嘿嘿嘿,刷百度贴吧太爽了,但是等级太低在贴吧中发言貌似显得比较萌新,然而除了水贴之外升级最重要一个途径便是签到,关注了很多吧,每天一个一个点签到太麻烦了,怎么才能更方便快速地一次把关注的吧全签到了呢?
有了!
百度贴吧签到是POST请求,不如使用Python中的request模块,通过编写一键签到脚本来实现这个需求吧!
指定计划!
[ol]
[/ol]
开始行动!
1.分析得到贴吧“签到”的请求地址
直接到任意一个已经关注的贴吧的主页,打开F12,我使用的是谷歌的调试工具,打开“网络(Network)”标签,开始抓包!
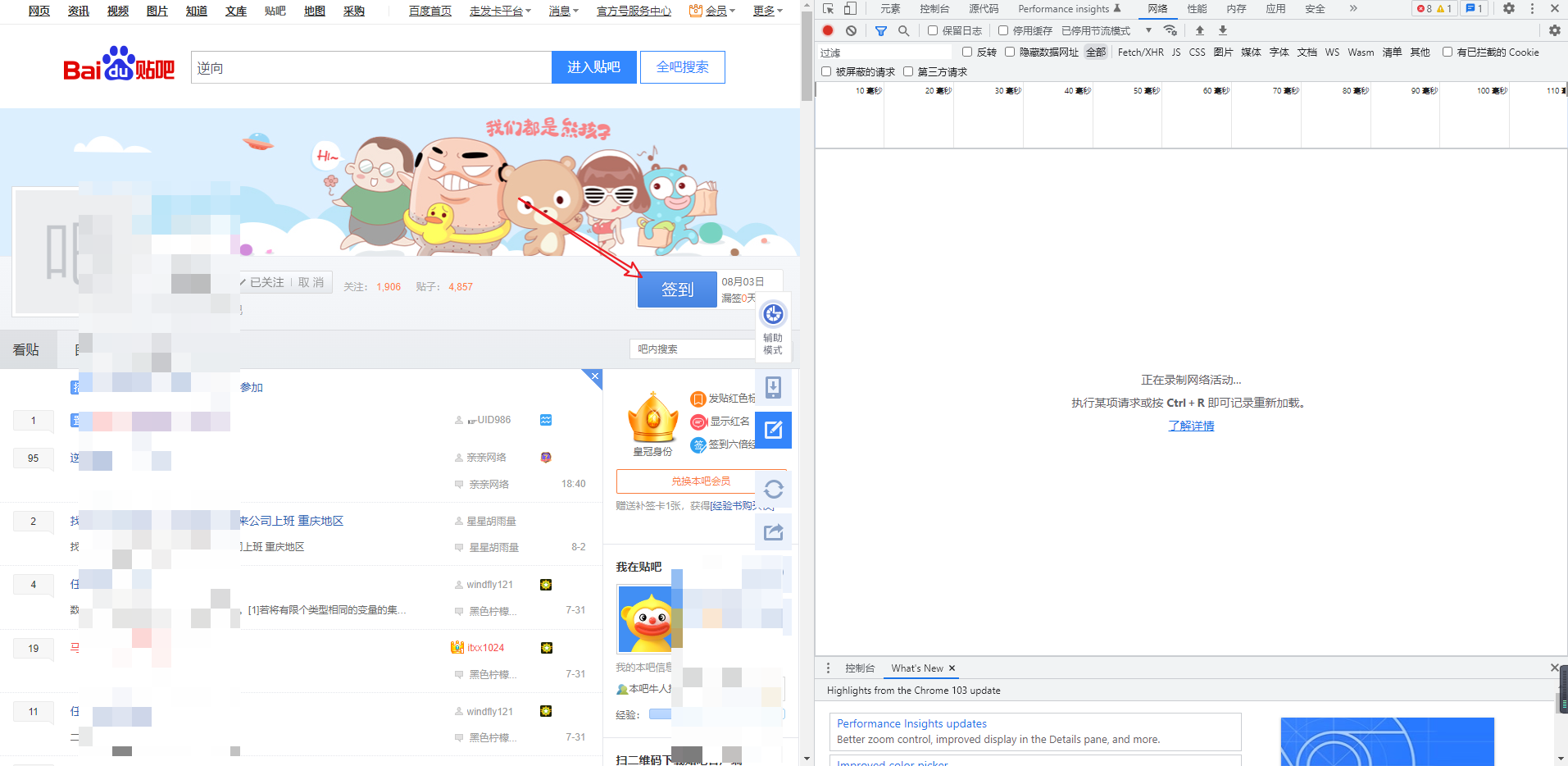
点击“签到”按钮,得到POST请求地址和参数

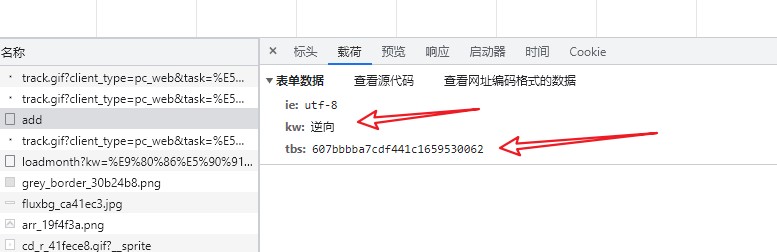
有三个参数,“ie”指的就是编码,默认即可,“tw”经过测试发现指的就是贴吧名字,需要添加变量,而这个“tbs”是什么呢?经过测试发现每次都在变,所以先在页面Ctrl+U得到HTML代码,搜索试试!

喔,果然搜到了,看来还需要使用一些操作得到这串字符啊!
没关系,交给正则表达式来解决!
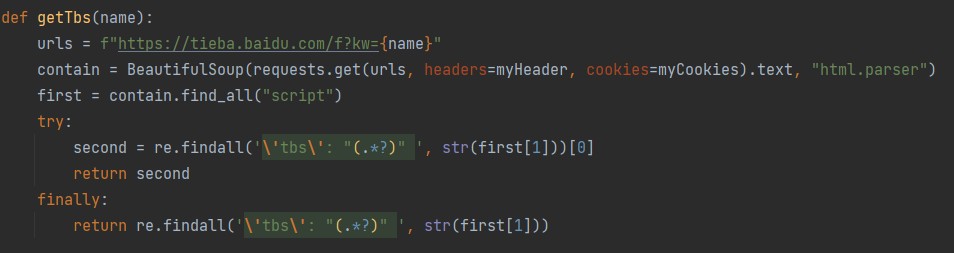
大功告成,模拟签到部分的代码我们就已经编辑好了,只需要知道贴吧名字即可,我们把他封装成函数,变量为贴吧名字,代码如下:
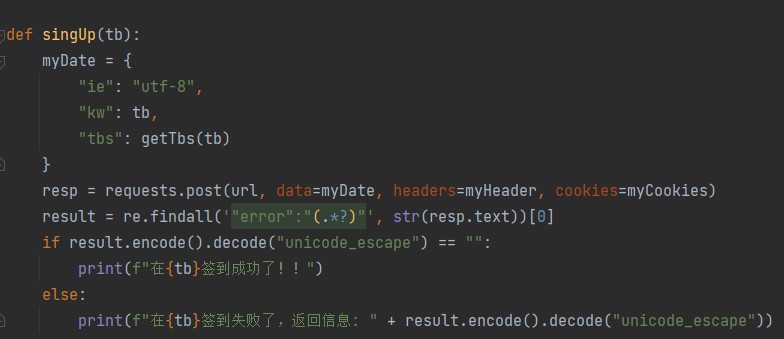
2.得到账号下关注的吧,遍历,签到
感谢@百度贴吧官方,为我们提供了 “https://tieba.baidu.com/f/like/mylike” 从而让我们方便地就能看到账户下已经关注的贴吧
F12稍微分析,好家伙,太方便了,直接就是一个列表,一堆\[tr]:

此时我们的函数就写出来了(得到关注的吧的名字),我们选择直接遍历,得到名字之后直接签到,这样省时又省力啊!

大功告成,签到成功!舒服了~
全部代码如下:
import requests
from bs4 import BeautifulSoup
import re
myHeader = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
myCookies = {
"Cookie": "###"
}
url = "https://tieba.baidu.com/sign/add"
def getTblikes():
i = 0
url = "https://tieba.baidu.com/f/like/mylike"
contain1 = BeautifulSoup(requests.get(url=url, cookies=myCookies, headers=myHeader).text, "html.parser")
pageNum = len(contain1.find("div", attrs={"class": "pagination"}).findAll("a"))
a = 1
while a
(有部分坛友反馈看不懂,不知道怎么用,有很多人这样吗?到时我看下上传个详细教程或者传一份编译后的exe版本)
