github 后端地址
github 前端地址
起因 0:
大约两周前在 v 站上看到一个 v 友做了个 GPT 套壳 然后赚了两百块,只是在心中暗暗羡慕了一下 但是也没有想自己做,重复造轮子嘛,没意思.所以就打开了 github,看看有没有大佬开源的,发现目前开源的多半是 web,或者接入微信当个聊天机器人.而我主要是想分享给亲戚朋友用用,想着还是小程序方便点.
经过 0:
在我寻找的过程中一个叫Railway的东西吸引了我,我也进去浅浅的尝试了一下,感觉很不错(可以自动将 github 上的代码打包部署,自动探测语言和打包方式)可以实现 github 上的项目一键部署.而且每个月有$5 的免费额度.
然后我就接着找,终于在 gitee 上找到个开源的 gpt 小程序套壳
于是我就把这个开源项目部署到了Railway上,深度体验了下,真的很爽,几乎 0 配置,十分的丝滑.
要是到这里就结束的话,就没有下边我要说的开源项目了.
起因 1:
由于Railway只给了$5 的免费额度,我看了下这个服务的预估消费直接就奔着$7 去了,这是要让我充钱的节奏呀,不行...
本着能白嫖就坚决不给钱的精神,我在想怎么才能让他的内存占用更低!然后我想到了个一个一年前了解过,但是没深入研究过的东西,quarkus!这个东西不就是 cloud native 的,打包成 native excutable 那内存不就下来了吗?
经过 1:
于是我就开始了接近 1.5 周的学习&实践,不得不说quarkus的性能是真的好,但是写起来也真的坑呀,国内几乎没有文档可查,直接去官网找文档;
最开始我想全部使用 reactive 的形式来写后端,但是失败了,原因是quarkus的某些组件还并不支持 reactive 的方式(比如 http basic auth),我肯定是不想写个复杂的身份校验逻辑的,但是 http auth 又不支持 reactive,没办法,要么 reactive 要么 http auth,我最终选择了后者,所以现在项目中既有 reactive 也有 imperative 的代码.
quarkus 使用心得:
优点
缺点
所以最后我相当于研究了下 Quarkus&Railway,并以这个开源项目的形式展示出来,和大家一起交流下,当然如果对项目有兴趣的,可以直接把项目拿去用,个人只需要准备好
详细的信息都写到了 readme 里边
下面是小程序的体验码:

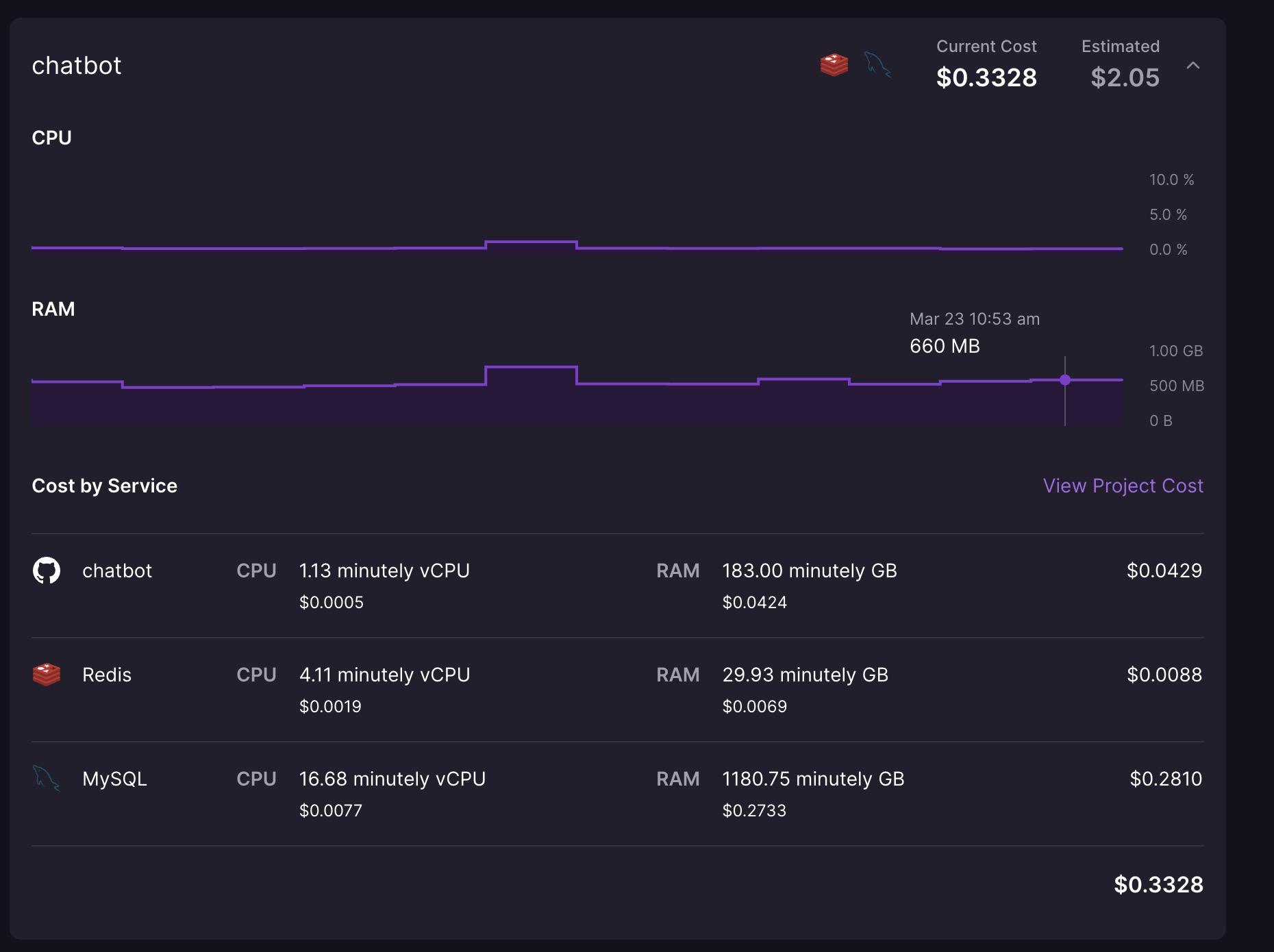
再贴下内存消耗的对比图:
quarkus 的
springboot 的
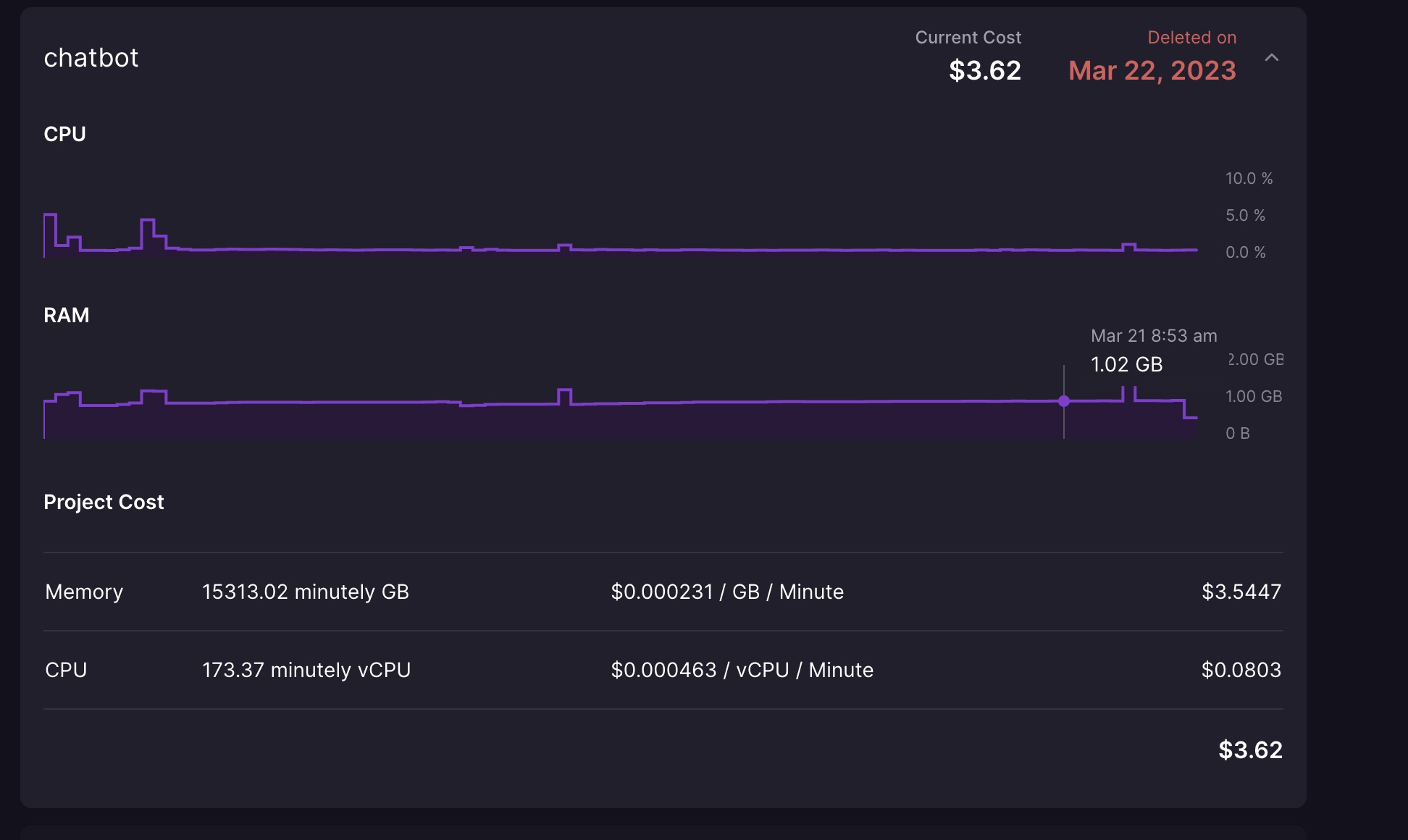
大家可以看到内存直接下降了 500m 500m 什么概念,500m 的意思就是我可以白嫖了,如果还不行,我打算把 mysql 干掉,现在大多数内存都是 mysql 用的...
还有个很爽的地方!众所周知,编译成原生可执行文件非常吃电脑性能,我的是 m1 的 air 编译的时候我基本上啥都干不了,而且大概编译时间会持续 10-20 分钟不等,但是如果我们使用了 Railway 我们可以把编译这个动作交给 Railway 来做,不需要你本地编译,让 Railway 编译,而且编译是不算钱的!!!!这点真的很良心,而且 Railway 编译机器的性能真的很好,我测试的时候基本上在 5 分钟左右就编译好了!
下面放个启动时间让大家爽一下:
[io.quarkus] (main) chatbot 1.0-SNAPSHOT native (powered by Quarkus 2.16.4.Final) started in 0.198s
这次启动的时间是包含了 flyway 执行 sql 脚本的时间的,要是没有 flyway 的话直接就是 0.0 几秒!
