与其它类似的 AI 智能代码提示工具不同,Continue 是开源的, 支持调用本地部署的大模型服务, 可以在企业内部甚至是安全隔离的局域网中运行, 并且提供了完善本地运行的文档。如果是私有代码库, 无法使用基于互联网的 AI 智能提示, 那么使用 Continue 搭建本地的智能代码提示, 也能达到比较好的效果 (当然不能与收费的 GitHub Copilot 媲美)。
Continue 介绍
以下功能介绍搬运自 Contine 的官方代码库。
Continue 是领先的开源代码助手。您可以连接任何模型和任何上下文,以在 VS Code 和 JetBrains 中构建自定义自动完成和聊天体验, 主要功能有:
更容易地理解代码片段 利用 AI 来解释代码段, 理解更容易。
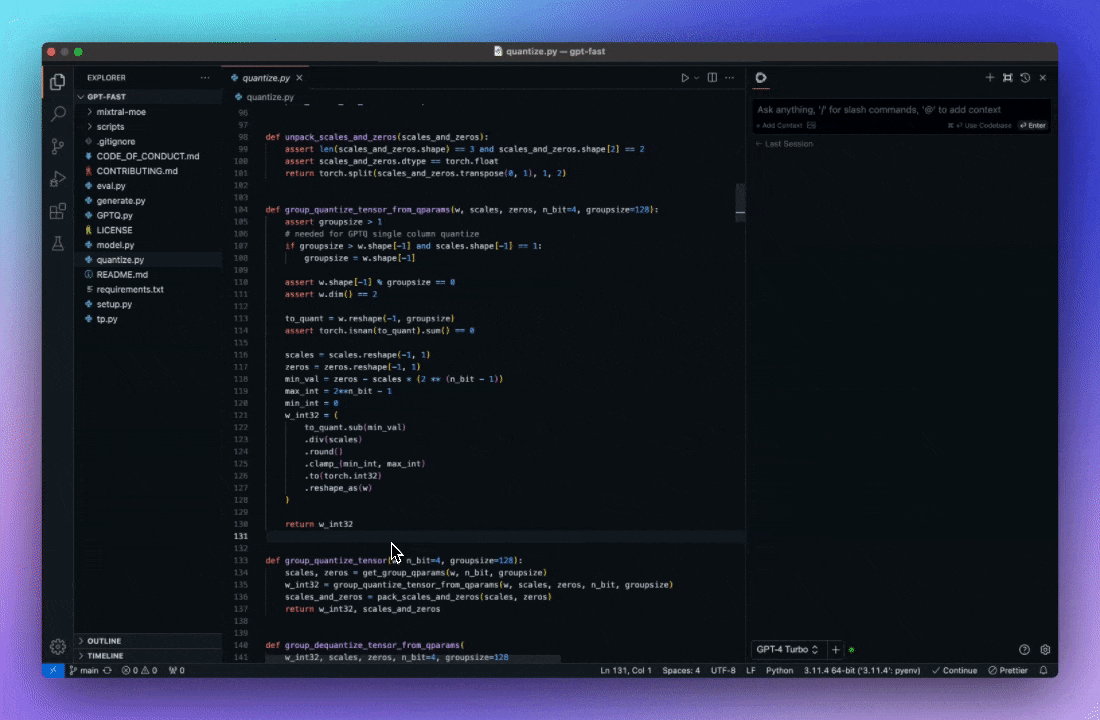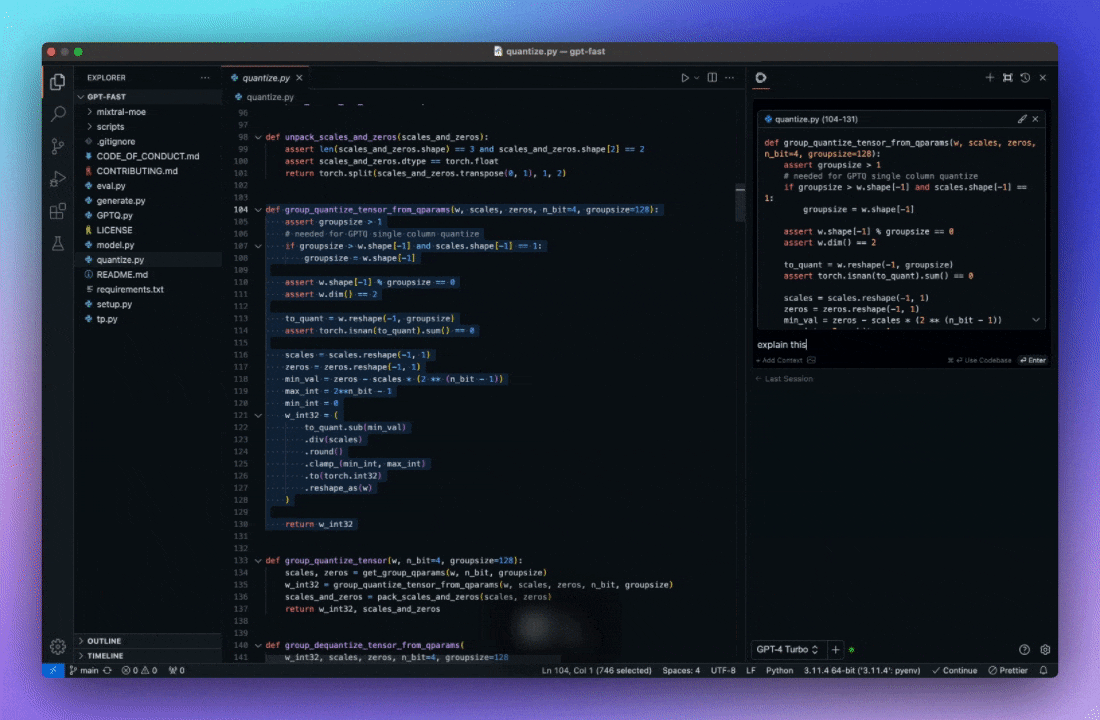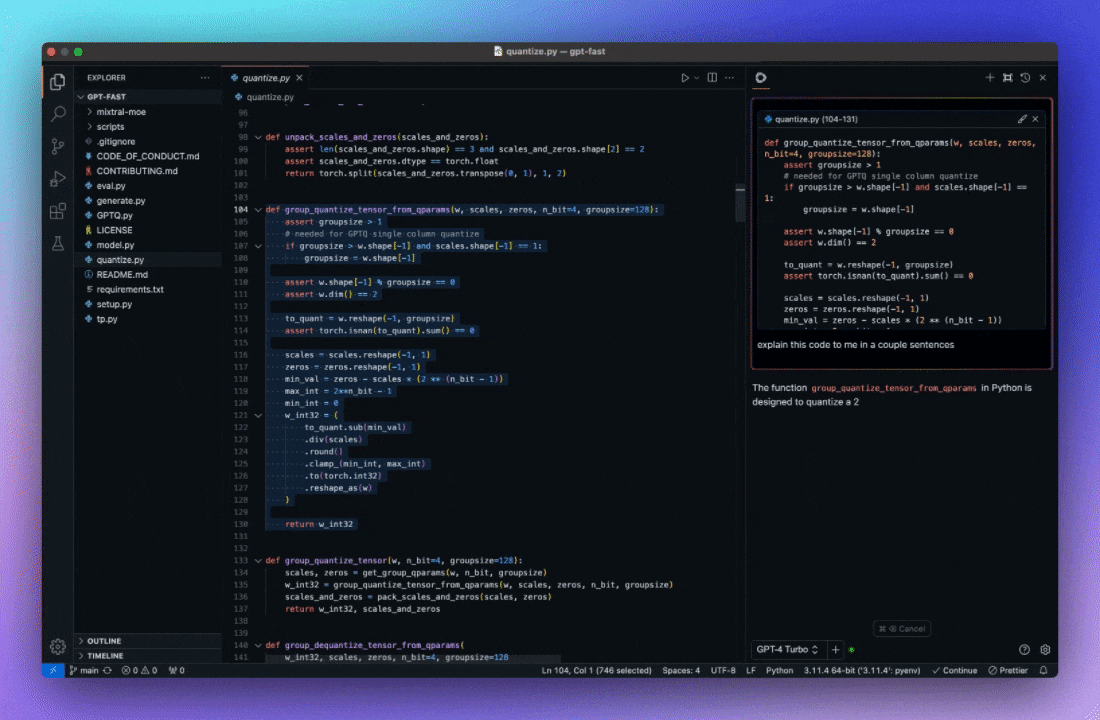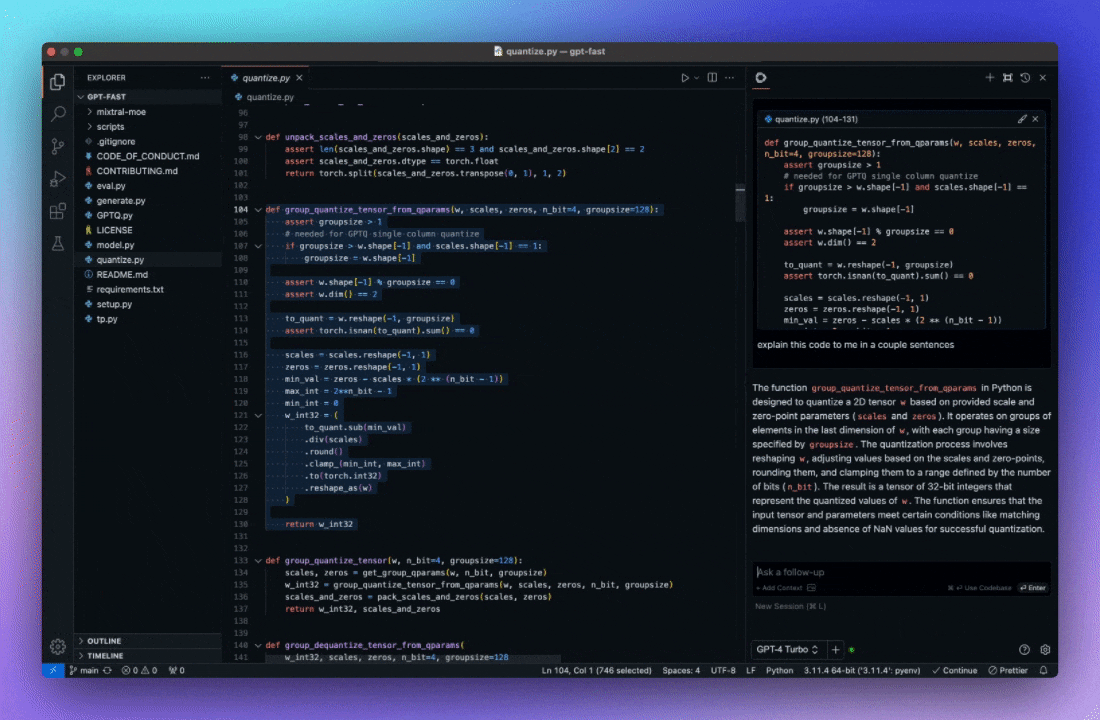
自动完成代码建议 利用 AI 理解代码上下文, 提供智能提示, 按 Tab 键自动补全。
随时重构 利用 AI 随时随地进行重构。

代码库问答 利用 AI 基于你的代码库进行问答。

快速文档上下文 快速使用框架的文档作为问答上下文。
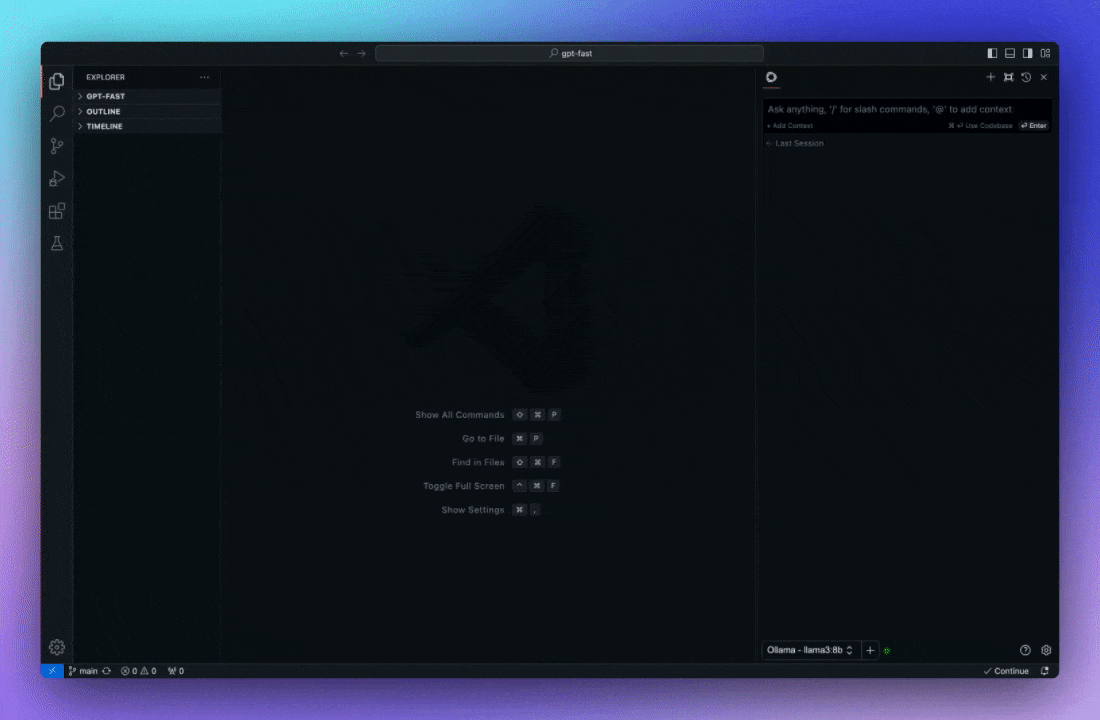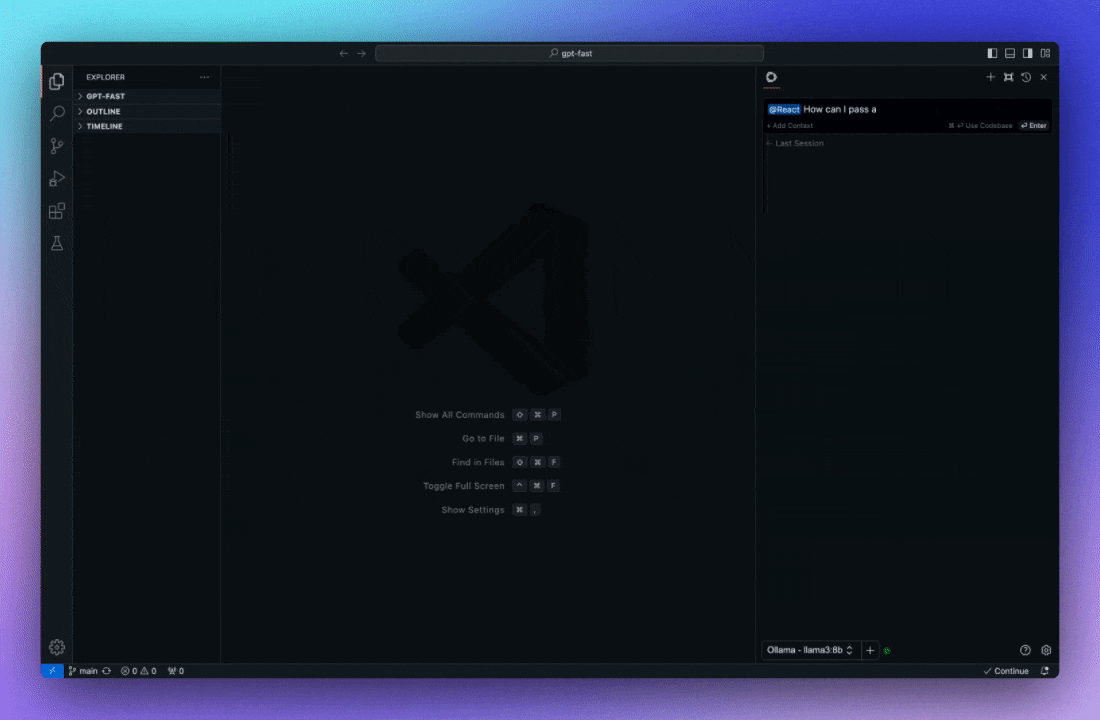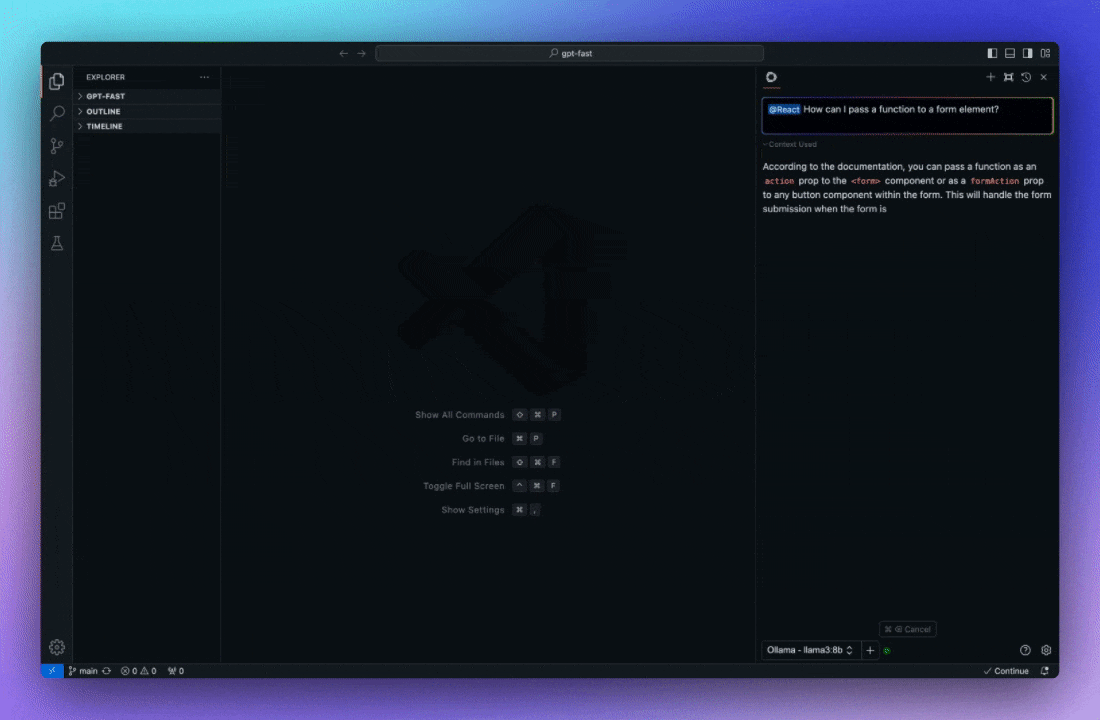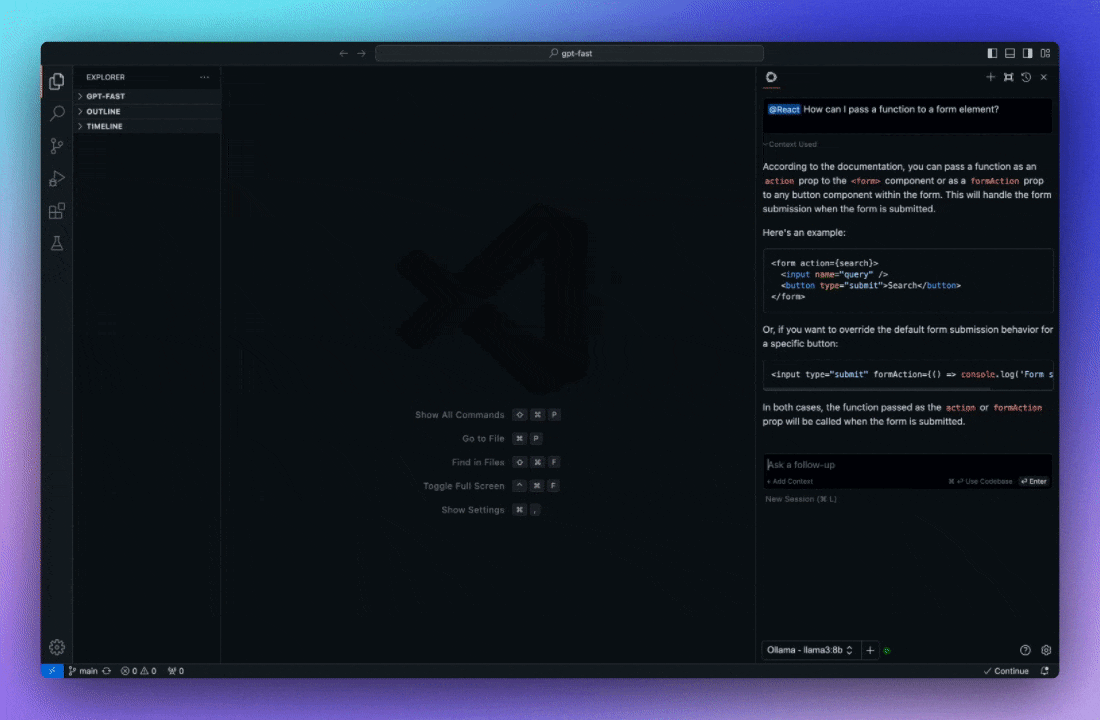
模型选择
Continue 支持的模型非常多,具体可以看 选择模型 这篇文档, 根据这篇文档的建议, 需要运行两个模型实例:
问答: 建议使用 30B 以上参数的模型, 文档给的建议是 llama-3 :
代码提示: 建议使用 1 ~ 15B 参数即可, 文档给的建议是:
DeepSeek Coder:
StarCoder 2 :
经过实际测试, 建议的本地运行模型为:
如果算力有限, 优先运行代码提示模型, 因为这个使用的频率非常高, 在输入代码的同时, 会频繁的调用。 问答模型用的频率比较低, 因为需要用户主动提问。
llama.cpp
建议使用 llama.cpp 来运行大模型, 因为 llama.cpp 提供了非常灵活的选项, 对硬件支持也比较完善。 不管你是 Windows 系统还是 M1 芯片的 Mac 系统, 独立显卡还是集成显卡,甚至是 CPU 是否支持 AVX 指令, 都有特定的预编译版本, 根据自己电脑的硬件信息下载预编译的 llama.cpp 二进制文件即可。
当然也可以根据 llama.cpp 的 说明文档 , 拉取源代码, 根据自身的硬件信息进行编译, 以获得最佳性能。
关于 llama.cpp 的使用, 可以参考文章 在 Macbook M1 上运行 AI 大模型 LLAMA , 文中也介绍了如何下载并转换模型文件。
运行代码提示模型
下载 starcoder2-7b 或者 starcoder2-3b 作为代码提示模型, 使用 llama.cpp 的 llama-server 运行, 命令如下:
llama.cpp/llama-server --host 0.0.0.0 --port 28080 \
--threads 8 --parallel 1 --gpu-layers 999 \
--ctx-size 8192 --n-predict 1024 --defrag-thold 1 \
--model models/starcoder2-3b-q5_k_m.gguf
如果只是个人使用的话, 对于代码提示来说,3b 就足够了。 当然, 如果 GPU 算力充足的话, 也可以运行 7b 或者更高的模型。
经过测试, starcoder 提供的提示效果比 deepseek-coder 要好很多。
运行问答模型
下载 llama-3-8b 作为问答模型, 同样使用 llama.cpp 的 llama-server 运行, 命令如下:
llama.cpp/llama-server --host 0.0.0.0 --port 8080 \
--threads 8 --parallel 1 --gpu-layers 999 \
--ctx-size 8192 --n-predict 1024 --defrag-thold 1 \
--model models/meta-llama-3-8b-instruct.fp16.gguf
Continue 安装与配置
Continue 提供了 Jetbrains IDE 以及 VSCode 的插件, 以 VSCode 为例, 只需要在 VSCode 的扩展窗口中搜索 Continue.continue , 下载并安装即可。
安装之后, 可以直接跳过 Continue 的向导提示, 然后编辑它的配置文件 ~/.continue/config.json , 直接复制粘贴下面的 json 内容:
{
"models": [
{
"title": "LLaMA",
"provider": "llama.cpp",
"model": "llama3-8b",
"apiBase": "http://127.0.0.1:8080"
}
],
"tabAutocompleteModel": {
"title": "LLaMA",
"provider": "llama.cpp",
"model": "starcoder2-3b",
"apiBase": "http://127.0.0.1:28080"
},
"allowAnonymousTelemetry": false,
"embeddingsProvider": {
"provider": "transformers.js"
}
}
保存配置文件,Continue 插件会自动根据配置文件自动更新。
starcoder 模型支持 10 多种常见的开发语言, 因此只要配置好了 Continue 插件, 不管是写前端代码还是后端代码, 都可以享受 AI 带来的智能提示。
如果你的电脑 GPU 算力充足, 还可以把这个配置分享内网的小伙伴, 一起分享 AI 带来的便利。
总结
本地运行的优势就不依赖互联网网络, 几乎没有什么网络延时, 也不需要注册什么账户之类的操作, 没有任何敏感代码泄漏的风险。 主要是显卡的负载,CPU 负载不高, 所以也几乎感觉不到卡顿。
