某云空间推理验证码识别模型训练
声明
仅关注于模型训练,不涉及JS逆向
不提供成品模型
不提供数据集
仅供学习交流使用,请勿用于非法用途
如有侵权,请联系作者删除
验证码示例

image.png (113.55 KB, 下载次数: 0)
下载附件
示例图
2025-7-3 19:28 上传
验证码分析
上图所示验证码,验证的题目是点击最小型多面体,鼠标点击的前提是知道最小型多面体的坐标,几何体的坐标是通过验证码的关键。
在此我们借助YOLOv8模型帮我们实现图中几何体位置识别的功能;
我们期望模型的输入是一张图片,模型输出为示例图片几何体的分类和坐标;
几何体类别
验证码中几何体分为以下5类
技术栈
Ultralytics
Ultralytics是一个专注于计算机视觉和深度学习领域的开发者团队
。他们致力于提供易于使用的工具和库,以帮助开发人员训练、评估和部署深度学习模型。Ultralytics的重点领域包括目标检测、图像分类、图像分割以及YOLO(You Only Look
Once)对象检测等,Ultralytics团队开发了YOLO系列模型的多个版本,包括YOLOv5和YOLOv8等
YOLO
YOLO(You Only Look Once)是一种流行的目标检测算法,由Joseph
Redmon等人提出。该算法将目标检测问题转化为单个神经网络的回归问题,通过将图像分成网格并在每个网格中预测边界框和类别信息来实现目标检测。YOLO的主要优点是实时性和简单性,能够在保持很高准确率的同时实现非常快速的检测速度。
训练步骤
[/ol]
环境准备
Python版本
Python>=3.8
Python依赖
ultralytics
Torch>=1.8
onnxruntime
onnx
标注相关工具
labelme
labelme2yolo
环境安装
pip install ultralytics
pip install torch==2.3.1
pip install torchvision==0.18.1
pip install onnxruntime
pip install onnx
pip install labelme
pip install labelme2yolo
安装过程中遇到问题?
请跳转【遇到问题】
数据集收集
编写爬虫采集验证码图片,与对应问题(示例:请点击最小型多面体),保存到本地;
本例数据集点击附件下载即可;
数据集标注
[ol]
[/ol]
labelme
[/ol]
这里准备了一张GIF演示图,但是尺寸较大,压缩之后还有17M,无法上传
使用多边形、矩形、AI多边形标注均可
[/ol]
数据集拆分
按8:1:1 拆分train val test数据集
转换格式
运行终端命令
labelme2yolo --json_dir /path/to/images_dir/ --val_size 0.1 --test_size 0.1
-其余为train数据集占比
训练集(Train Set)是模型学习的主要数据来源
验证集(Validation Set)用于在训练过程中评估模型的性能
测试集(Test Set)用于在模型训练完成后进行最终的评估
数据集文件层级结构
[ol]
运行上面的命令之后,自动调整格式如下
image.png (11.16 KB, 下载次数: 0)
下载附件
文件格式
2025-7-3 19:32 上传
YOLODataset目录移动到项目根目录
调整 dataset.yaml 如下
train、val、test更改为绝对路径
[/ol]
train: /YOLODataset/images/train
val: /YOLODataset/images/val
test: /YOLODataset/images/test
nc: 5
names: [ "圆柱体", "正方体", "球体", "圆锥体", "多面体" ]
**注意: 自动生成names元素顺序不能修改
["圆柱体", "正方体", "球体", "圆锥体", "多面体"]
索引从0开始,0-4代表分类的class_id
模型训练
[ol]
[/ol]
from ultralytics import YOLO
# yolo提供的预训练模型
model = YOLO("yolov8s.pt")
results = model.train(data="YOLODataset/dataset.yaml",
# 训练批次
epochs=200,
device='cpu',
workers=0,
batch=16,
# 图片尺寸,设置为32的倍数,图片尺寸为300,则此处设置为320
imgsz=320,
name='某云空间推理',
# 连续50个批次没有改善则停止训练
patience=50)
# 训练完成后导出为更通用的onnx格式
model.export(format="onnx", imgsz=[320, 320])
[/ol]
cd
python3 train.py
mAP50 mAP50-95 表示模型的精度
官方表述精度在0.8以上就可以说是一个不错的模型
image.png (102.74 KB, 下载次数: 0)
下载附件
2025-7-3 19:35 上传
[/ol]
模型训练结果
训练完整后会自动生成如下的目录结构
image.png (93.6 KB, 下载次数: 0)
下载附件
2025-7-3 19:36 上传
其中:
weights文件夹下的3个文件是模型的训练结果
best.pt / best.onnx 代表最优的模型
results.csv 为训练日志,记录训练过程中每一个Epoch对应的训练效果
result.png 为基于results.csv画出的训练效果图
模型预测
预测脚本
from ultralytics import YOLO
model = YOLO(r"best.onnx", verbose=False)
print('class id 与 class name的映射关系', model.names)
results = model.predict(source=r"YOLODataset/images/test/a15a9f080870221cdc78b938ae6e04a0.png",
# 线上运行时,save设置为False,避免产生大量图片
save=True,
name='效果预测',
imgsz=[320, 320],
verbose=False
)
for r in results:
print(r.boxes.data) # print the Boxes object containing the detection bounding boxes
其中
verbose表示关闭冗余日志
source指定预测的图片路径
save为True表示保存预测结果(图片)
imgsz指定图片尺寸(需与训练时尺寸一致)
脚本输出(预测信息)
输出内容为识别出的几何体坐标与类别,如下:
Loading vr.onnx for ONNX Runtime inference...
class id 与 class name的映射关系 {0: '圆柱体', 1: '正方体', 2: '球体', 3: '圆锥体', 4: '多面体'}
image 1/1
# 图片检测出的几何体的数量,与预测耗时
YOLODataset\images\test\a15a9f080870221cdc78b938ae6e04a0.png: 320x320 1 圆柱体, 1 正方体, 2 球体s, 1 圆锥体, 3 多面体s, 27.9ms
# 耗时
Speed: 2.0ms preprocess, 27.9ms inference, 2.0ms postprocess per image at shape (1, 3, 320, 320)
# 效果图保存位置
Results saved to runs\detect\效果预测
# 几何体坐标信息
tensor([[ 76.1425, 160.7676, 132.2246, 218.7767, 0.9792, 2.0000],
[ 32.9299, 86.5915, 89.2932, 143.4958, 0.9778, 2.0000],
[267.7635, 96.0283, 299.9066, 161.2132, 0.9665, 0.0000],
[102.8096, 106.6354, 153.9815, 161.0277, 0.9642, 4.0000],
[120.0532, 56.6311, 183.8257, 134.9832, 0.9637, 1.0000],
[182.0320, 148.9268, 235.8299, 202.1478, 0.9604, 4.0000],
[216.9868, 92.3001, 247.1553, 123.4389, 0.9479, 4.0000],
[165.5462, 33.3791, 207.6008, 94.0850, 0.9430, 3.0000]])
其中: 以[ 76.1425, 160.7676, 132.2246, 218.7767, 0.9792, 2.0000] 为例,
训练效果
效果图
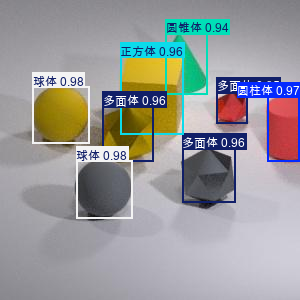
小结
本次训练
可能遇到的问题
问题1:UserWarning: Glyph 29699 (\N{CJK UNIFIED IDEOGRAPH-7403}) missing from font(s) DejaVu Sans.
原因: matplotlib画图时中文字符的问题,不影响训练结果,解决方法:暂时不需要处理
问题2:onnxruntime.capi.onnxruntime_pybind11_state.Fail: onnxruntime Model::Model Unsupported model IR version: 9, max supported IR version: 8
原因: onnxruntime 版本低, 升级到最新即可
解决方法:如下
pip install onnxruntime==1.19.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
问题3:OsError: WinError 126 找不到指定的模块。Erro loading "xxx\Lib\site-packages\torch\lib\fbgemm.dll" or one of its dependencies.
原因:缺少fbgemm的基础库
[ol]
libomp140.x86_64.zip
(315.8 KB, 下载次数: 3)
2025-7-3 19:44 上传
点击文件名下载附件
下载积分: 吾爱币 -1 CB
)
[/ol]
