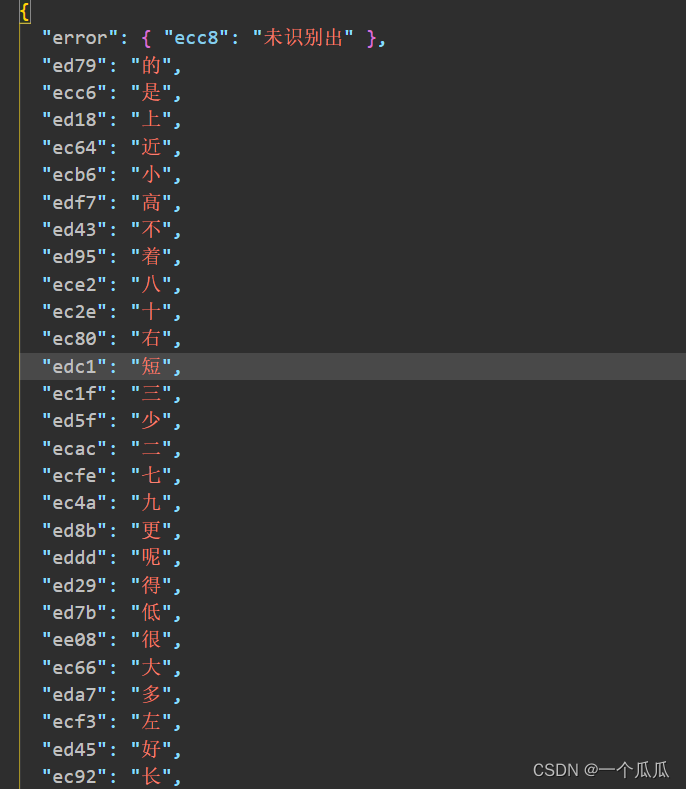
破解的思路,就是将他的unicode和真实字符做匹配,要处理字符图标的识别,要记录下识别出的结果和unicode编码
这里提供一个我写的前端解决方案:https://gitcode.net/weixin_45307278/unicode2font
可以通用到所有网站,原理就是1、拿到字符图片,2、识别字符图片,3、记录,4、保存
目前市场上对字体反爬的处理手段,大部分都是用的python作为主要语言对字体文件进行操作,对unicode编码识别,放到前端处理,其实也是一样的。
准备工作
1,如果你要自动获取token,参看这种方法
制作一个跨域浏览器,因为获取token的接口是跨域的,项目默认是自动获取token的。不会制作跨域浏览器的可以去百度,很简单
2,不需要自动获取token
对于这种方法,随便使用哪个浏览器都可以,不过要使用Postman的工具获取百度的AccessToken,然后写死到项目的access_token参数就好,下面逻辑不用动,只需要赋值就好了,逻辑已经做了处理

项目地址
https://gitcode.net/weixin_45307278/unicode2font
项目介绍
先介绍一下这个项目,这个项目我是爬取的一个字体文件在线浏览网站的源码,然后在他的基础上进行了二次开发,他的功能是对字体文件文字查看和修改,字体文件一键打开即可查看字体的编码和字符图案。
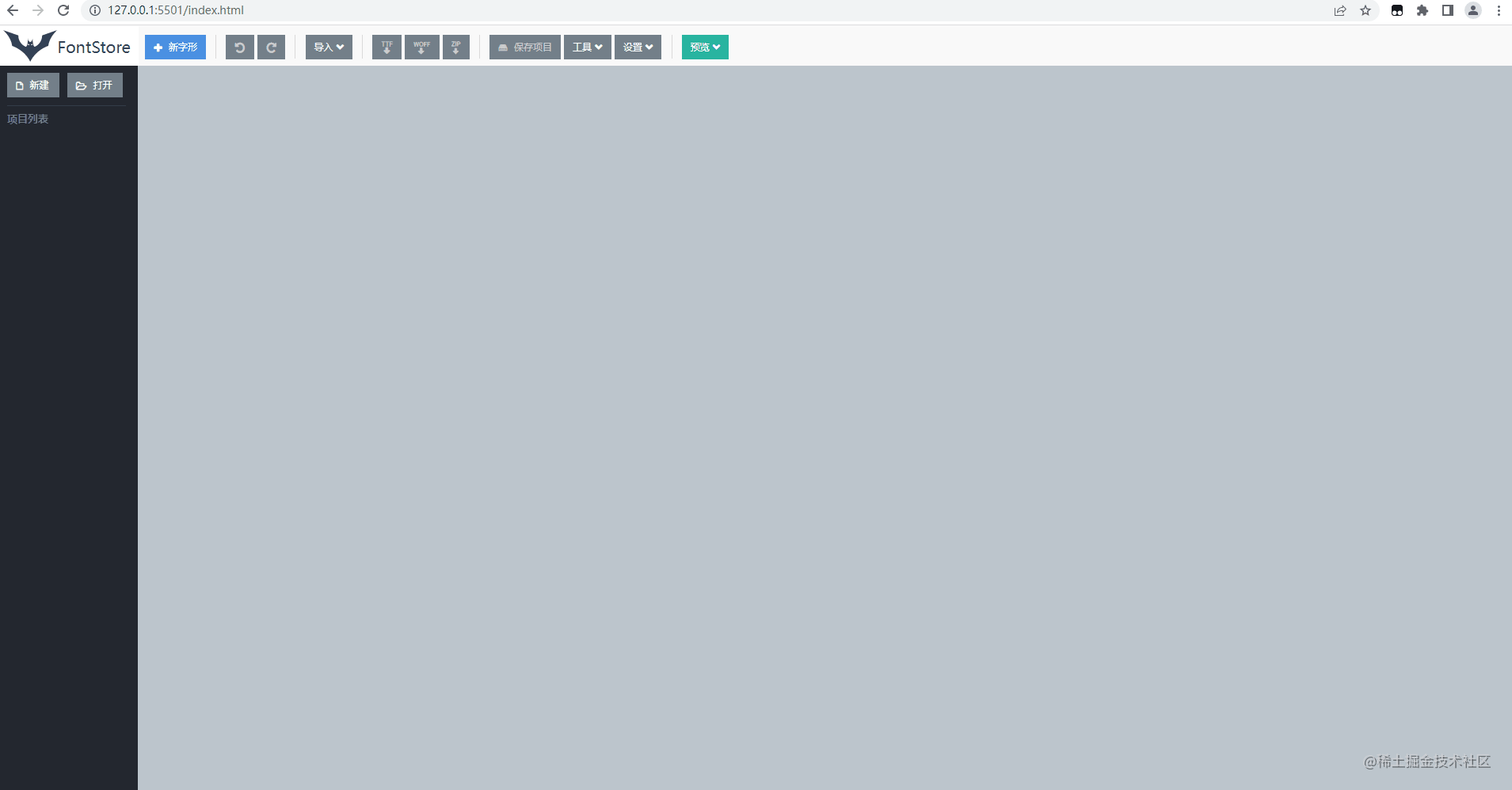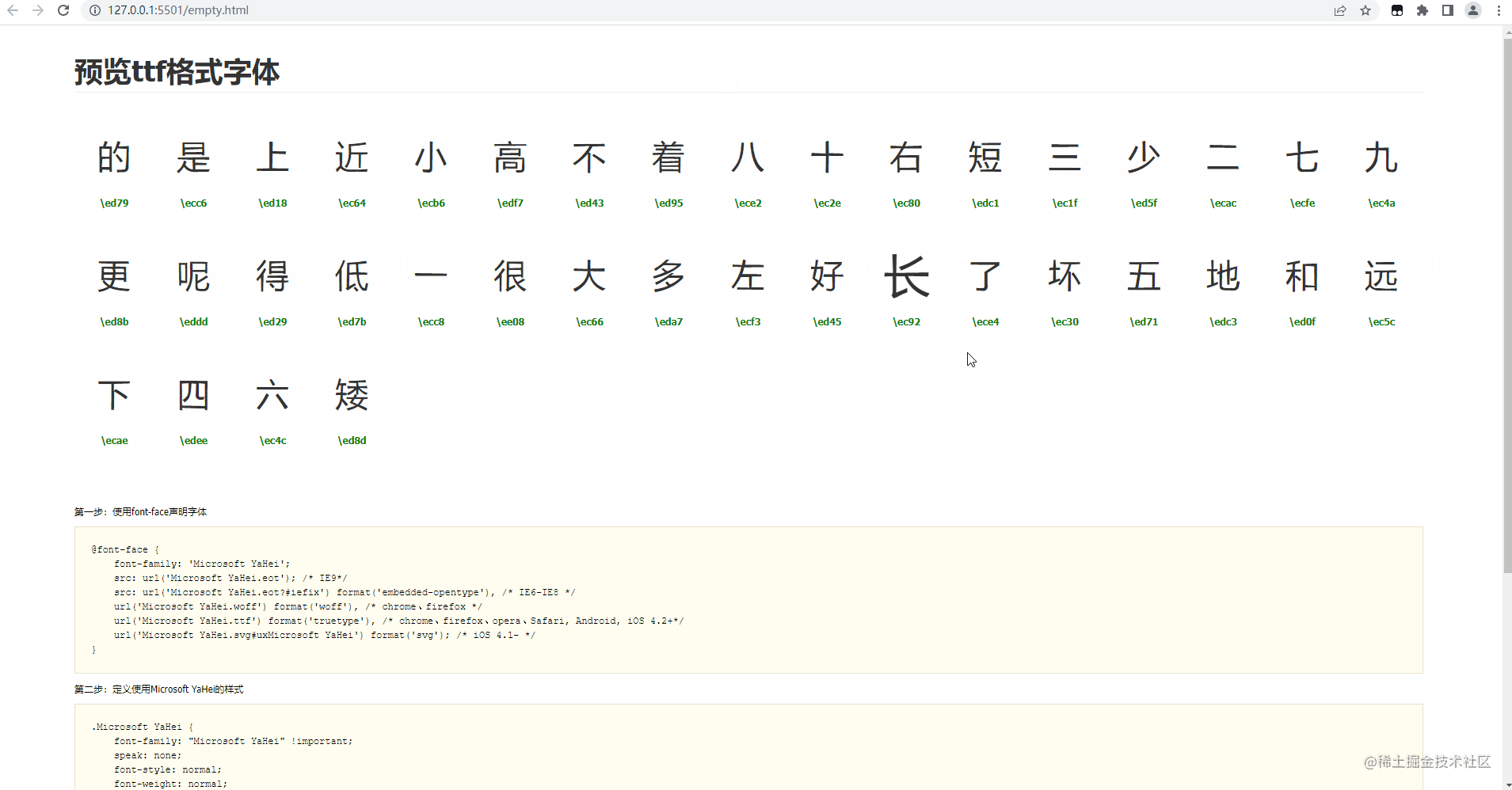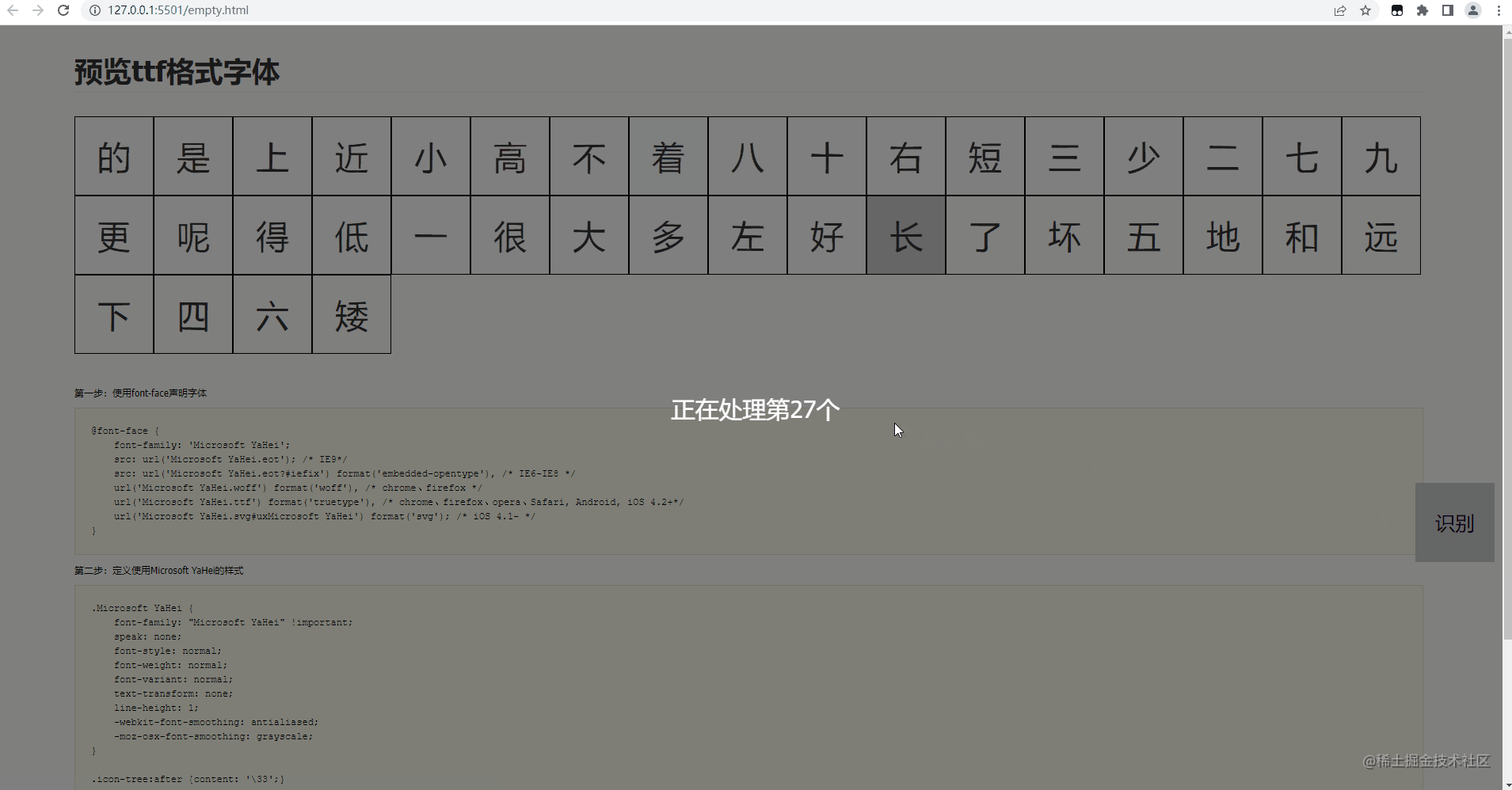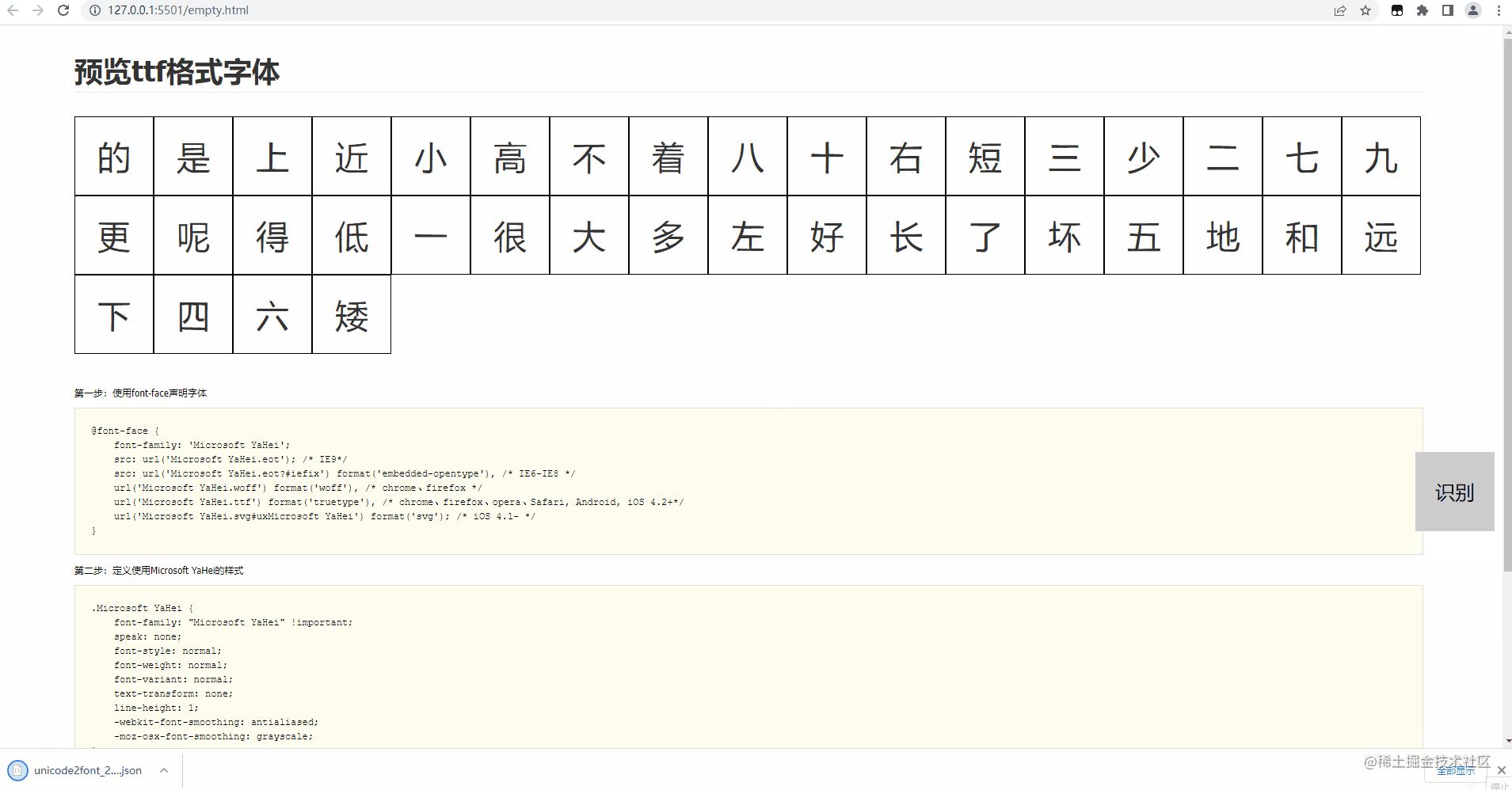
打开字体文件就是下面这样,有字体的字形,字体的unicode,以及对字体的二次编辑等功能。

我魔改的部分是他的预览页面,首先我们看下预览结果页面的样子

这个页面就满足了我们所有的需求。
为什么这么说呢,因为这个页面会展示文件内所有的字符,前端通过获取每个dom的base64图片,然后将图片传给识别接口识别,最后记录下来,简直完美。
识别接口这里用到的是百度的通用识别,每天5万次,个人使用完全够了,准确率杠杆的,没注册的可以去注册一个
项目里面这个地方要用到。
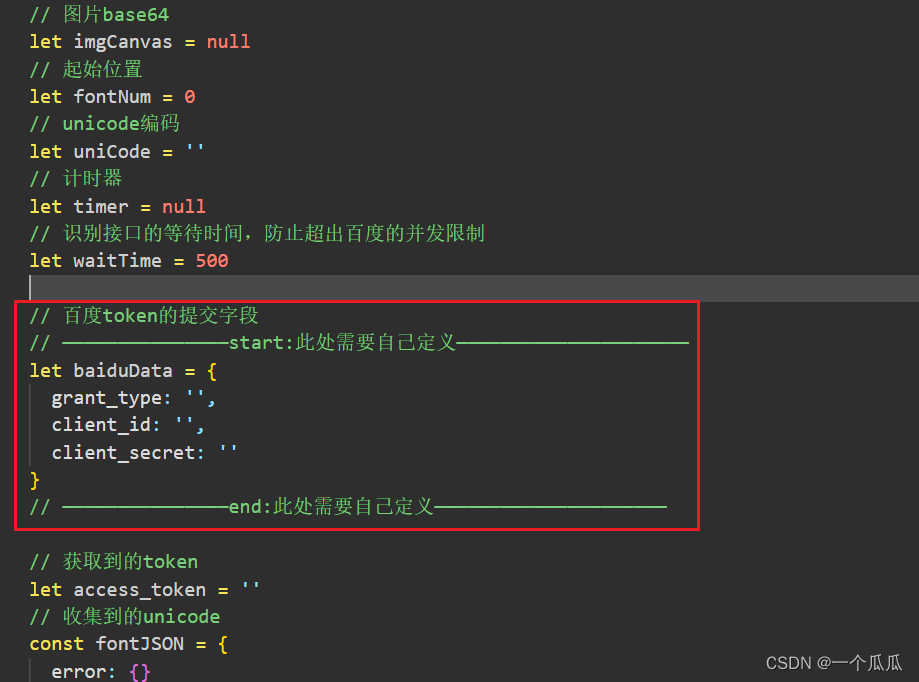
我知道你们在想什么,“可以教一下这个怎么填写么”,行的,可以(你们还是回家养猪吧)
注册之后先进到控制台,然后打开文字识别
这两个玩意按顺序完成就可以
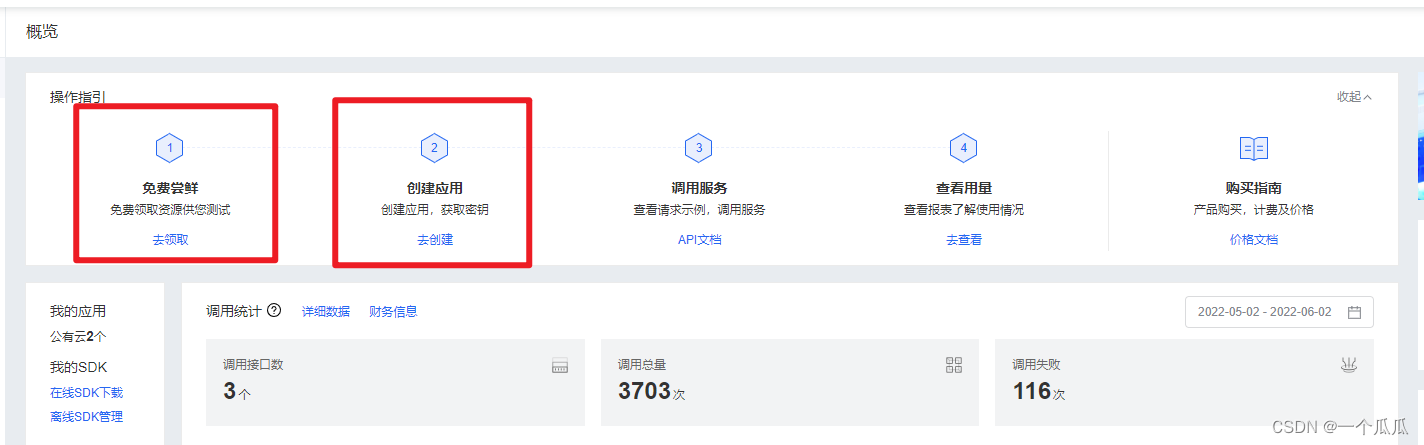
创建完应用之后,在应用列表里面,这几个值是你要保管好的,他可以去获取AccessToken,这个token就是一个通行证一样,有了这个通行证才能去访问服务

看到了吧,就是这几个,文档其实写的也很清楚了,就不一一赘述

以上就是大概的介绍,项目使用这里就用一个gif演示吧,最后会有一个json文件下载下来。里面就是你识别出的结果,对于错误或者,没有识别出来的,会有一个记录,就需要你自己手动修复一下了
汽车之家字体反爬破解思路
最后,前面说的关于某车的反爬破解方法,这里简单说一下
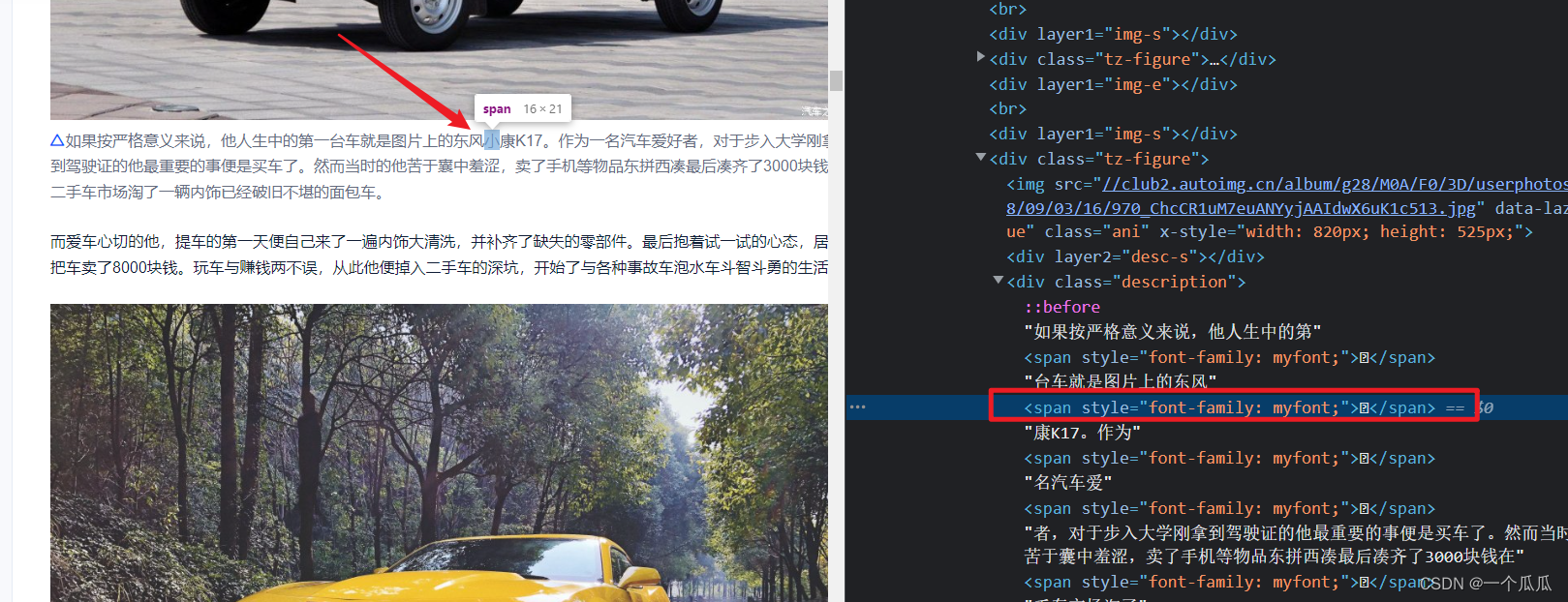
我们以下图这个为例,这是浏览器渲染后的dom效果

然后再看看网页源码,可以判断这个是服务端渲染的,虽然看不见字符,但是可以获取到字符

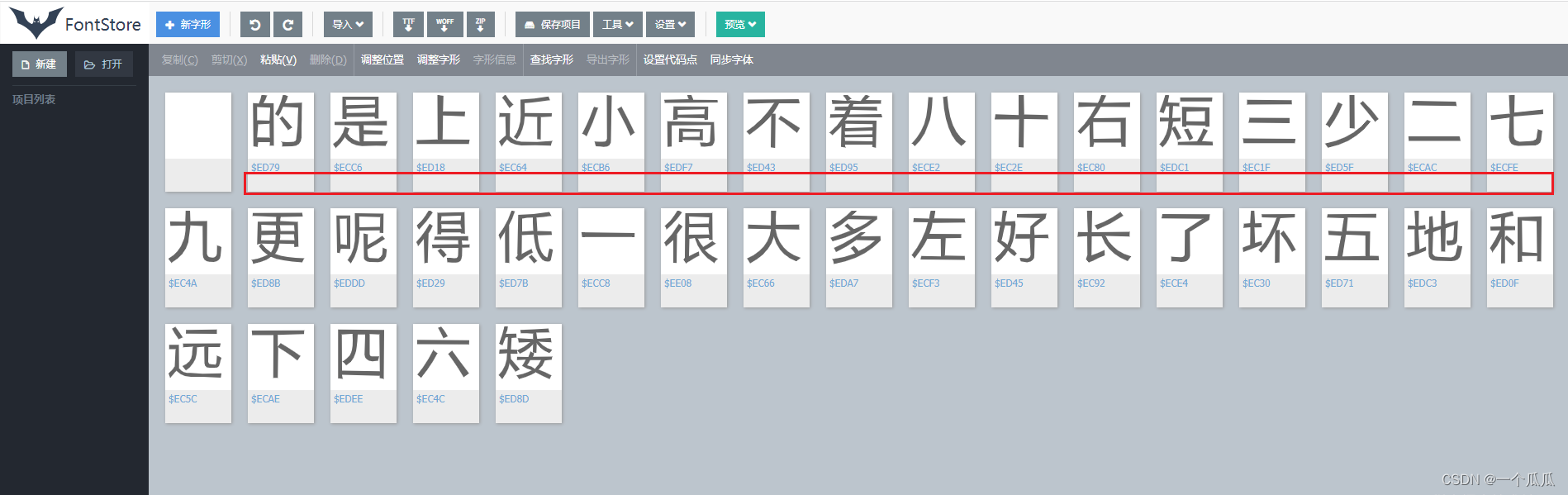
我们将获取到的字符写个demo测试一下
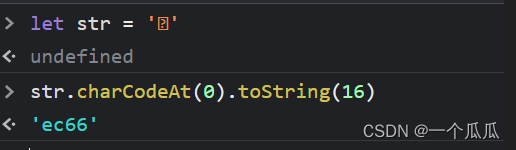
然后我们再去对应一下这个字体表,ec66刚好就是我们对应的“大”字
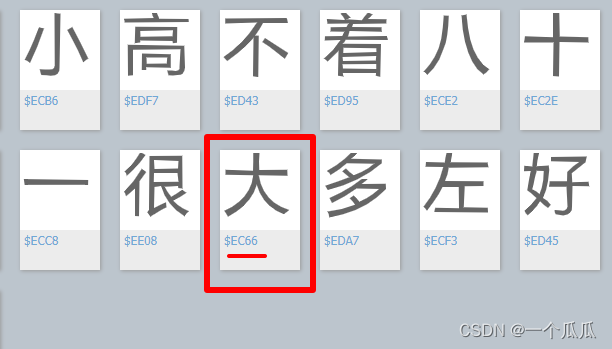
根据这个原理,那么我们可以通过获取到dom的字符然后转码出来替换为真实的字符,完结撒花,demo已经有了,思路到位就行
