在本文中,我们将深入介绍如何使用 PyGWalker 和 streamlit 来搭建一个交互式的数据可视化分析应用。
什么是 PyGWalker ?
PyGWalker 是一个将你的数据转化为一个交互式可视化分析应用(类似 tableau 或 powerBI )的 python 库。
例如在 Juypter Notebook 中,数据科学家经常使用 PyGWalker 将数据转化成一个嵌入在 juypter 里的交互模块,他们可以使用拖拉拽或自然语言的方式进行可视化探索,而不再需要书写任何代码或切换到其他工具中去。

使用 PyGWalker ,您可以通过简单的拖放操作轻松生成散点图、折线图、条形图和直方图,无需编码技能。它是一个专门为希望快速轻松地探索和可视化数据的数据科学家和分析师设计的强大工具。PyGWalker 底层默认使用了 duckdb 作为计算引擎,这使得你基于 pygwalker 搭建的应用会具备非常客观的性能。
什么是 Streamlit ?
Streamlit 是另一个流行的 Python 库,用于构建和共享数据应用程序。它可以让您将数据脚本在几分钟而不是几周的时间内转化为 Web 应用程序。
你可以认为 streamlit 是一个面向数据科学家的 flask ,它可以让你快速的搭建一个数据应用,而不需要你去学习任何 web 开发的知识。streamlit 使得我们可以把 pygwalker 变成一个线上的 web 应用,从而分享给其他人。并且 pygwalker 可以让你搭出交互的可视化应用,而不仅仅是静态的数据报表。你的用户也可以提出问题,根据自己的需求再去探索。
那么如何使用 PyGWalker 和 Streamlit 构建一个具有强大可视化分析功能的可视化探索应用,并将其发布为数据应用程序呢?让我们来看看吧!
开始使用 PyGWalker 在 Streamlit 中
在开始在 Streamlit 中运行 PyGWalker 之前,让我们确保您的计算机已经设置了 Python 环境(版本 3.6 或更高)。完成后,请按照以下简单步骤操作:
安装依赖项
首先,打开命令提示符或终端,并运行以下命令以安装所需的依赖项:
pip install pandas
pip install pygwalker
pip install streamlit
将 PyGWalker 嵌入 Streamlit 应用程序
现在,我们已经安装了所有必要的依赖项,让我们创建一个包含 PyGWalker 的 Streamlit 应用程序。创建一个名为 pygwalker_demo.py 的新的 Python 脚本,并将以下代码复制到其中:
import pygwalker as pyg
import pandas as pd
import streamlit.components.v1 as components
import streamlit as st
# 调整 Streamlit 页面的宽度
st.set_page_config(
page_title="在 Streamlit 中使用 PyGWalker",
layout="wide"
)
# 添加标题
st.title("在 Streamlit 中使用 PyGWalker")
# 导入您的数据
df = pd.read_csv("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/public-datasets/bike_sharing_dc.csv")
# 使用 PyGWalker 生成 HTML
pyg_html = pyg.to_html(df)
# 将 HTML 嵌入到 Streamlit 应用程序中
components.html(pyg_html, height=1000, scrolling=True)
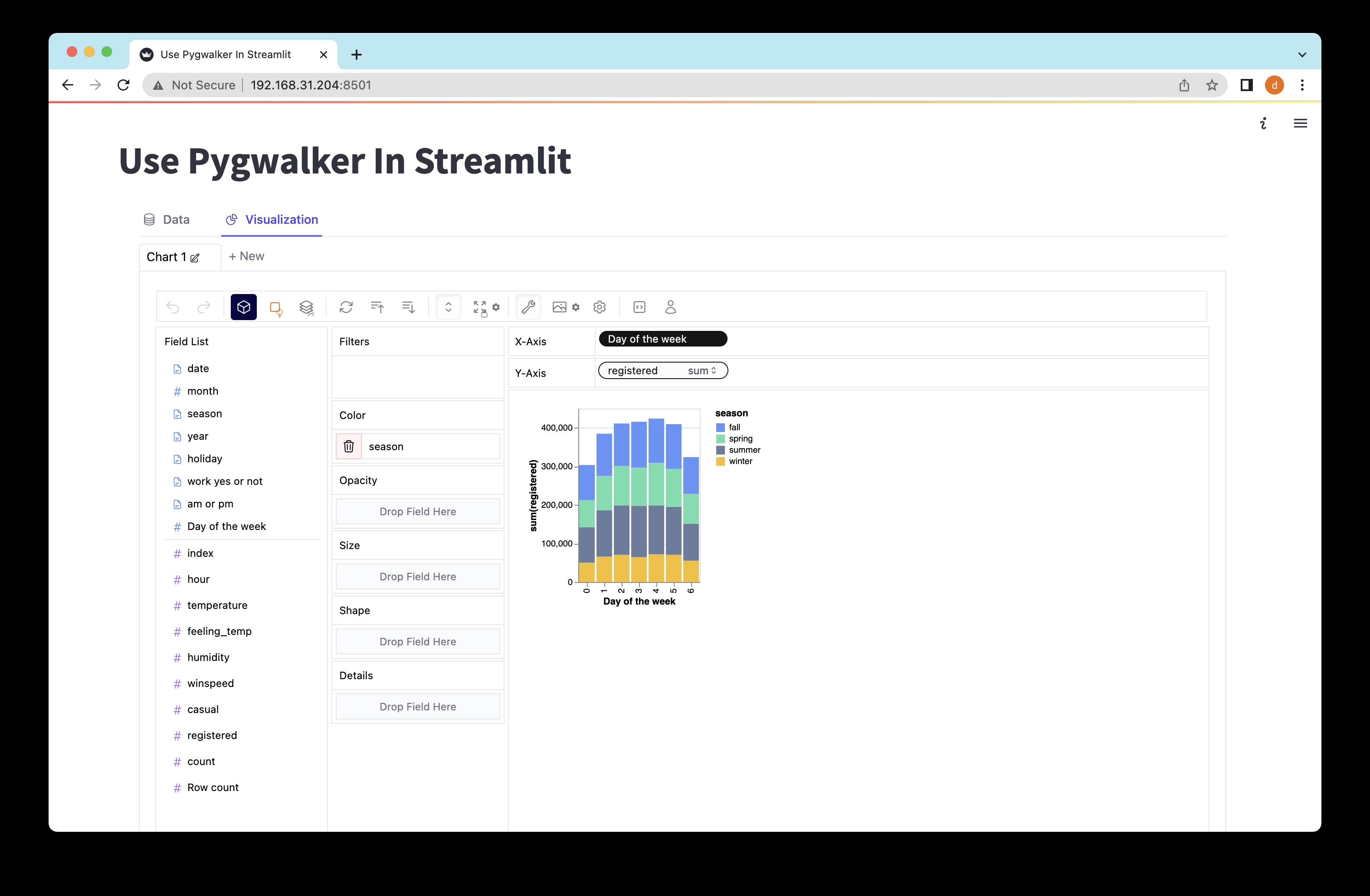
在 Streamlit 中探索数据使用 PyGWalker
要启动 Streamlit 应用程序并开始探索数据,请在命令提示符或终端中运行以下命令:
streamlit run pygwalker_demo.py
您应该会看到一些显示的信息:
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://xxx.xxx.xxx.xxx:8501
在您的网络浏览器中打开提供的 URL (http://localhost:8501),完成!您现在可以使用 PyGWalker 的直观拖放操作与您的数据进行交互和可视化。
保存 PyGWalker 图表状态
如果您想保存 PyGWalker 图表的状态,只需按照以下步骤进行操作:
[ol]
[/ol]
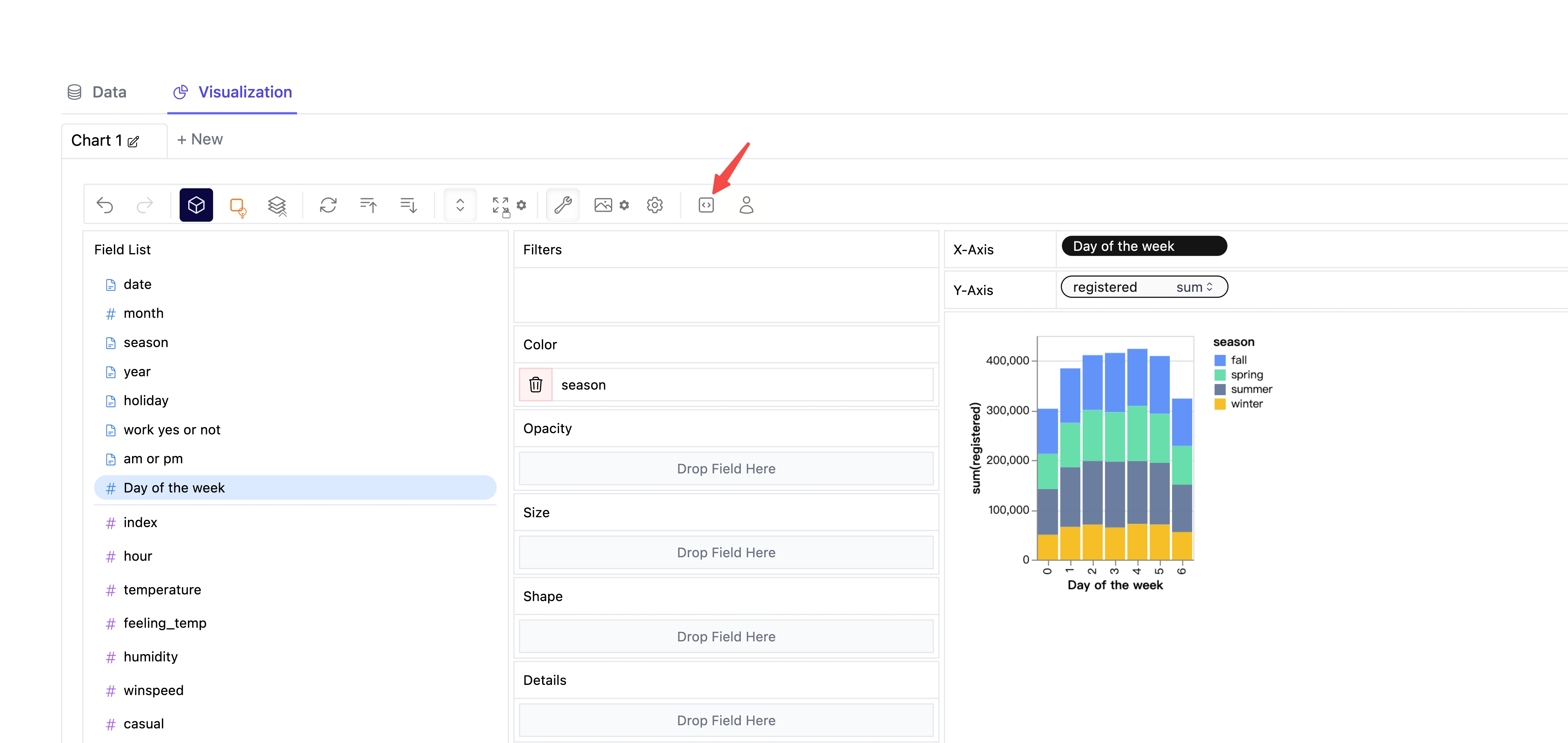
[ol]
[/ol]
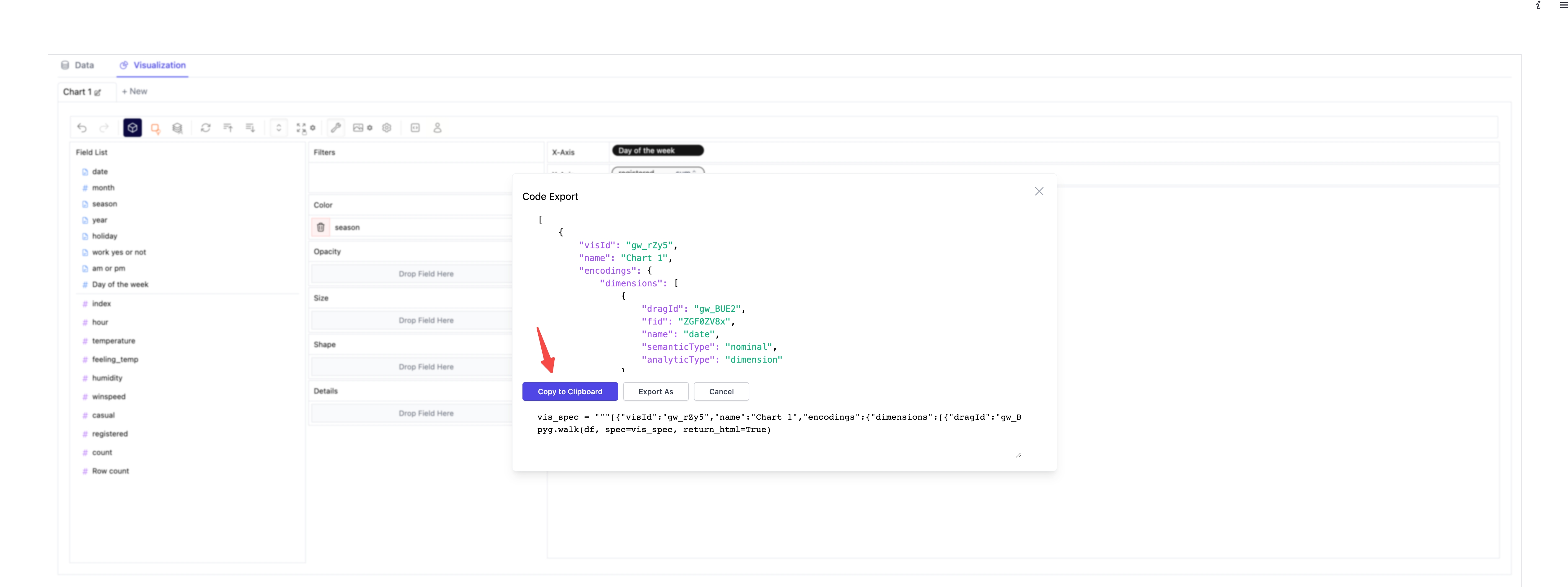
[ol]
[/ol]
import pygwalker as pyg
import pandas as pd
import streamlit.components.v1 as components
import streamlit as st
# 调整 Streamlit 页面的宽度
st.set_page_config(
page_title="在 Streamlit 中使用 PyGWalker",
layout="wide"
)
# 添加标题
st.title("在 Streamlit 中使用 PyGWalker")
# 导入您的数据
df = pd.read_csv("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/public-datasets/bike_sharing_dc.csv")
# 粘贴已复制的 PyGWalker 图表代码
vis_spec = """"""
# 使用 PyGWalker 生成 HTML
pyg_html = pyg.to_html(df, spec=vis_spec)
# 将 HTML 嵌入到 Streamlit 应用程序中
components.html(pyg_html, height=1000, scrolling=True)
[ol]
[/ol]
进阶功能
如果你想在 streamlit 中启用 pygwalker 底层的 duckdb 计算引擎,来支持更大规模的数据/更快的运算。可以参考pygwalker 的 API 文档。
同时 pygwalker 也支持直接传入一个 snowflake 连接,从而支持处理更大规模的数据。
总结
你可以使用 pygwalker + streamlit 搭建 dashboard 甚至是简单的 CRM 。pygwalker 为你提供了数据相关的能力,streamlit 为你提供了 web 服务相关的功能。
也欢迎大家在 github 关注 pygwalker 的后续更新。
参考资料
