另本文以教学为基准、本文提供的可操作性不得用于任何商业用途和违法违规场景。
本人对任何原因在使用本人中提供的代码和策略时可能对用户自己或他人造成的任何形式的损失和伤害不承担责任。
一般使用ast还原复杂样式的代码的时候,对代码进行预处理,将格式统一,后面再还原的时候会好写很多,所以这里也需要很多的预处理,如下:(如果不想看可跳到最后思路 )
去除最外层的 void 语句混淆
switch(a){
case 1:
void (a=b?c++:d--;)
break;
}
这种一看就是无效语句,用来混淆你分析代码的,可以去掉,也简单,直接遍历到 void 节点 然后删除就行了
estraverse.replace(ast, {
enter: function(node, parentNode){
switch(node.type){
case Syntax.UnaryExpression:
// 去掉 void 混淆 夹杂在三目表达式前面
if(node.operator === "void" && parentNode.type === Syntax.ExpressionStatement)
return node.argument;
return node;
}
}
});
就是需要注意不要删除错了,比如下面这样的语句是有效的,所以需要简单的判断下
for (var r = 5; void 0 !== r; ) {}
ce = void 0 !== V[z = ce]
处理三目表达式转成 if-else 语句
比如 下面这样
14 == b ? (w = a, r = c[d]): ff[81]++;
// 可以转成下面这样 方便调试
if(14 == b){
(w = a, r = c[d])
}else{
ff[81]++;
}
这种处理也简单,就直接使用 estraverse.replace 这个来遍历 三目表达式这个节点(ConditionalExpression),然后直接转换成 if-else 表达式就行,规则也很简单,调整下节点类型,不懂的可以写两个结构然后去 结构网站对照写规则改就行,难度不大,代码如下:
function tidy_seq(ifConseq, nodeConseq){
if (nodeConseq.type === Syntax.SequenceExpression){ // 拆开语句
for (let i = 0; i
我这里也顺便处理了三目表达式里面的逗号表达式,还是上面那个例子:
14 == b ? (w = a, r = c[d]): ff[81]++;
// 可以转成下面这样 方便调试
if(14 == b){
w = a; // 这里不一样了
r = c[d];
}else{
ff[81]++;
}
这样子做也是方便调试的,要不然如果直接是逗号表达式,在调试的时候会直接一步跳过,因为逗号表达式里面的所有句子是一个语句。
这里面为啥不需要递归处理三目表达式呢?因为使用 estraverse.replace 他可以遍历到所有的三目表达式,而我们在转换的时候,只是转换了下表达形式,就变成了 if-else 表达式,里面的句子不会变动的(除了逗号表达式),所以会遍历到,自然就不需要自己手动处理了
再说下上面的判断,为什么当父节点是 AssignmentExpression 或者是 ReturnStatement的时候不处理
两种特殊的情况
[ol]
[/ol]
a = b>5? 1: 2;
// 转成if else语句 如下
a = if(b>5){
1;
}else{
2;
}
若是按照之前的处理形式得到是上面的结果,显然是错误的,所以我们需要预处理下,就是在遇到上面这种赋值三目的时候需要把赋值语句写进三目里面,如下:
a = b>5? 1: 2;
// 转成下面形式
b>5?a=1:a=2;
// 嵌套的情况
a = b>5? 1: b>10?2:3;
// 会转成如下,
b>5?a=1:a=b>10?2:3;
就算遇到嵌套,同理一样会遍历到,所以不需要单独手动递归处理,只需要遇到的时候把赋值提到三目表达式里面即可
estraverse.replace(ast, {
enter: function(node, parentNode){
switch(node.type){
case Syntax.AssignmentExpression:
// 首先需要判断是不是三目表达式,同时赋值表达式的操作符号需要是 等于号
if (node.right.type === Syntax.ConditionalExpression && node.operator === "="){
let assConseqNode = esprima.parse("a=1").body[0].expression; // if node
let assAltNode = esprima.parse("a=1").body[0].expression; // else node
let leftNode = node.left;
let condNode = node.right;
// 构造新的 node 三目表达式的左值更改形式
assConseqNode.left = leftNode;
assConseqNode.right = condNode.consequent;
condNode.consequent = assConseqNode;
// 三目表达式的右值更改形式
assAltNode.left = leftNode;
assAltNode.right = condNode.alternate;
condNode.alternate = assAltNode;
return condNode;
}
return node;
default:
return node;
}
},
leave: remove_exp
});
当你预处理了这个之后,前面写的处理三目表达式就会处理了这个了, 因为预处理得到了一样的格式
[/ol]
return a==1?b:c;
// 若是上面不加判断的话,会处理成下面这个形式
return if(a==1){
b
}else{
c
}
这种显然也是错误的,同理,一样可以预处理,让他们变成一样的格式
return a==1?b:c;
// 预处理
a==1?return b:return c;
但是有人大概会问,这个处理后的结果不是正常语句,会报错
[img][/img]
确实不是正常语句,但是并无关系,因为这个只是我们的中间的 ast 结构,并不是我们最后要生成代码的 ast结构,我们最终的处理结果是成这样的
return a==1?b:c;
// 预处理
a==1?return b:return c;
// 在处理
if(a==1){
return b;
}else{
return c;
}
这样是不是就正常了,同时可以看出,一些复杂的代码,经过预处理后,再处理,会变得简单很多。
怎么预处理的话就留给大家了,和上面预处理 赋值三目 差不多的。
如果认真看的话,会看到在遍历处理三目表达式,最后 leave 的时候有个 remove_exp 函数,这个函数是去掉三目表达式里面的 ExpressionStatement 节点,如下
{
"type": "ExpressionStatement",
"expression": {
"type": "IfStatement",
"test": {
"type": "CallExpression", // 这里省略一些
},
"consequent": {
"type": "BlockStatement",
"body": [] // 这里省略一些
},
"alternate": null
}
}
因为在处理 三目表达式的时候是直接匹配 ConditionalExpression 表达式的,他的父节点大多数情况就是个 ExpressionStatement 节点,如果不去掉的话,在生成语句的时候,每个由 三目转成 if-else 语句的后面都会带个分号,这种会影响我们后面的处理,所以需要提前去掉,以防影响,去掉也很简单,直接判断 ExpressionStatement 节点下面的 expression节点是不是 if 节点就行。
function remove_exp(node, parentNode){
switch (node.type) {
case Syntax.ExpressionStatement:
// 去掉 if 语句上面的 ExpressionStatement 不然生成的语句会多一个 分号;
if(node.expression.type === Syntax.IfStatement)
return node.expression;
return node;
default:
return node;
}
}
处理逻辑表达式
观察到,有一些逻辑表达式也是可以处理成 if-else 表达形式的,这样也有利于调试,比如下面的
a > 0 && b=6; // && 在前面结果是真的时候才会执行后面的语句
// 可以转成下面
if(a>0)
b = 6;
a > 0 || b= 6; // || 在前面结果是假的时候才会执行后面的语句
// 可以转成
if(a>0){}
else{
b = 6;
}
处理形式也和三目转 if-else 一样,都是改下节点类型,,我这里只处理 && 情况,其他情况读者感兴趣的可以处理,代码如下
function logical_to_if(node){
let ifNode = esprima.parse("if(a){}").body[0];
ifNode.test = node.left;
// if 语句 没有 else 部分
tidy_seq(ifNode.consequent, node.right)
return ifNode;
}
function anti_logical(ast){
console.log("将一些逻辑表达式转换成if...");
return estraverse.replace(ast, {
enter: function(node, parentNode){
switch(node.type){
case Syntax.LogicalExpression:
if (parentNode.type === Syntax.ExpressionStatement){
if (node.operator === "&&"){
return logical_to_if(node);
}
}
return node;
}
},
leave: remove_exp
});
}
处理逗号表达式
前面也说了,逗号表达式里的所有句子都是一行代码,在调试的时候会直接一行执行,不能调试到里面单个句子(现在的chrome 版本好像可以,webstorm不行),所以我们需要拆开
这个处理的话会有点麻烦,因为需要将一条语句拆分成多条语句,正常的话是直接遍历到 SequenceExpression(逗号表达式) 这个节点,然后返回拆分之后的多条语句,但是由于 estraverse 这个库,不支持返回多条语句,我之前也改了这个库,但是效果都不理想,所以需要换个思路。
如果找到了这个逗号表达式的节点,然后从他的父节点插入语句呢?这样也不可行,会出现很多不可意料的结果,但是可以直接寻找他的父节点,然后在父节点插入就行,因为 逗号表达式 肯定会是在一个语句体里面的,比如函数体、循环体、if判断体等等,找到了之后就遍历这个语句体的语句,找到逗号表达式,然后拆分,最后插入到语句体里面,由于我们改变的是当前节点,所以是可行的。
不过在这里还可以再优化,遍历操作直接交给 estraverse ,不需要自己写,就是直接在遍历进去 enter 的时候寻找到 逗号表达式,然后给父节点加一个属性index, 记录他在语句体的位置,然后在 leave 遍历的时候找到父节点的时候不需要再遍历了,如下:
// 这里就做个标记,不能直接修改parentNode,否则情况很复杂,会有各种奇怪的情况出现,不熟读源码别修改parentNode
if (parentNode.flag){
parentNode.index.push(find_index_by_node(node, body));
}else{
parentNode.index = [find_index_by_node(node, body)];
}
为什么要数组呢?因为同一个语句体会存在多个逗号表达式,所以需要使用数组记录不同的位置
还有一个点就是 函数体、循环体、if判断体 的节点属性是会不一样的,比如是switch-case体的话,他的语句体是 node..consequent;若是 循环体(ForStatement) 的话,他的语句体是 node..body,其他体也是这个,为了后面 leave 遍历的时候好处理,所以在enter遍历的时候,判断下父节点的类型,然后加个节点属性,如下:
if(parentNode.type === Syntax.BlockStatement || parentNode.type === Syntax.Program || parentNode.type === Syntax.ForStatement){
body = parentNode.body;
flag = "body";
}else if(parentNode.type === Syntax.SwitchCase){
body = parentNode.consequent;
flag = "consequent";
}
最后整合代码如下:
estraverse.replace(ast, {
enter: function (node, parentNode){
switch(node.type){
case Syntax.ExpressionStatement:
if (node.expression.type === Syntax.SequenceExpression){
let body, flag;
if(parentNode.type === Syntax.BlockStatement || parentNode.type === Syntax.Program || parentNode.type === Syntax.ForStatement){
body = parentNode.body;
flag = "body";
}else if(parentNode.type === Syntax.SwitchCase){
body = parentNode.consequent;
flag = "consequent";
}else{
console.log("反逗号表达式有特殊情况", parentNode);
}
// escodegen.generate(res, {parse:n=>{return n;}});
// 这里就做个标记,不能直接修改parentNode,否则情况很复杂,会有各种奇怪的情况出现,不熟读源码别修改parentNode
if (parentNode.flag){
parentNode.flag.push(flag);
parentNode.index.push(find_index_by_node(node, body));
}else{
parentNode.flag = [flag]; // 这个便于 在leave寻找
parentNode.index = [find_index_by_node(node, body)];
}
}
return node;
}
},
leave: function (node, parentNode){
if (node.flag){
let flag, index, num = 0; // num 是备份插入的node,方便同一个节点有多个逗号表达式
for (let t = 0; t
将 if-else 控制流 优化成 switch-case
上面处理完,已经可以调试了,就是有点费手费鼠标,观察到里面控制流有几种形式
[ol]
[/ol]
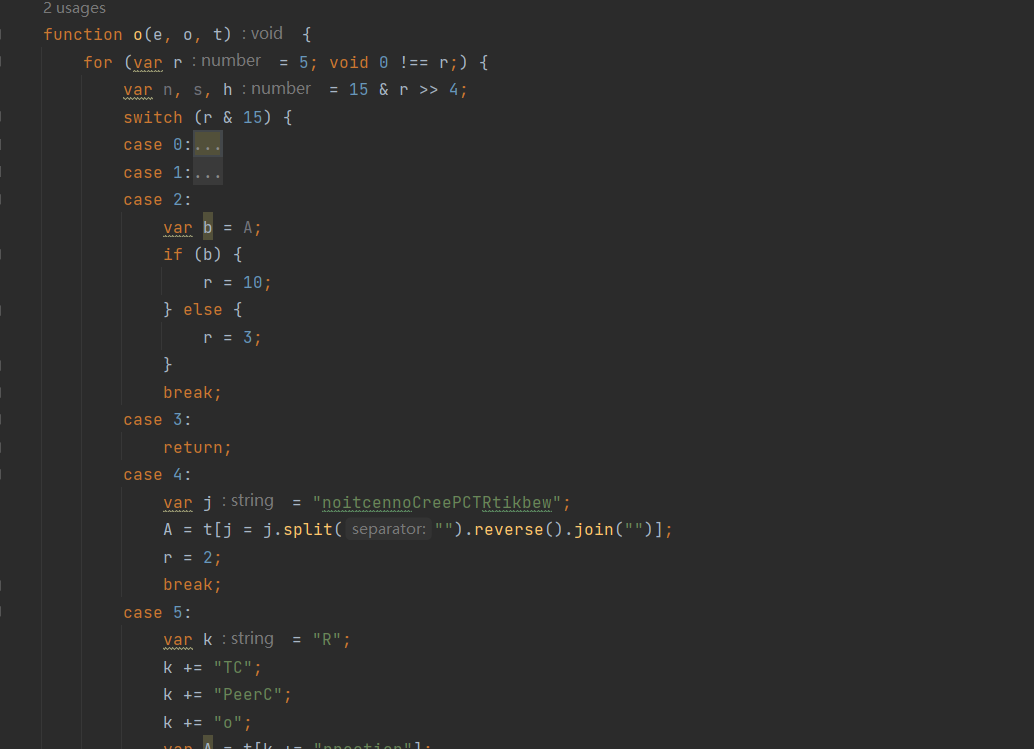
switch-case里面有 if-else 嵌套控制
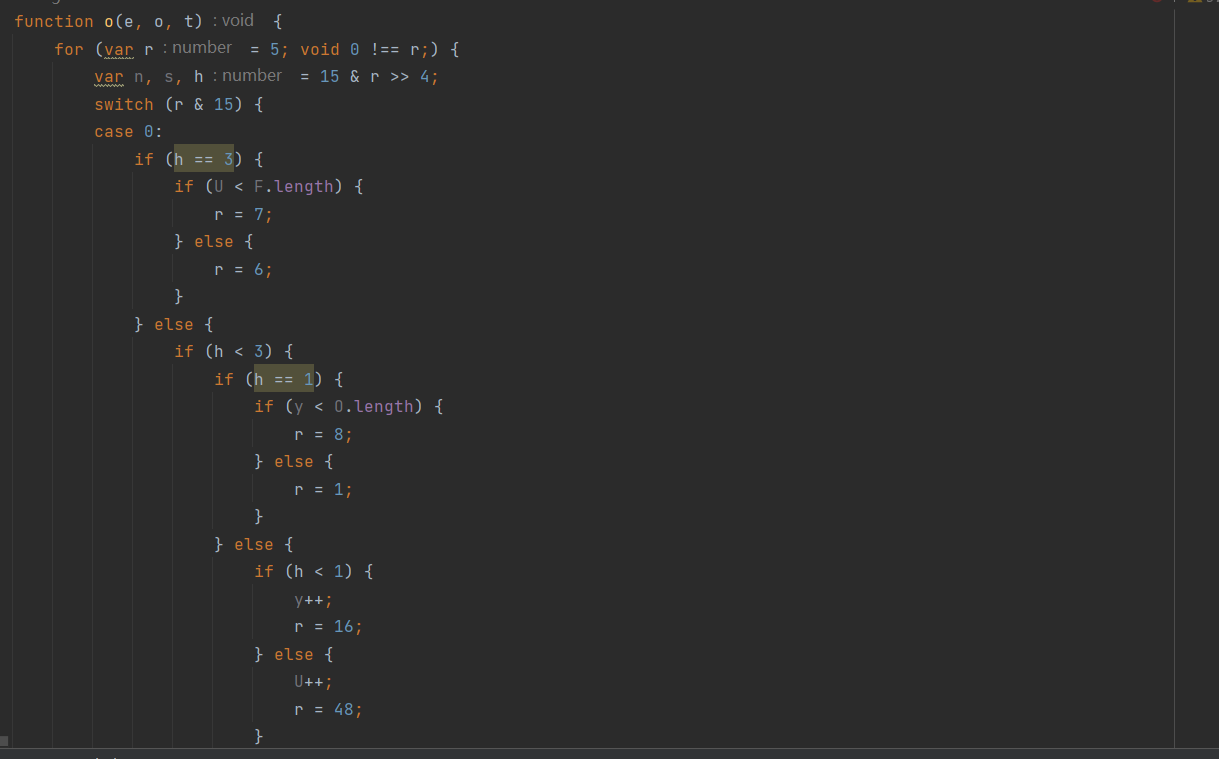
switch-case多层嵌套等
[/ol]
这种 if-else 的控制流会比 switch-case 费劲,因为需要多次判断才能到达正确的代码,而switch-case 的话是直接一步到位,不存在判断,所以可以将 if-else 转成switch-case,当然仅限于控制流能这样转。怎么转呢?照样需要预处理,将他们处理成一种格式,这样写规则会好写很多,具体步骤:
[ol]
[/ol]
判断条件处理
将判断条件里面的变量放置在左边,字面量放在右边,比如:
if(5 5){}
变换也简单,只是需要注意下符号的变换即可,其他的就是单纯交换位置,代码如下
function convert_symbol(operator){
let res;
switch (operator){
case "===":
case "==":
case "!==":
case "&":
res = operator;
break;
case "";
break;
case "=";
break;
case ">":
res = "=":
res = "
抽取匿名函数的内容
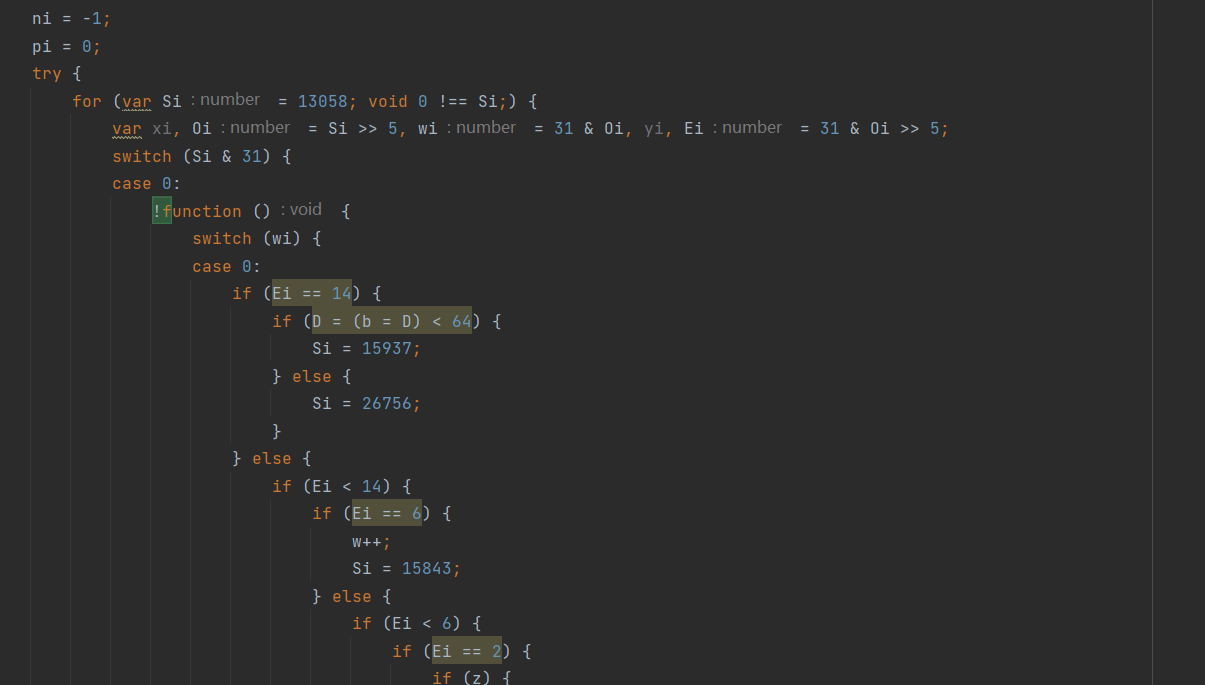
比如下面的这个,就是需要抽取出来,方便后面判断控制流
可以看到里面匿名函数都是只有一条语句,就是switch或者 if-else(图上没有,懒得找了),所以需要判断出语句体是不是只有一句。为了保险,这里还判断了其父节点是不是在控制流里面的 switch-case
estraverse.replace(ast, {
enter: function (node, parentNode){
switch (node.type){
case Syntax.ExpressionStatement:
if (parentNode.type === Syntax.SwitchCase && parentNode.consequent.length === 2 &&
node.expression.type === Syntax.UnaryExpression && node.expression.argument.type === Syntax.CallExpression){
let body_node = node.expression.argument.callee.body.body;
if (body_node.length === 1 && (body_node[0].type === Syntax.SwitchStatement || body_node[0].type === Syntax.IfStatement))
return body_node[0];
}
return node;
}
}
});
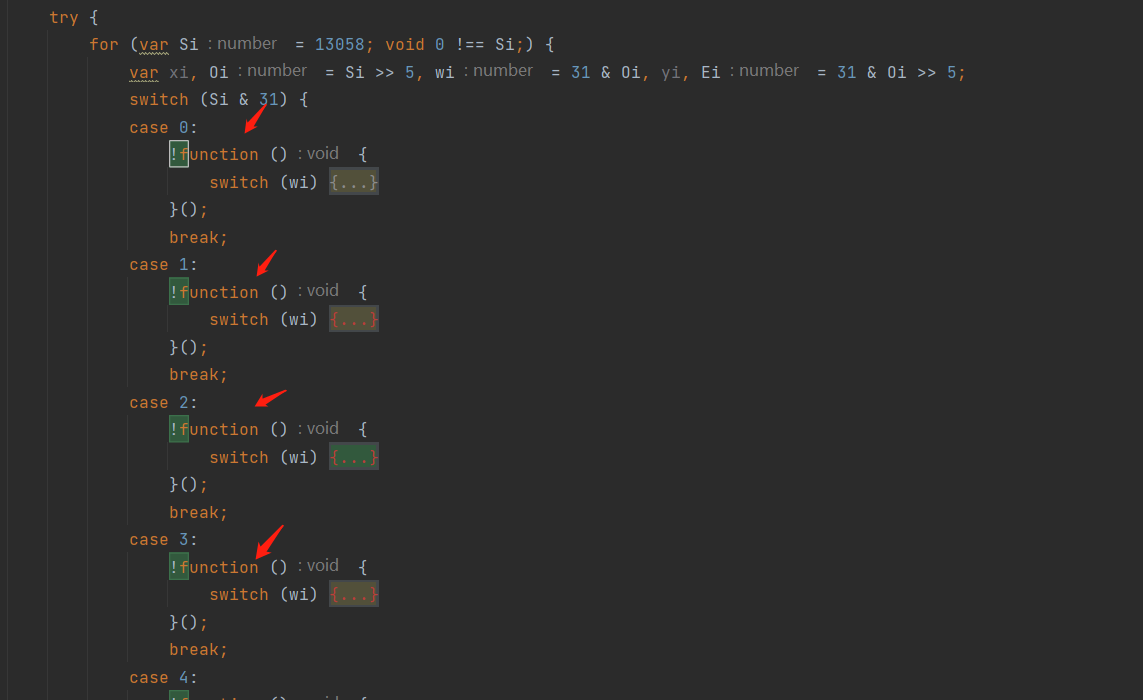
开始 if-else 转 switch-case
[ol]
[/ol]
for (var Si = 13058; void 0 !== Si;) {
var xi, Oi = Si >> 5, wi = 31 & Oi, yi, Ei = 31 & Oi >> 5;
switch (Si & 31) {
}
}
里面的控制流格式都是在一个 for 循环里面,并且 for 里的初始化语句是个状态变量,update 是空的,条件都是 void 0 !== 状态变量,
而且 for 循环内的第一条语句上,有运算的变量 都有可能是状态变量(有些是中间变量),而且是嵌套内的控制流的状态变量,所以我们需要收集这几个变量,来判断是否在控制流,如下:
case Syntax.ForStatement:
if (node.body.body.length === 2 && node.body.body[1].type === Syntax.SwitchStatement){
if (node.update != null || escodegen.generate(node.test, {parse:n=>{return n;}}).indexOf("void 0") {return n;}});
// 收集控制流的状态变量
let status_variable = [node.init.declarations[0].id.name];
let init_status = node.body.body[0].declarations;
for (let i = 0; i
然后最后还在控制流的switch节点上 加上了两个属性,都是状态变量,方便于后面找出属于控制流的判断语句,可以直接将 if-else 转 switch
当然,别忘记了嵌套的 switch 节点要加上去,同理嵌套的 if 也要,如下:
case Syntax.SwitchCase:
// 这个case 是有些switch是嵌套的 原本是在匿名函数的 经过 swap_test 处理,变成简单的嵌套在控制流上
if (node.consequent.length !== 2)
return node;
if (node.consequent[0].type === Syntax.SwitchStatement){
let sw_node = node.consequent[0];
switch (sw_node.discriminant.type){
case Syntax.Identifier:
if (parentNode.status.indexOf(sw_node.discriminant.name) > -1){
sw_node.status = parentNode.status;
}
break;
case Syntax.BinaryExpression:
if (parentNode.status.indexOf(sw_node.discriminant.left.name) > -1){
sw_node.status = parentNode.status;
}
break;
}
}else if(node.consequent[0].type === Syntax.IfStatement){
let if_node = node.consequent[0];
if (if_node.test.left && parentNode.status.indexOf(if_node.test.left.name) > -1){
if_node.status = parentNode.status;
}
}
return node;
标志加上了,可以在 leave 遍历处加上 真正将 if-else 转 switch 语句的逻辑
case Syntax.SwitchCase:
// 这个需要把if 转 switch
if (parentNode.status && node.consequent[0].type === Syntax.IfStatement &&
is_status(node.consequent[0], parentNode.status)){ // 最后条件判断if条件是否包含状态变量
node.consequent[0] = if_to_switch(node, parentNode.status); // 赋值回更改的 node
}
return node;
if_to_switch 这个函数的实现思路:
[ol]
先收集所有 if-else 语句块
要将 if 转 switch,就需要知道状态变量的那个值 对应哪个语句块,所以这里需要模拟执行状态流,但是不需要执行语句块,所以我这里将语句块删掉,设置为一个数字,这个数字对映的真正的语句块
模拟执行,我是直接从0开始模拟执行,直到执行到了相同分支,代表有重复了,证明这控制流运行完毕,可以结束了,为什么可以这样呢?我们先看状态变量是怎样取值的:
for (var Si = 13058; void 0 !== Si;) {
var xi, Oi = Si >> 5, wi = 31 & Oi, yi, Ei = 31 & Oi >> 5;
switch (Si & 31) {}
}
可以看到每个状态变量都会 & 31,证明了只取五位(bit),对应的范围就是0-31,所以直接遍历0-31也行,但我是直接遍历到有重复语句出现,是因为有的控制流状态变量取值范围是0-15 会不一样,我这样做比较方便
[/ol]
(其实这样最妥当的方法就是去收集所有状态变量的值,然后遍历这个去执行,当遍历完毕就证明所有分支都取到了,我后面的还原控制流就是这样做的)
下面举个例子:
比如代码是这样:
if (h == 1) {
B = me[So];
r = 8;
} else {
if (h
然后边收集代码块,边更改里面的代码块,变成了下面这样:
if (h == 5) {
h = 1;
} else {
if (h
然后我收集的代码块有对应关系,比如当状态变量为 1 时候,运行这段代码后返回 2,就知道状态变量 1 对应的是 2 对应的代码块(第一步收集到的对应关系),代码如下:需要注意的是嵌套 if-else,遇到证明不是真正的代码块,直接跳出
estraverse.replace(node, {
leave: function (node, parentNode){
switch (node.type){
case Syntax.BlockStatement:
if (is_status(parentNode, status)){
// 还要再判断body的语句是不是也是控制器
if (is_status(node.body[0], status))
break;
state_table[num] = node.body;
node.body = esprima.parse(test.name + "=" + num++ + ";").body;
return node;
}
}
}
});
收集完毕就开始模拟运行,找出 对应关系
也很简单,构造代码,让他返回我们想要的变量,然后使用 eval 运行即可,比如在上面的代码,构造成如下:
var h=0;
if (h == 5) {
h = 1;
} else {
if (h
这样子使用 eval 运行之后就可以得到 h的值,就自然知道了 状态变量 0 对应那个语句块了,代码如下:
let code = "switch(" + test.name + "){};";
let new_node = esprima.parse(code).body[0];
let break_node = {
"type": "BreakStatement",
"label": null,
};
let num = 0, index = 0;
let init_state = [];
while (true){
index = num++;
let eval_code = "var " + test.name + "=" + index + ";\n" + curr_code + "\n " + test.name + ";";
let res_num = eval(eval_code);
if(init_state.indexOf(res_num) > -1){
break; // 结束了
}
init_state.push(res_num); // 记录语句 遇到重复的说明已经可以跳出了
let res = state_table[res_num];
res.push(break_node);
new_node.cases.push({
"type": "SwitchCase",
"test": {
"type": "Literal",
"value": index,
"raw": index + "",
},
"consequent": res
});
}
最后得到的语句就是转换之后的 switch-case 了,简单看下效果:
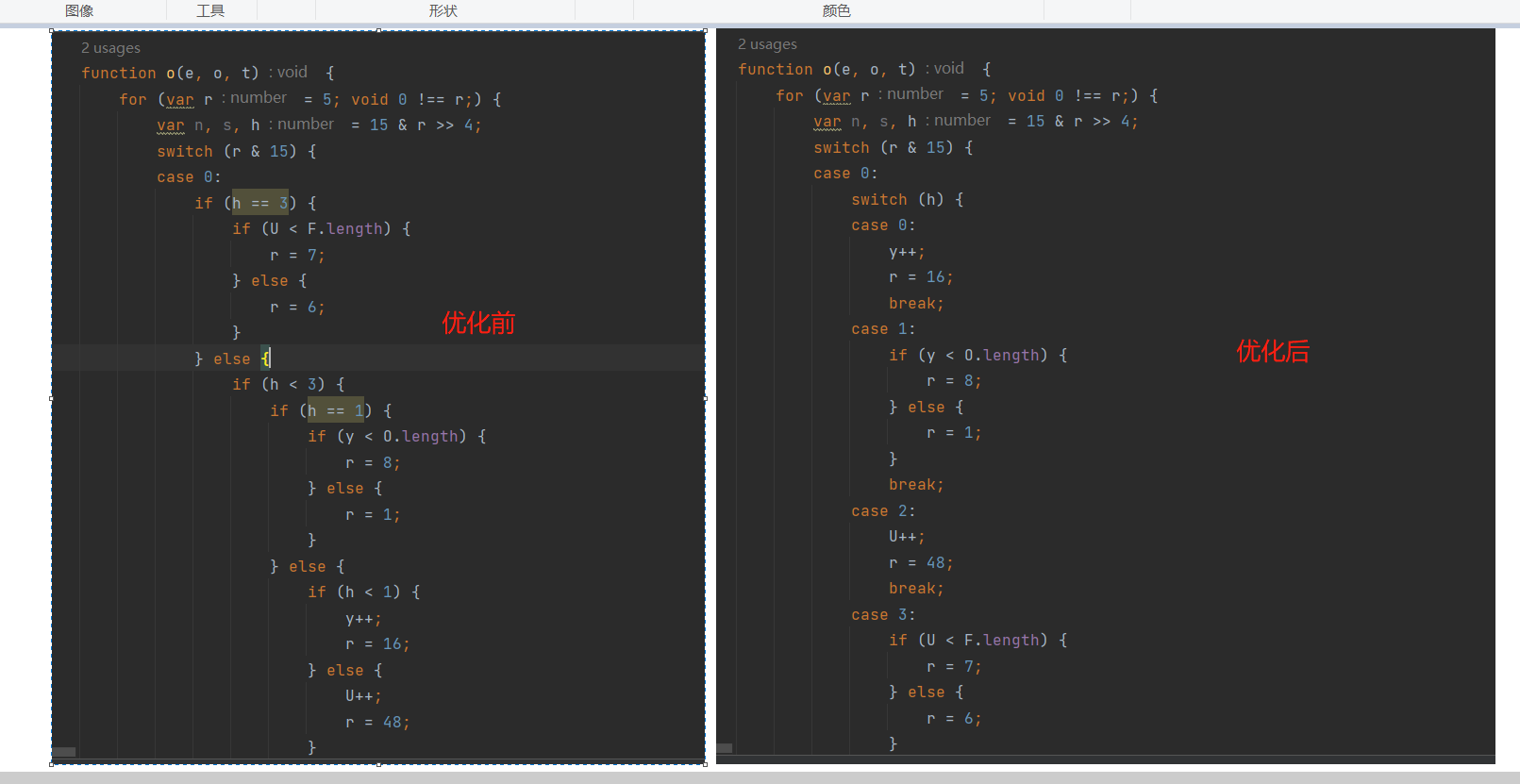
将多层 switch 转换成 一层 switch
上面虽然看到舒服很多,调试也很舒服,但是还可以继续处理,就是直接将多层switch 转成一层。这里的思路其实和上面的 if 转 switch一致
[ol]
[/ol]
case Syntax.ForStatement:
// 找到控制流 status 是上面 if 转 switch 遗留下来的 这里就不需要再判断别的了
if (node.body.body.length === 2 && node.body.body[1].status){
let status_name = node.init.declarations[0].id.name;
let status_list = [ node.init.declarations[0].init.value];
}
return node;
收集整个控制流的所有状态变量
estraverse.traverse(ast, {
enter: function (node, parentNode){
switch (node.type){
case Syntax.AssignmentExpression:
if (node.left.name === status_name && (node.right.type !== Syntax.UnaryExpression && node.right.operator !== "void")){
if (node.right.value === undefined)
throw "收集状态变量有新情况";
status_list.push(node.right.value);
}
break;
}
}
})
然后收集每个case对应的语句块,保存对应关系,然后case里面的语句块改掉,直接改成和上面的 if 转 switch的形式
estraverse.replace(node, {
leave: function (node, parentNode){
switch (node.type){
case Syntax.SwitchCase:
if (node.consequent[0].type === Syntax.SwitchStatement && status.indexOf(node.consequent[0].discriminant.name) > -1){
break;
}
if((parentNode.discriminant.type === Syntax.BinaryExpression && status.indexOf(parentNode.discriminant.left.name)
这个的话需要注意一个控制流嵌套另一个控制流,他们的状态变量不一致的,不能收集错了。
模拟执行所有状态变量的值,整合成ast
[/ol]
while (true){
index = status_list[num++]
let eval_code = "var " + test.name + "=" + index + ";\n" + curr_code + "\n " + test.name + ";";
let res_num = eval(eval_code);
if(status_list && num > status_list.length)){
break; // 结束了
}
init_state.push(res_num); // 记录语句 遇到重复的说明已经可以跳出了
let res = state_table[res_num];
new_node.cases.push({
"type": "SwitchCase",
"test": {
"type": "Literal",
"value": index,
"raw": index + "",
},
"consequent": res
});
}
简单整合在一起,最后就可以得到结果了
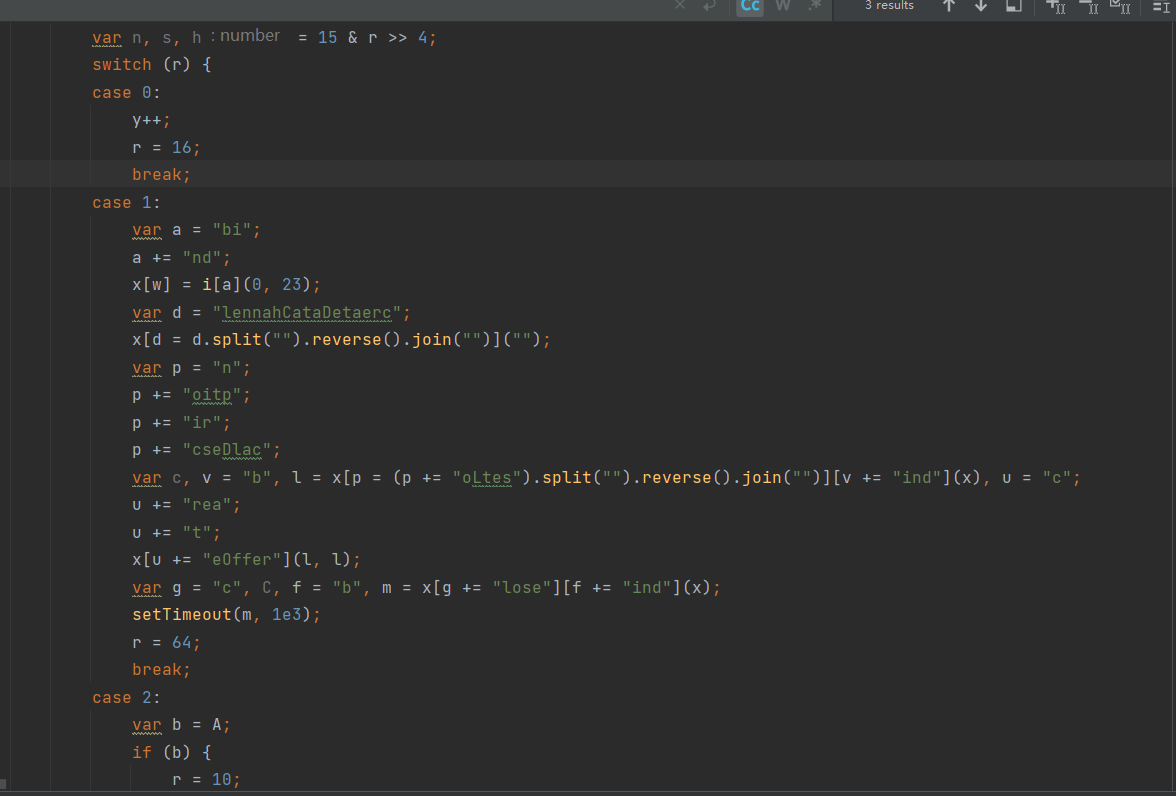
真正还原控制流
前面做的所有东西,其实都是还原控制流的预处理,这样做好处是,在还原控制流的时候写的规则会少很多,同时如果其他混淆有变化,但是控制流的形式不变,那后面更新了也可以只修改变的那部分,很方便,不同形式的控制流也可以这样做,比如将某数的控制流修改成某里的控制流形式,这样就可以用我接下来写的代码来还原,也很方便。
[img][/img]
思路:
[ol]
识别出控制流(同上)
收集所有case num以及他对应的代码块,同时把这个 num 作为属性添加给该块(同上)
找到初始化的状态变量,就是 for 循环里面的初始化变量
找到对应的代码块,然后解析出下一个块的num,也就是下一个状态变量,并且将该 num 保存到数组中,代表已执行
[ol]
[ol]
[/ol]
[/ol]
if(last_node.type === Syntax.ExpressionStatement){
cur_node = check_is_status(cur_node, len, status_name, case_table);
next_node = cur_node[cur_node.length - 1];
} else if(last_node.type === Syntax.IfStatement){
let last_node_seq_len = last_node.consequent.body.length;
if (last_node.consequent.body[last_node_seq_len-1].type === Syntax.ExpressionStatement){
last_node.consequent.body = check_is_status(last_node.consequent.body, last_node_seq_len, status_name, case_table);
if_node = cur_node; // 保留 if 语句 放到后面再整合
}
let last_node_alt_len = last_node.alternate.body.length;
if (last_node.alternate.body[last_node_alt_len-1].type === Syntax.ExpressionStatement){
last_node.alternate.body = check_is_status(last_node.alternate.body, last_node_alt_len, status_name, case_table);
next_node = last_node.alternate.body[last_node.alternate.body.length-1];
}
if (if_node){
// 头部插入,这样子后面处理的话是先处理内部在处理外面的 方便抽取相同块
if_list.unshift(if_node);
// console.log("保存 if 块:", if_node.num);
if_node = undefined;
}
}
pre_node = cur_node;
cur_node = next_node;
一直执行到代码结束,
[ol]
[/ol]
if (last_node.type === Syntax.ReturnStatement || escodegen.generate(last_node, {parse:n=>{return n;}}) === (status_name + " = void 0;")){
break;
}
这里还没有真正执行完毕,因为还有 if 的语句块没执行,继续遍历 递归执行收集到的 if语句块,回到 上面第四步
[ol]
执行 if 语句块的话 跳出条件很关键,要不然很容易死循环,或者会执行到很多重复代码浪费时间,我这里跳出条件如下:
先用第三步的数组判断目前的 语句块对应的 num 在不在数组
不在的话证明百分百和主分支没有重复,继续往下执行
如果存在,那就代表当前的语句需要合并到主分支了,同时需要结束当前 if 了,但是往下的情况处理也会有好多种
[ol]
[/ol]
while (U
[/ol]
while (true) {
...;
if (ae = $
怎么判断是不是外部的 if:
[ol]
[/ol]
判断是不是在这个 if 语句一进来就存在重复语句,若是,那肯定这个 if 语句块是为空的,直接跳出(前提是先判断是不是 while 和while true循环)
直接在已运行的状态列表获取这个num对应的语句块即可结束,不过需要深度拷贝,不可以直接引用
[ol]
为什么可以这样?在之前每运行一个语句块,都会去保存这个语句块的对应关系,比如:
[ol]
[/ol]
if (Z) {
I = y(Z, A[1]);
if (I) {
S.push(I[Ao]);
} else {
S.push(0); // 5
}
} else {
S.push(0); // 5
}
...;
比如在运行完 z 判断的else部分时候,记录了所有的语句块,若 S.push(0); 是语句块 5;然后再去运行 z 判断的 if部分,首先会遇到 I 判断,但是我们直接忽略if部分(会先记录),直接运行else部分,然后又运行到了 语句块 5,对应的就是 S.push(0); 我们在判断他不是 while、不是 while true,同时也不是空语句的时候,就可以直接在 已运行列表获取 这个5 对应的语句块了 ,因为他们后面的语句肯定是一样的。
接下来是重点,我们在结束 I 判断 if 语句的时候,是需要合并分支的,怎么合并?那肯定是需要裁剪的,这个时候语句块 5 就会被裁剪,如果上面取语句块 5 的时候没有采用深拷贝,就会影响到后面的句子。
[/ol]
[/ol]
当处理完当前 if 语句的时候,需要处理语句,比如判断到是 while 循环、while true循环的处理,同时若不是以上这两种就需要合并分支
[/ol]
function handle_branch(last_body, cut_node, is_while, is_do_while, prev_body){
let if_node = cut_node[cut_node.while_true?cut_node.length-2: cut_node.length-1];
// 判断是不是遇到循环了
let last_node = last_body[last_body.length-1];
let seq_body = if_node.consequent.body;
let alt_body = if_node.alternate.body;
if (is_while && cut_node.length === 1){
// 这个是直接用if条件做循环
cut_node[cut_node.length-1] = if_to_while(if_node.test, seq_body, alt_body);
cut_node[cut_node.length-1].num = cut_node.num;
return "while";
}else if(is_while || is_do_while){
let temp_seq_body;
// 这个直接是while true 循环
if(last_body.num === cut_node.num){ // 这个是跳出条件和当前需要还原的if条件一致
temp_seq_body = cut_node;
cut_node = [];
}else{
remove_while_node(cut_node, prev_body); // 这个删除节点直接把 cut_node 在 ast 上删除了 所以后面要补上 要不然怎么修改都不会对原节点有影响
// 这个跳出条件是前面 不一致 cut_node顺便清空 因为把内容都给了 prev_body
prev_body.splice(prev_body.length, 0, cut_node.splice(0, cut_node.length));
prev_body[prev_body.length-1].num = cut_node.num;
temp_seq_body = prev_body;
prev_body.while_true = true;
}
let alt_body = if_node.alternate.body; // 这部分是while true 下面的语句,并且else需要填上break
if_node.alternate.body = [
{
"type": "BreakStatement",
"label": null,
}
];
let true_node = {
"type": "Literal",
"value": true,
"raw": "true"
};
cut_node = if_to_while(true_node, temp_seq_body, cut_node);
cut_node.splice(cut_node.length, 0, ...alt_body);
return is_while?"while":"while_true"
}else{
// 这个再遍历if else分支 看看有没有重复的
while (true){
if (!(seq_body[seq_body.length-1] instanceof Array))
break;
if (remove_dup_branch(alt_body, seq_body, seq_body[seq_body.length-1], cut_node, insert_index))
break;
seq_body = seq_body[seq_body.length-1];
}
return "if";
}
}
[/ol]
function find_con_break_in_while(body, break_node, continue_node){
for (let j = 0; j j)
continue;
}
}
}
return false;
}
[/ol]
虚假分支
上面还有一个很重要的点,那就是存在虚假分支,如果单纯用上面的逻辑,你会发现卡在死循环里面,是因为遇到了虚假分支,如下:
if (K = (Fo = (K = fe * fe) + (Fo = ti * ti)) >= (K = fe * ti)) {}
if (xe = fe >= (Fo = (K += go = Fo * xe) * K)) {}
if (fe = (Fo = (K = !$e) * K) > -121) {}
if (xe = (fe = (K = K >= 3) * K) > -46) {}
虚假分支会有两种表现形式
第一种就是上面第一二行,我也看不太懂,利用的是一些 undefined 或者布尔变量来计算的,if 条件永远为真
第二种就是上面第三四行,是用自身 * 自身,这样数字永远是大于等于0,而且右边数字永远是一个随机负数,所以 if 也是永远为真
我这里识别很简单,因为他的虚假分支都是使用的固定变量,比如:go fe Fo te ti fe xe K ,然后判断 if 条件是否存在这些变量即可
如果不确定 是永为真,还是永为假的话,可以在 else部分加个 throw,抛出异常(这个是可牛大佬指导的,可牛yyds),然后在生成的代码去调试下,没有任何异常就代表是正确了。
最终还原效果如下:
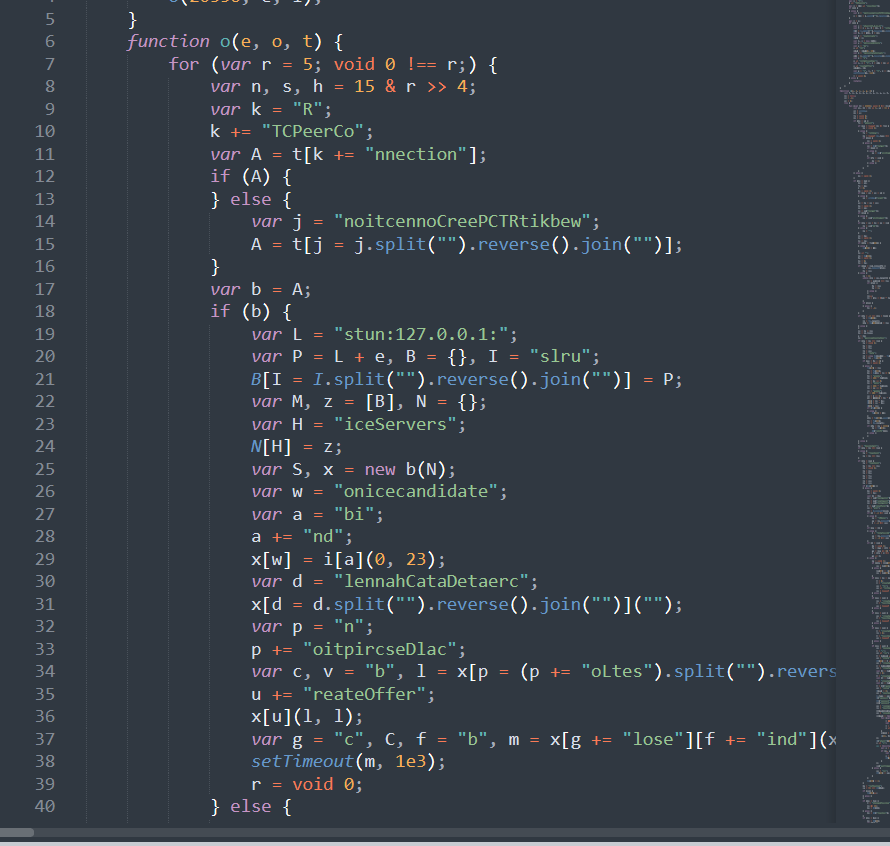
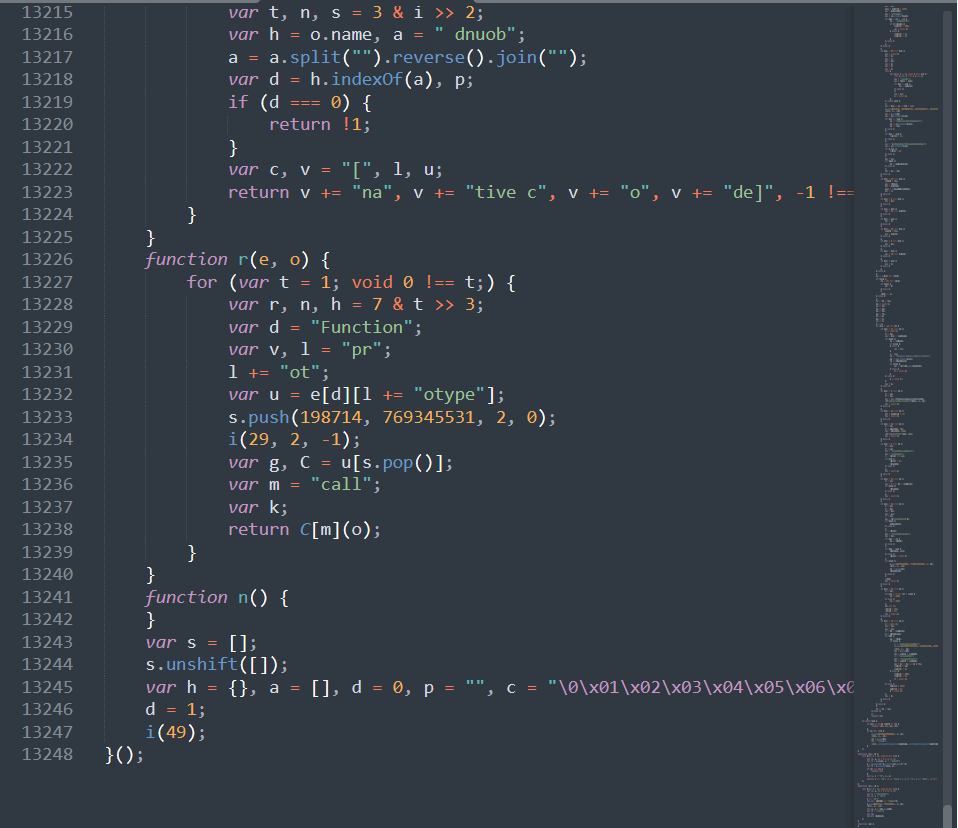
可以看到,会有些字符串加密,这里的话感兴趣的可以自行去写,难度不大,思路一样是识别出加密字符串代码,使用eval运行得到结果,将结果替换上去,这里说下几种字符串的区别,以及一些坑:
// 比较简单的 while 循环 异或解密
var T = "167,xspulrlrlsx", L = "", D = 0;
while (D
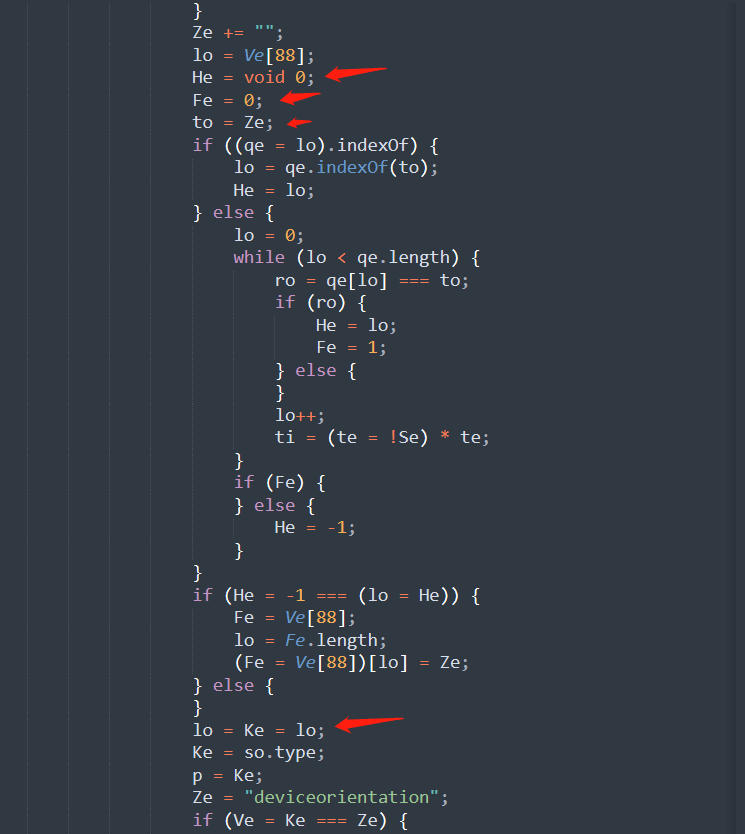
坑:还原的时候会有转义字符,比如 \n,\s, \d, \r
这里面会有些伪转义字符,就是上面的 \s, \d 因为只对正则有用,若你还原的时候单纯是 a = "\s"; a 最后的结果是 "s",如下
[img][/img]
可以发现最后结果是错误的,这个坑也是致命的,因为很多检测都会有正则匹配,最常见的就是函数的 toString 然后正则匹配
正确的处理方法是需要在 遇到反斜杠的时候 再加个反斜杠,这样子就正确了
[img][/img]
其他的暂时没想到了,想到了再补充。
最终效果可以看到他是将一些函数,把参数给定,然后将整个函数插入到一整个函数里面的
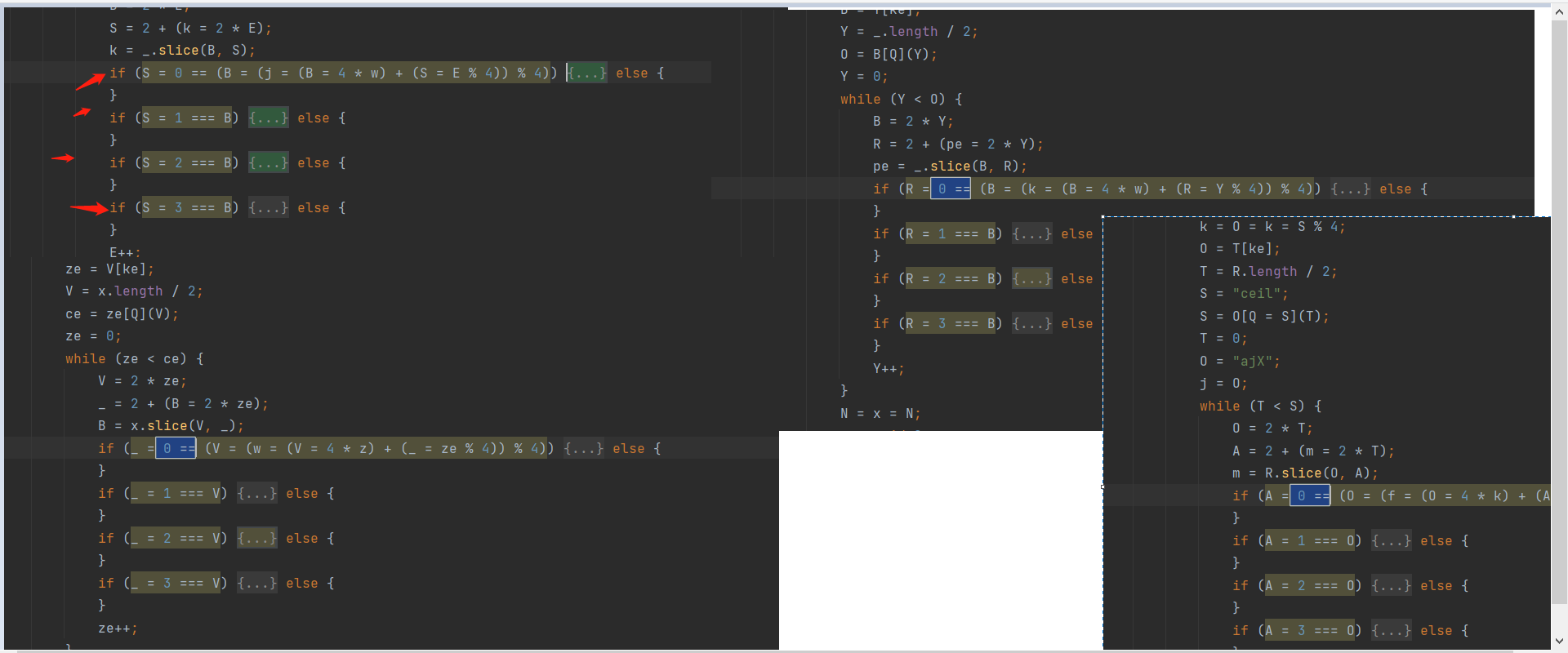
会在运行每个函数前面开始赋值一个变量为 void 0, 然后传参,上面的 Ze 就是参数了,赋值给 to,就类似于传参
下面最后的 lo = Ke = lo; 其实就是返回值,有兴趣的话可以手动函数抽取下,这样代码大概率会在 7-8千行,手动的话很难,因为有些地方是相互穿插的,类似于多线程那种运行代码,也有可能是我太菜了,看错了。
最后就是验证还原的结果是否可用了:
先验证联通的:
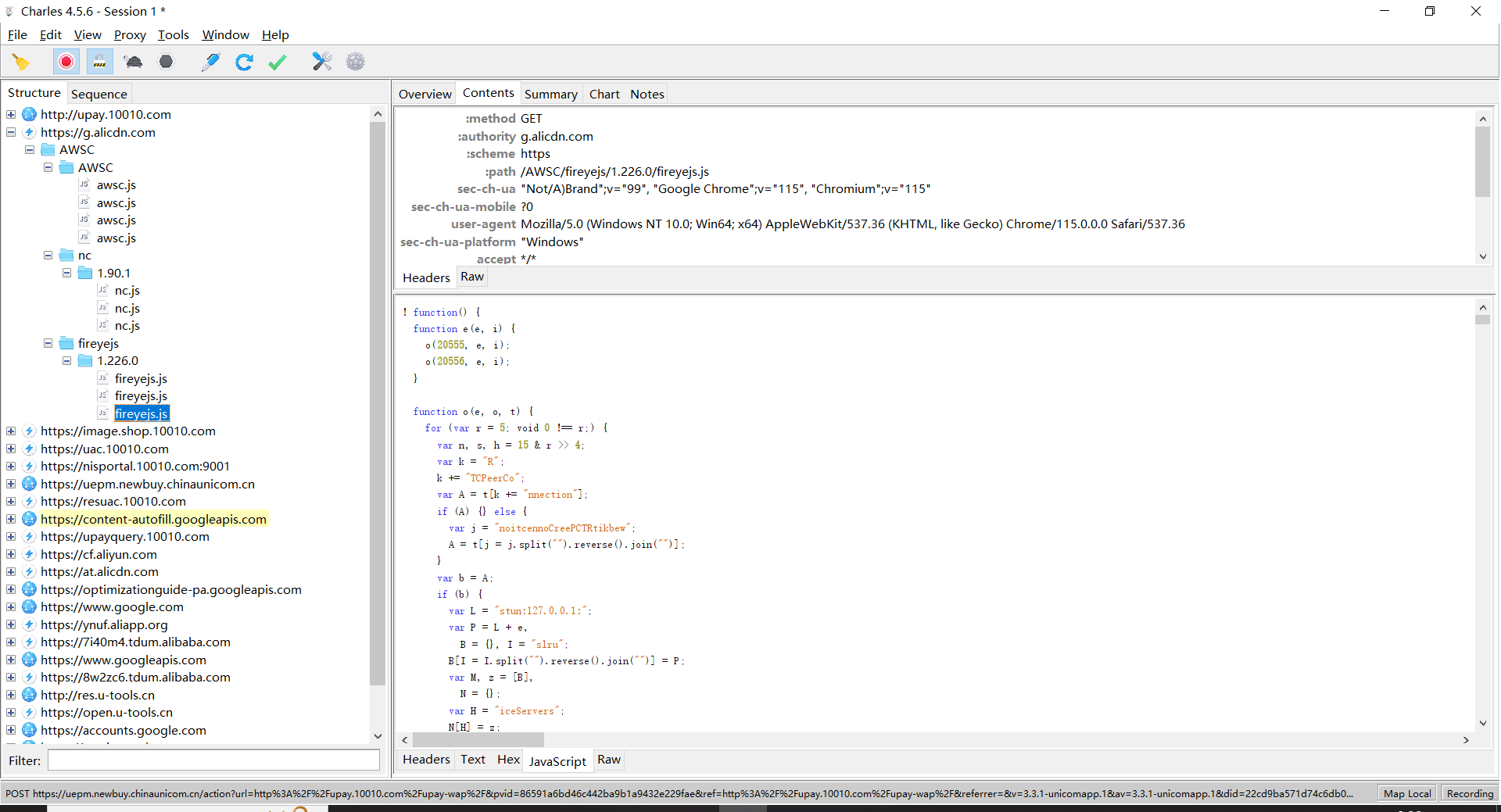
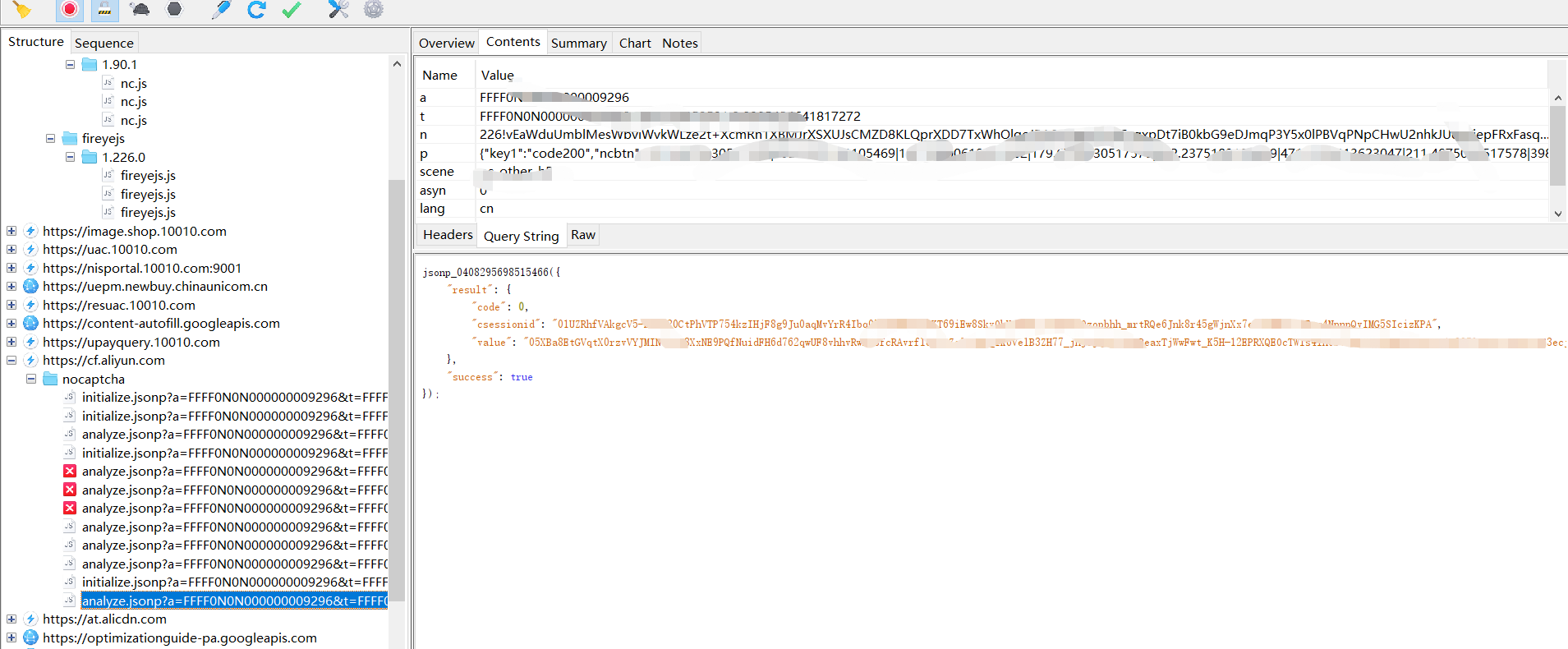
淘系的:
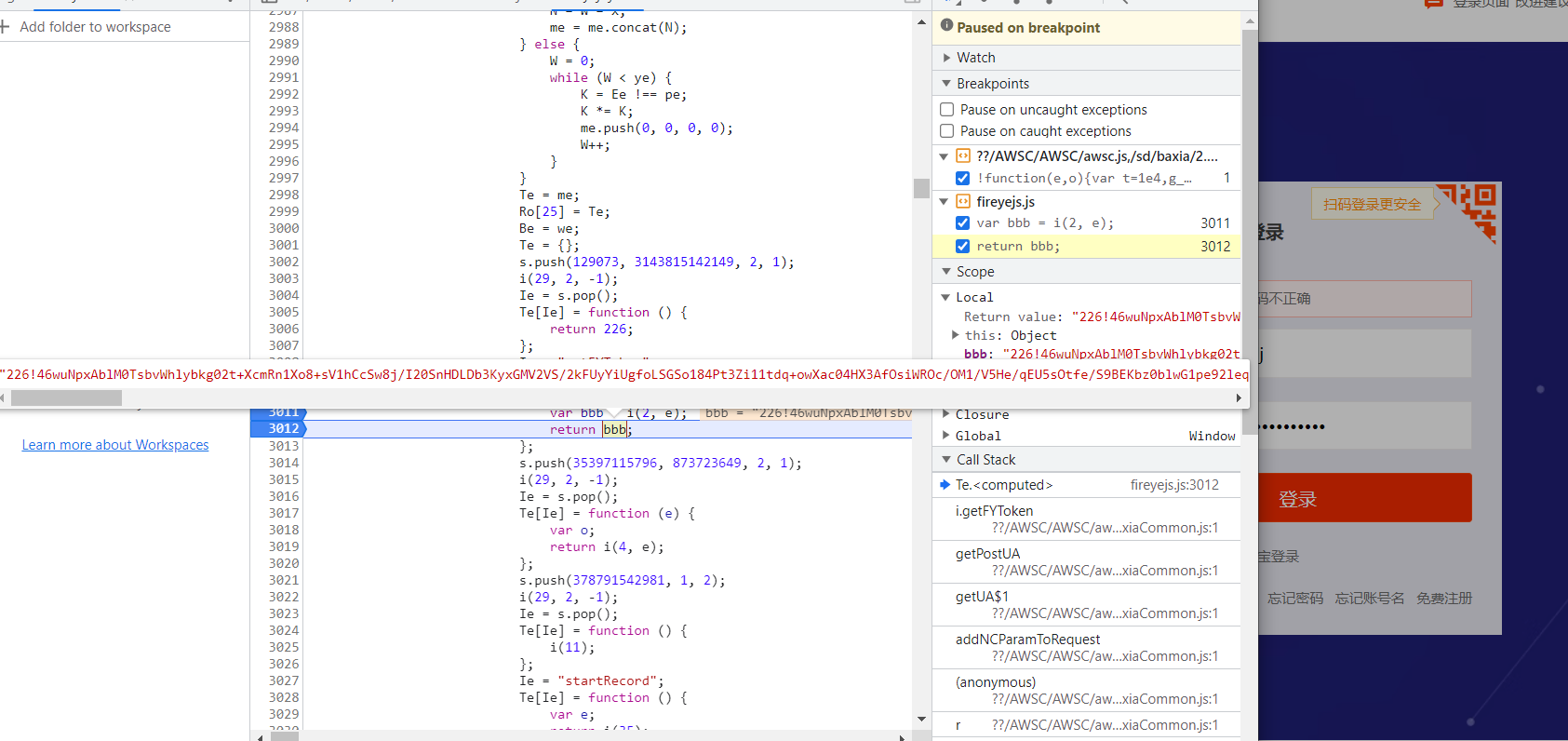
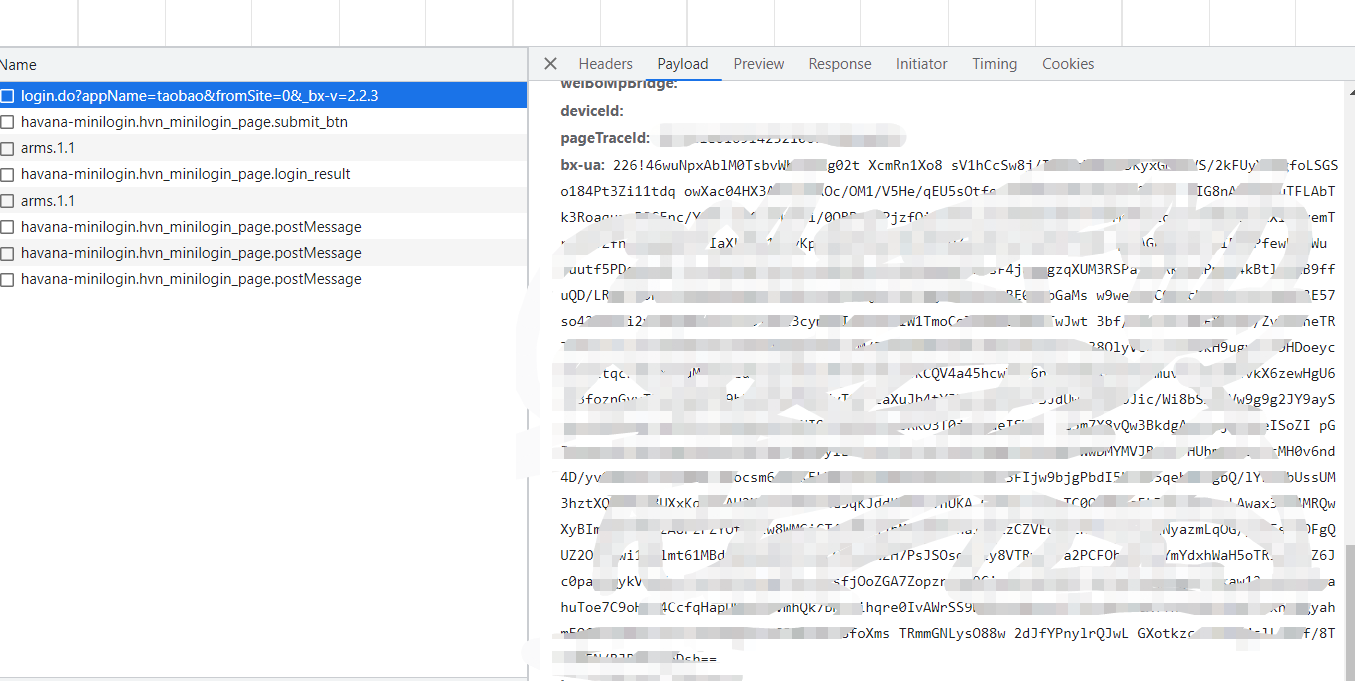
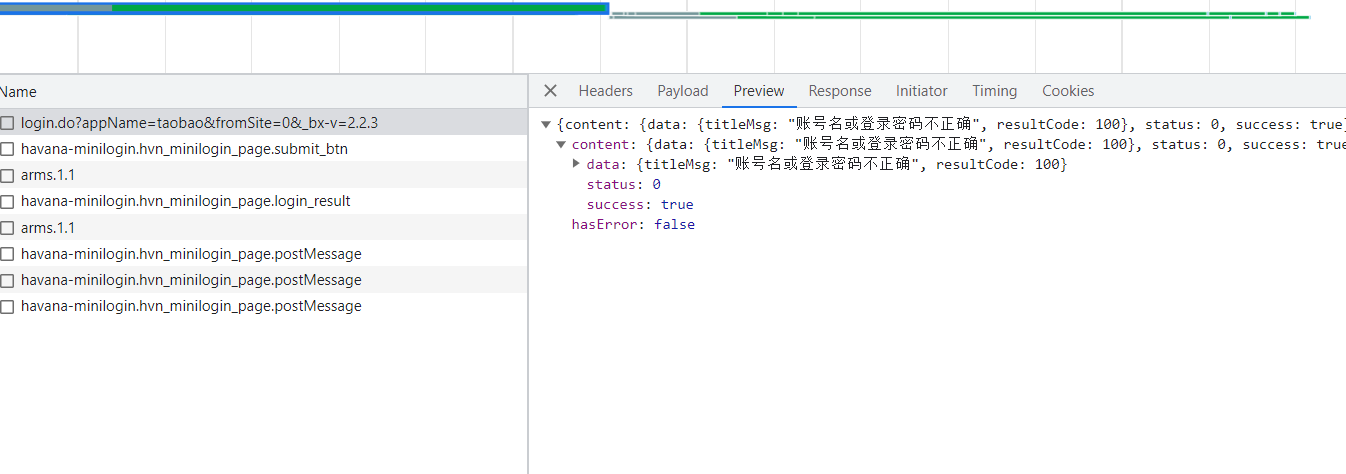
淘系的检测会比非淘系的严格很多,非淘系的好像格式对了就行,淘系的对很多个关键函数以及自身js函数的 toString 检测严格,有一个不对都不行,还有会对栈检测,自身的函数检测了几次,栈的检测也有几次,其他都是一些常规的信息收集(没怎么调试过)
样本改进建议:
[ol]
[/ol]
最后
这思路应该可以对抗大部分控制流混淆,只要识别出控制流,然后收集到状态变量以及对应的块即可,最后本人找逆向或者爬虫工作,偏逆向,会js逆向,安卓逆向也懂点,在学。有岗位的可以私信我,感谢。

