前言
编写这脚本,是基于文科领域学术目的而使用的:就我入手网络平台言论调查选题研究分析,进而B站的弹幕、评论进行综合调研而做的。就网络讨论涉及到亚文化、民生类(当前查阅资料中)的内容非常之多,需要细致的查阅资料,分析、补充与总结。
因内容过多,体量较大,本次就以图链的形式展示:
一、对亚文化视域评论及弹幕调研.ipynb
https://cdn.jsdelivr.net/gh/hoochanlon/scripts/AQUICK/catch2023-06-28%2001.19.51.png
二、https://cdn.jsdelivr.net/gh/hoochanlon/scripts/AQUICK/catch2023-06-28%2001.24.38.png
原计划做完当前“亚文化”、“民生”板块内容调研,才打算公开的。考虑到部分研究该课题的学者及同学的需要,故放出。
功能&原理
脚本功能如下:
[ol]
[/ol]
脚本原理:
调用API进行查寻json信息,对json信息做遍历到xlsx文件,用语言模型 snowNLP、ThuNLP、Jieba 处理文本进行分词、过滤停用词,做文本词性分析与词频统计,最后使用matplotlib常规生成图表。
两大关键:
[ol]
[/ol]
如果没有他们,这几乎 —— 至少在短时间3~5天内,就我个人而言难以做到。尤其是反查UID,没有 Aruelius/crc32-crack 的公开算法,至少目前来说是不太可能做到的,该脚本就反查部分也是对其源码传参上进行微调,以适应我的脚本逻辑。
快速上手
(Windows 可以直接 pip、python;Mac默认是:pip3、python3)
脚本源码地址:https://github.com/hoochanlon/scripts/blob/main/d-python/get_bv_baseinfo.py
前提条件:安装工具库
pip3 install --no-cache-dir -r https://ghproxy.com/https://raw.githubusercontent.com/hoochanlon/scripts/main/d-txt/requirements.txt
然后运行该脚本(在线)
python3 -c "$(curl -fsSL https://ghproxy.com/https://raw.githubusercontent.com/hoochanlon/scripts/main/d-python/get_bv_baseinfo.py)"
效果概览
2023.6.26测试本地运行,PD虚拟机 win11。
使用方式及效果如下
嫌cookie输入太麻烦,可以用key=value; 的形式,如:"a=a;" 略过。
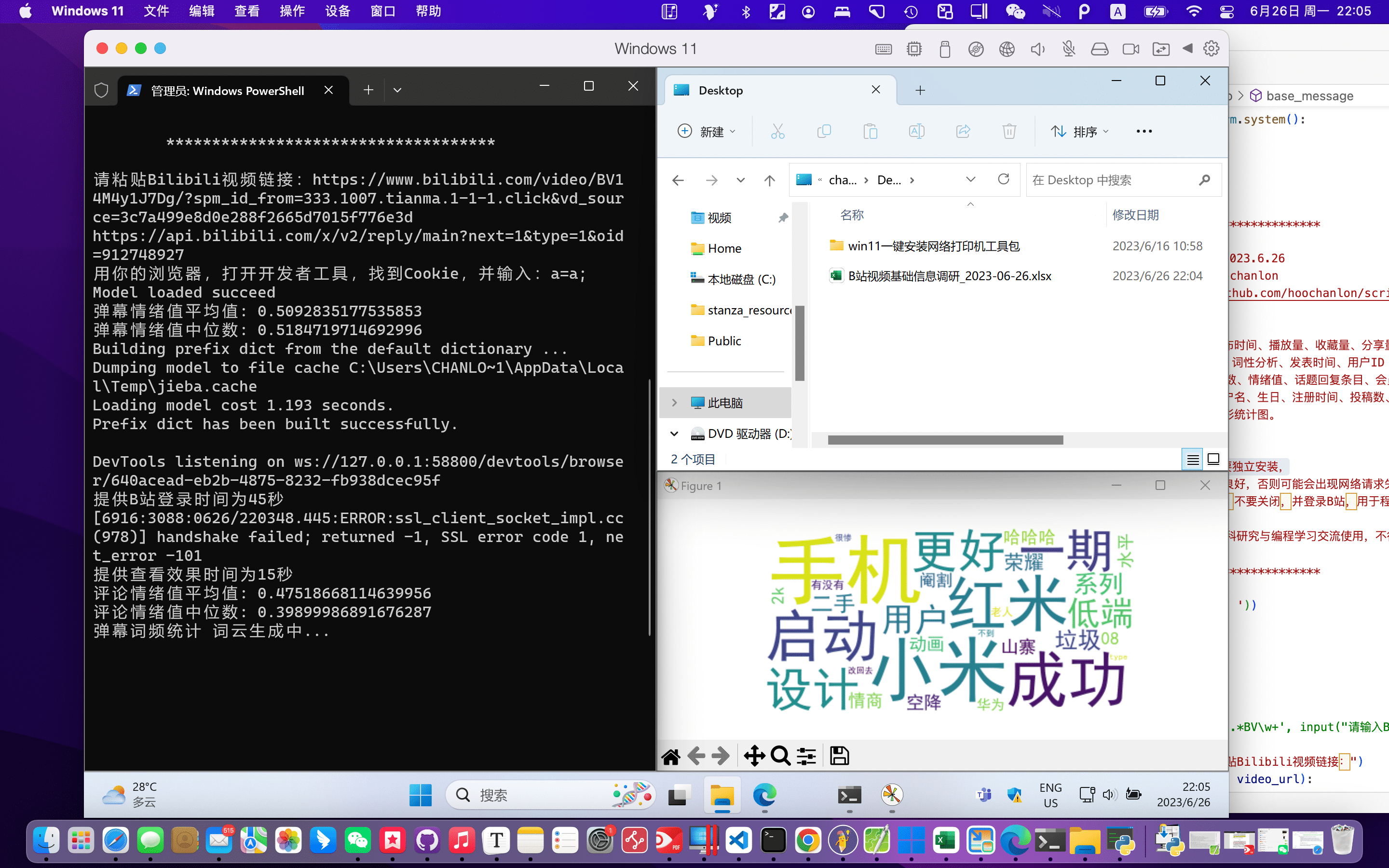
查看IP归属,需要在web driver登录你的b站账号。
2023.6.28
在webdriver登录b站账号
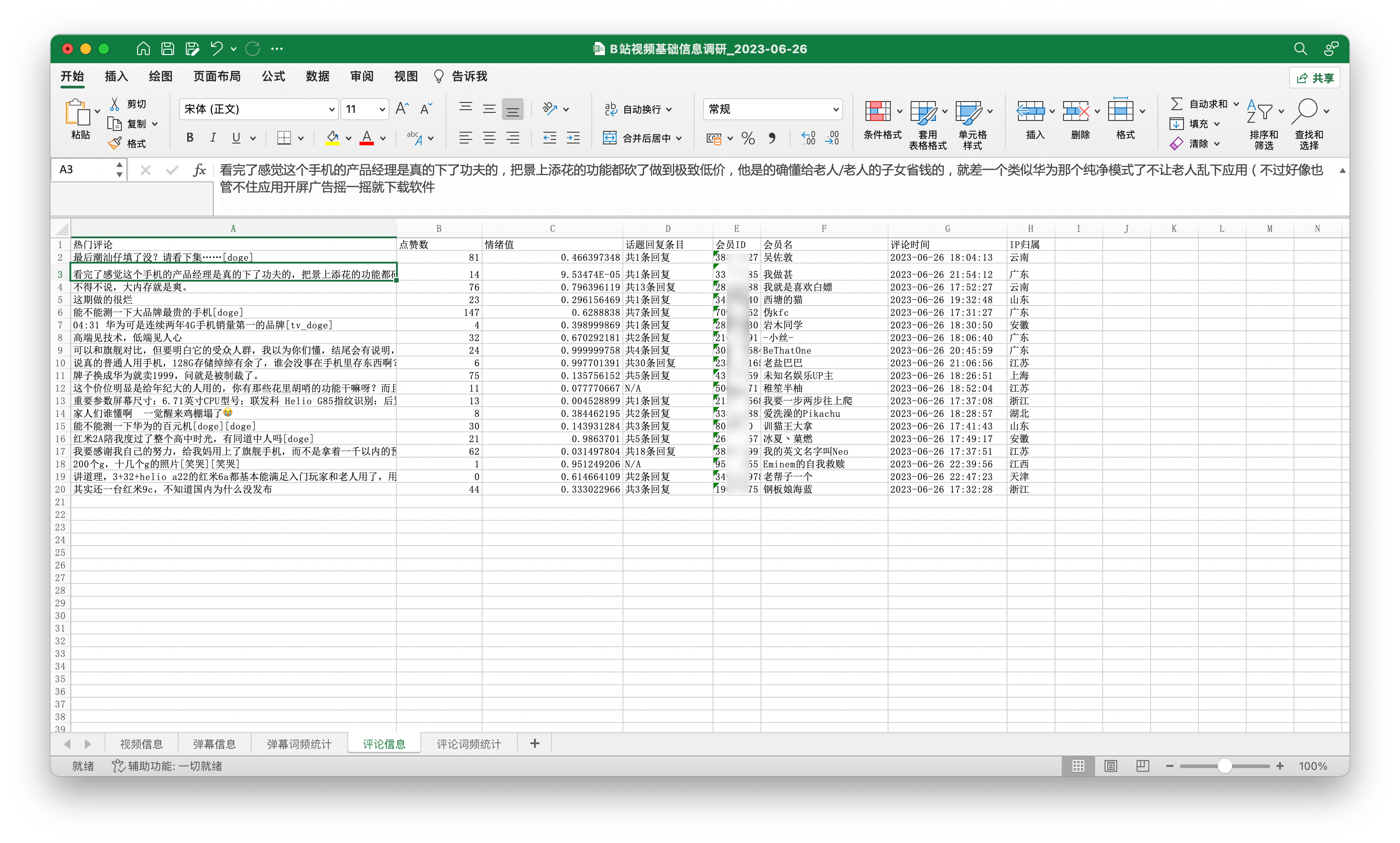
拿到ip归属。
见已生成的图表
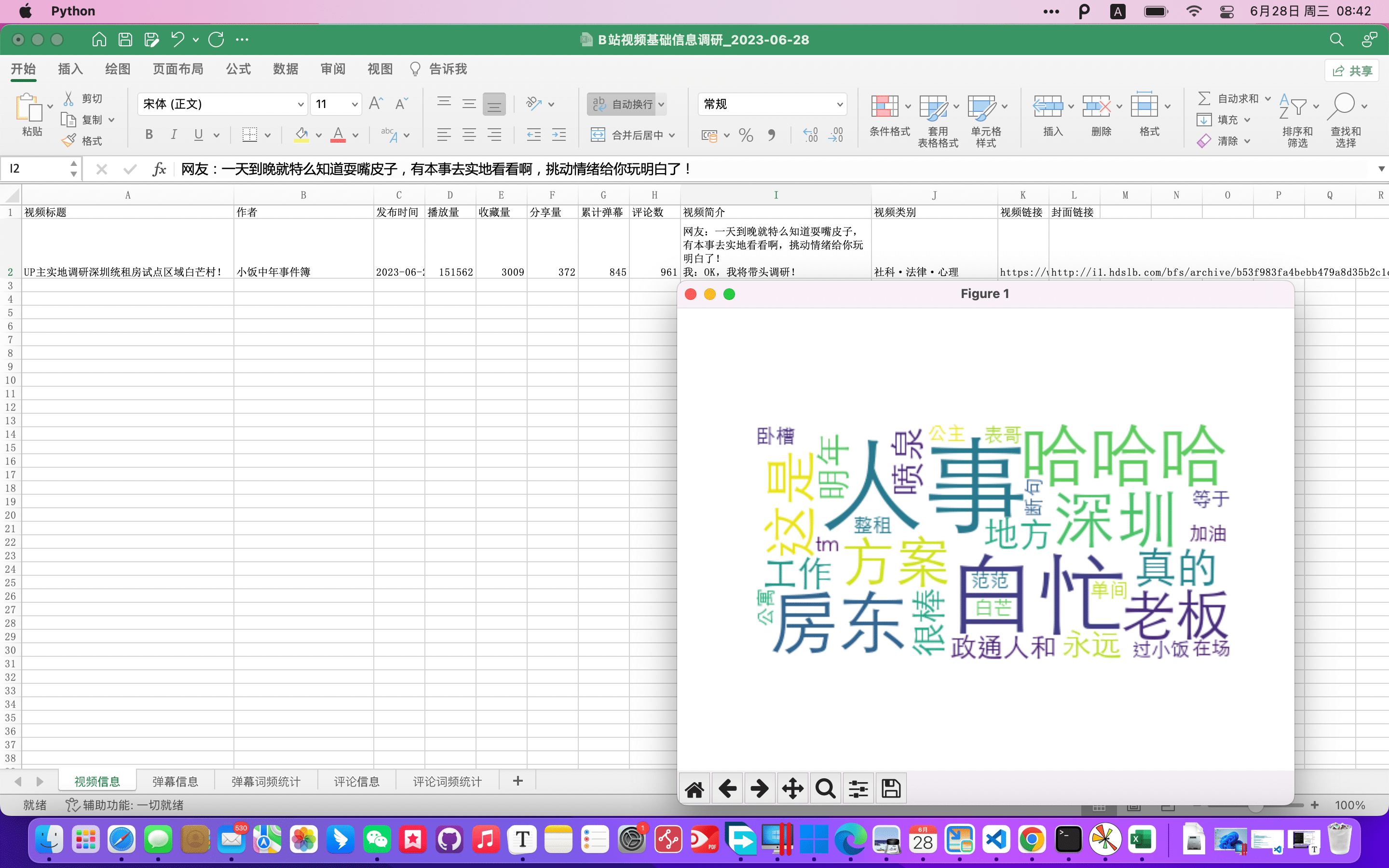
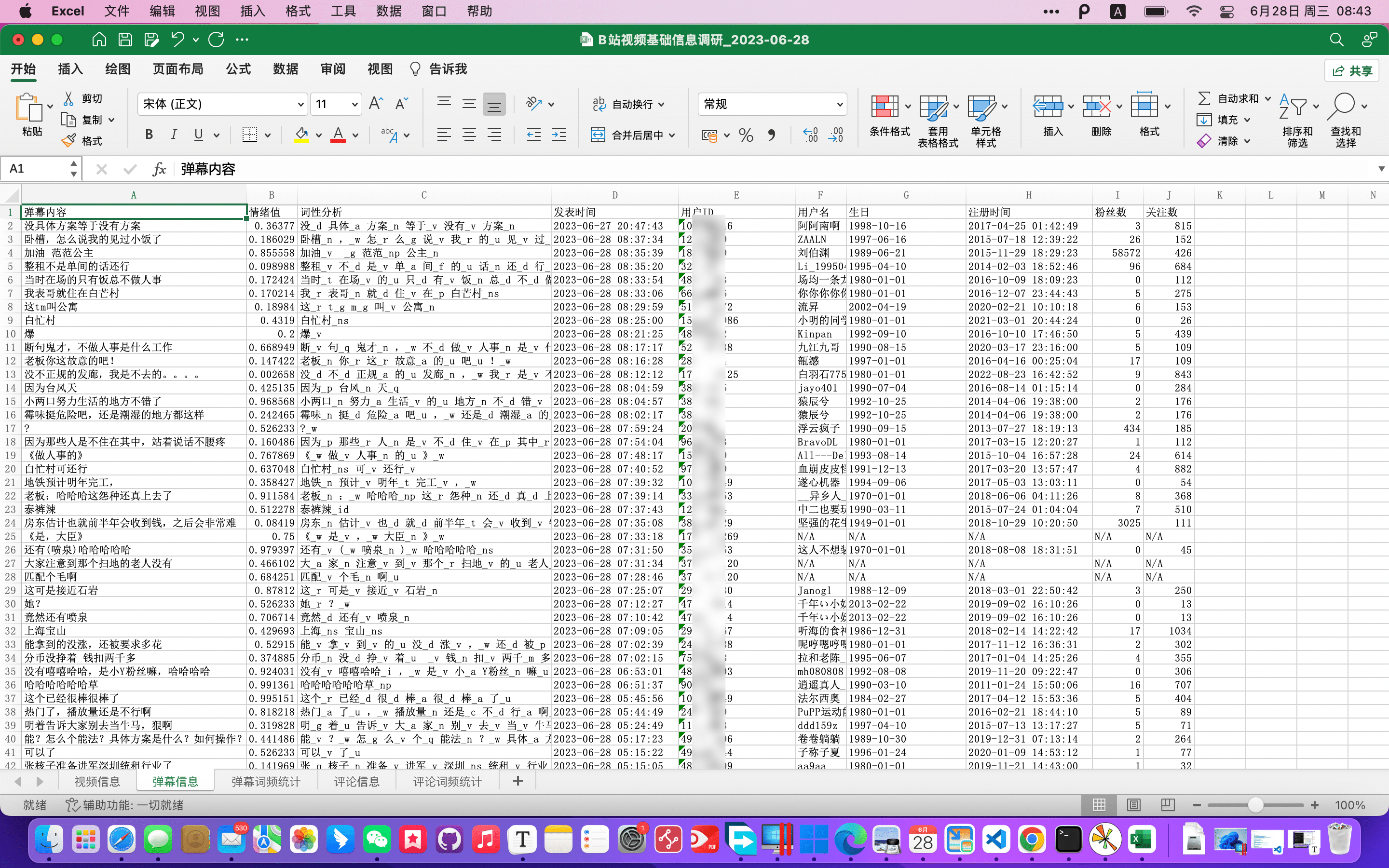
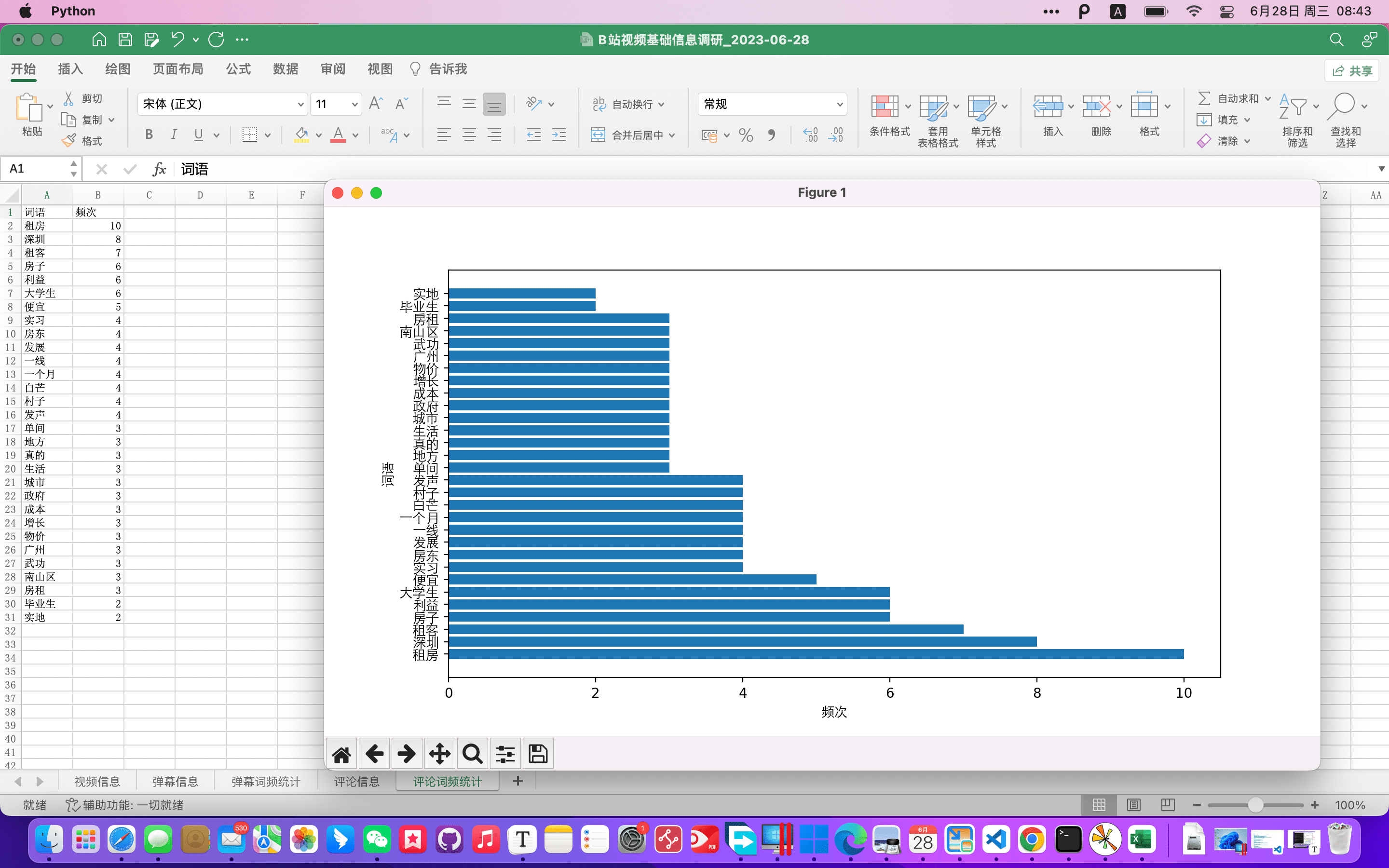
附源码
项目源码地址:https://github.com/hoochanlon/scripts/blob/main/d-python/get_bv_baseinfo.py
import json
import time
import requests
import os
from datetime import datetime
import re
from bs4 import BeautifulSoup
from openpyxl import Workbook
from openpyxl.styles import Alignment, Font
from snownlp import SnowNLP
import statistics
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import platform
import thulac
import matplotlib.font_manager as fm
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
'''''''''
# 参考链接
## 常规
正则表达式:https://regex101.com/
zhihu - 用Python获取哔站视频弹幕的两种方式:https://zhuanlan.zhihu.com/p/609154366
juejin - B站视频弹幕解析:https://juejin.cn/post/7137928570080329741
csdn - B站历史弹幕爬虫:https://blog.csdn.net/sinat_18665801/article/details/104519838
csdn - 如何写一只抓哔哩哔哩弹幕的爬虫:https://blog.csdn.net/bigbigsman/article/details/78639053?utm_source=app
bilibili - B站弹幕笔记:https://www.bilibili.com/read/cv5187469/
B站第三方API:https://www.bookstack.cn/read/BilibiliAPIDocs/README.md
## uid 反查
https://github.com/esterTion/BiliBili_crc2mid
https://github.com/cwuom/GetDanmuSender/blob/main/main.py
https://github.com/Aruelius/crc32-crack
## 用户基础信息
https://api.bilibili.com/x/space/acc/info?mid=298220126
https://github.com/ria-klee/bilibili-uid
https://github.com/SocialSisterYi/bilibili-API-collect/blob/master/docs/user/space.md
## 评论
https://www.bilibili.com/read/cv10120255/
https://github.com/SocialSisterYi/bilibili-API-collect/blob/master/docs/comment/readme.md
## json
https://json-schema.apifox.cn
https://bbs.huaweicloud.com/blogs/279515
https://www.cnblogs.com/mashukui/p/16972826.html
## cookie
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Cookies
## 拆包
https://www.cnblogs.com/will-wu/p/13251545.html
https://www.w3schools.com/python/python_tuples.asp
'''''''''''
class BilibiliAPI:
@staticmethod
# 解析视频链接基础信息json,返回json格式数据
def get_bv_json(video_url):
video_id = re.findall(r'BV\w+', video_url)[0]
api_url = f'https://api.bilibili.com/x/web-interface/view?bvid={video_id}'
bv_json = requests.get(api_url).json()
return bv_json
@staticmethod
# 通过json的cid字段,解析视频链接弹幕 xml
def get_danmu_xml(bv_json):
cid = bv_json['data']["cid"]
# api_url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={cid}'
api_url = f'https://comment.bilibili.com/{cid}.xml'
danmu_xml = api_url
return danmu_xml
@staticmethod
# 通过json的aid字段,解析视频链接评论 json
def get_comment_json(bv_json):
aid = bv_json['data']["aid"]
api_url = f'https://api.bilibili.com/x/v2/reply/main?next=1&type=1&oid={aid}'
# print(api_url)
comment_json = requests.get(api_url).json()
return comment_json
@staticmethod
# 通过json的aid字段,解析视频链接评论 json 威力增强版
def get_comment_json_to_webui(bv_json):
aid = bv_json['data']["aid"]
api_url = f'https://api.bilibili.com/x/v2/reply/main?next=1&type=1&oid={aid}'
# 获取当前操作系统类型
if platform.system() == "Windows":
# Windows 平台
driver = webdriver.Chrome()
else:
# 其他平台
driver = webdriver.Chrome(ChromeDriverManager().install())
# 提供登录时间
print("提供B站登录时间为45秒")
time.sleep(45)
# 打开链接
driver.get(api_url)
# 提供查看效果时间
print("提供查看效果时间为15秒")
time.sleep(15)
# 查找 元素
pre_element = driver.find_element(By.TAG_NAME, 'pre')
# 获取元素的文本内容
text_content = pre_element.text
# print(text_content)
# 关闭 WebDriver
driver.quit()
return text_content
@staticmethod
# 遍历用户信息,返回基本参数,为xlsx写入做准备
def get_user_card(mid, cookies):
api_url = f'https://account.bilibili.com/api/member/getCardByMid?mid={mid}'
try:
response = requests.get(api_url, cookies=cookies)
user_card_json = response.json()
except json.JSONDecodeError:
return {"error": "解析JSON失败,请确保网络环境状态良好,调用用户资料API次数过多,此次处理可能存在风控,请稍后几分钟再试"} # 返回适当的错误信息
if 'message' in user_card_json:
message = user_card_json['message']
if '请求被拦截' in message or '请求过于频繁' in message:
return {"warning": "请确保网络环境状态良好,调用用户资料API次数过多,此次处理可能存在风控,请稍后几分钟再试"}
return user_card_json
class CRC32Checker:
''''''''''
# crc32破解
# 出处:https://github.com/Aruelius/crc32-crack
# 作者:Aruelius
# 说明:此处进行了微调,将其封装成类,方便调用。
'''''''''
CRCPOLYNOMIAL = 0xEDB88320
crctable = [0 for x in range(256)]
def __init__(self):
self.create_table()
def create_table(self):
# 创建CRC表,用于快速计算CRC值
for i in range(256):
crcreg = i
for _ in range(8):
if (crcreg & 1) != 0:
crcreg = self.CRCPOLYNOMIAL ^ (crcreg >> 1)
else:
crcreg = crcreg >> 1
self.crctable = crcreg
def crc32(self, string):
# 计算给定字符串的CRC32值
crcstart = 0xFFFFFFFF
for i in range(len(str(string))):
index = (crcstart ^ ord(str(string))) & 255
crcstart = (crcstart >> 8) ^ self.crctable[index]
return crcstart
def crc32_last_index(self, string):
# 计算给定字符串的最后一个字符对应的CRC表索引
crcstart = 0xFFFFFFFF
for i in range(len(str(string))):
index = (crcstart ^ ord(str(string))) & 255
crcstart = (crcstart >> 8) ^ self.crctable[index]
return index
def get_crc_index(self, t):
# 根据CRC表最高字节的值查找对应的索引
for i in range(256):
if self.crctable >> 24 == t:
return i
return -1
def deep_check(self, i, index):
# 深度检查,根据索引和之前的CRC32值验证假设
string = ""
tc = 0x00
hashcode = self.crc32(i)
tc = hashcode & 0xff ^ index[2]
if not (tc = 48):
return [0]
string += str(tc - 48)
hashcode = self.crctable[index[2]] ^ (hashcode >> 8)
tc = hashcode & 0xff ^ index[1]
if not (tc = 48):
return [0]
string += str(tc - 48)
hashcode = self.crctable[index[1]] ^ (hashcode >> 8)
tc = hashcode & 0xff ^ index[0]
if not (tc = 48):
return [0]
string += str(tc - 48)
hashcode = self.crctable[index[0]] ^ (hashcode >> 8)
return [1, string]
def main(self, string):
# 主要函数,根据给定的字符串计算CRC32并进行验证
index = [0 for x in range(4)]
i = 0
ht = int(f"0x{string}", 16) ^ 0xffffffff
for i in range(3, -1, -1):
index[3-i] = self.get_crc_index(ht >> (i*8))
snum = self.crctable[index[3-i]]
ht ^= snum >> ((3-i)*8)
for i in range(100000000):
lastindex = self.crc32_last_index(i)
if lastindex == index[3]:
deepCheckData = self.deep_check(i, index)
if deepCheckData[0]:
break
if i == 100000000:
return -1
return f"{i}{deepCheckData[1]}"
class Tools:
@staticmethod
# 获取保存路径及格式
def get_save():
return os.path.join(os.path.join(os.path.expanduser("~"), "Desktop"),
"B站视频基础信息调研_{}.xlsx".format(datetime.now().strftime('%Y-%m-%d')))
@staticmethod
# 格式化时间戳
def format_timestamp(timestamp):
dt_object = datetime.fromtimestamp(timestamp)
formatted_time = dt_object.strftime("%Y-%m-%d %H:%M:%S")
return formatted_time
@staticmethod
# 情绪值计算
def calculate_sentiment_score(text):
s = SnowNLP(text)
sentiment_score = s.sentiments
return sentiment_score
@staticmethod
# 生成词云
def get_word_cloud(sheet_name: str, workbook: Workbook):
# 获取之前写入的词频统计sheet
sheet = workbook[sheet_name]
# 读取词频数据
words = []
frequencies = []
for row in sheet.iter_rows(min_row=2, values_only=True):
words.append(row[0])
frequencies.append(row[1])
# 获取当前操作系统类型
system = platform.system()
# 根据操作系统类型设置字体文件路径
if system == 'Darwin': # macOS
font_path = '/System/Library/Fonts/STHeiti Light.ttc' # 替换为适合你的字体文件路径
elif system == 'Windows':
font_path = 'C:/Windows/Fonts/simhei.ttf' # 替换为适合你的字体文件路径
else: # 其他操作系统,如 Linux
font_path = 'simhei.ttf' # 替换为适合你的字体文件路径
# 创建词云对象,指定字体文件路径
wordcloud = WordCloud(background_color='white', max_words=100, font_path=font_path)
# 构建词频字典
word_frequency = dict(zip(words, frequencies))
# 生成词云
print(sheet_name, "词云生成中...")
wordcloud.generate_from_frequencies(word_frequency)
# 显示词云图片
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
@staticmethod
# 生成横向统计图
def get_word_chart(sheet_name: str, workbook):
# 获取之前写入的词频统计sheet
sheet = workbook[sheet_name]
# 读取词频数据
words = []
frequencies = []
for row in sheet.iter_rows(min_row=2, values_only=True):
words.append(row[0])
frequencies.append(row[1])
# 获取操作系统类型
system = platform.system()
# 根据操作系统类型设置字体文件路径
if system == 'Darwin': # macOS
font_path = '/System/Library/Fonts/STHeiti Light.ttc'
elif system == 'Windows':
font_path = 'C:/Windows/Fonts/simhei.ttf'
else: # 其他操作系统,如 Linux
font_path = 'simhei.ttf'
# 创建字体属性对象
custom_font = fm.FontProperties(fname=font_path)
# 绘制横向统计图并设置字体
fig, ax = plt.subplots()
ax.barh(words, frequencies)
ax.set_xlabel("频次", fontproperties=custom_font)
ax.set_ylabel("词语", fontproperties=custom_font)
# 自动调整y轴标签旋转角度,以避免重叠
plt.yticks(fontproperties=custom_font)
# 显示图像
print(sheet_name, "横向统计图生成中...")
plt.show()
@staticmethod
def get_user_info_by_card(user_card_json):
info = {
'name': "N/A",'birthday': "N/A",'regtime': "N/A",
'fans': "N/A",'friend': "N/A"
}
try:
info['name'] = user_card_json['card']['name']
info['birthday'] = user_card_json['card']['birthday']
info['regtime'] = Tools.format_timestamp(int(user_card_json['card']['regtime']))
info['fans'] = user_card_json['card']['fans']
info['friend'] = user_card_json['card']['friend']
except KeyError:
pass
return tuple(info.values())
class BilibiliExcel:
@staticmethod
# 写入视频基础信息
def write_base_info(workbook, bv_json):
sheet = workbook.create_sheet(title="视频信息")
headers = ["视频标题", "作者", "发布时间", "播放量", "收藏量", "分享量", "累计弹幕",
"评论数", "视频简介", "视频类别", "视频链接", "封面链接"]
sheet.append(headers)
data = [bv_json["data"]["title"],
bv_json["data"]["owner"]["name"],
Tools.format_timestamp(bv_json["data"]["pubdate"]),
bv_json["data"]["stat"]["view"],
bv_json["data"]["stat"]["favorite"],
bv_json["data"]["stat"]["share"],
bv_json["data"]["stat"]["danmaku"],
bv_json["data"]["stat"]["reply"],
bv_json["data"]["desc"],
bv_json["data"]["tname"],
video_url,
bv_json["data"]["pic"]]
sheet.append(data)
@staticmethod
# 写入弹幕基本信息
def write_danmu_info(workbook, danmu_xml):
sheet = workbook.create_sheet(title="弹幕信息")
headers = [
"弹幕内容", "情绪值","词性分析", "发表时间",
"用户ID"
]
sheet.append(headers)
xml_text = requests.get(danmu_xml).content.decode('utf-8')
# 使用BeautifulSoup解析xml
soup = BeautifulSoup(xml_text, "lxml-xml")
danmu_list = soup.find_all("d")
sentiment_scores = [] # 存储情绪值
thu = thulac.thulac() # 创建thulac对象,用于词性分析
for danmu in danmu_list[:100]: # 控制弹幕获取数在100条范围。
danmu_content = danmu.text
timestamp = Tools.format_timestamp(int(danmu.get('p').split(",")[4]))
mid = cRc32checker.main(danmu.get('p').split(",")[6]) # 通过uid反查用户ID
# 计算情绪值
sentiment_score = Tools.calculate_sentiment_score(danmu_content)
sentiment_scores.append(sentiment_score) # 将情绪值添加到列表中
# 进行词性分析
thu_result = thu.cut(danmu_content, text=True)
data = [
danmu_content,
sentiment_score,
thu_result,
timestamp,
mid
]
sheet.append(data)
# 计算平均值
average_sentiment_score = sum(sentiment_scores) / len(sentiment_scores)
print("弹幕情绪值平均值:", average_sentiment_score)
# 计算中位数
median_sentiment_score = statistics.median(sentiment_scores)
print("弹幕情绪值中位数:", median_sentiment_score)
@staticmethod
# 写入弹幕基本信息 威力增强版
def write_danmu_info_by_cookies(workbook, danmu_xml):
cookies = input("用你的浏览器,打开开发者工具,找到Cookie,并输入:")
# # 将Cookie字符串转换为字典形式
# cookie_list = cookies.split("; ")
# cookies_dict = {}
# for cookie in cookie_list:
# try:
# key, value = cookie.strip().split("=", 1)
# cookies_dict[key] = value
# except ValueError:
# print("本次cookie解析存在问题,请检查字符串与格式")
# return BilibiliExcel.write_danmu_info(workbook, danmu_xml)
# 将Cookie字符串转换为字典形式
cookie_list = cookies.split("; ")
cookies_dict = {}
while not cookies_dict:
try:
for cookie in cookie_list:
key, value = cookie.strip().split("=", 1)
cookies_dict[key] = value
except ValueError:
print("本次cookie解析存在问题,请检查字符串与格式")
cookies = input("请重新输入Cookie:")
cookie_list = cookies.split("; ")
sheet = workbook.create_sheet(title="弹幕信息")
headers = [
"弹幕内容", "情绪值","词性分析", "发表时间",
"用户ID","用户名","生日","注册时间","粉丝数","关注数"
]
sheet.append(headers)
xml_text = requests.get(danmu_xml).content.decode('utf-8')
# 使用BeautifulSoup解析xml
soup = BeautifulSoup(xml_text, "lxml-xml")
danmu_list = soup.find_all("d")
sentiment_scores = [] # 存储情绪值
thu = thulac.thulac() # 创建thulac对象,用于词性分析
for danmu in danmu_list[:100]:
danmu_content = danmu.text
timestamp = Tools.format_timestamp(int(danmu.get('p').split(",")[4]))
mid = cRc32checker.main(danmu.get('p').split(",")[6]) # 通过uid反查用户ID
user_card_json = BilibiliAPI.get_user_card(mid, cookies=cookies_dict)
name,birthday,regtime,fans,friend = Tools.get_user_info_by_card(user_card_json)
# 计算情绪值
sentiment_score = Tools.calculate_sentiment_score(danmu_content)
sentiment_scores.append(sentiment_score) # 将情绪值添加到列表中
# 进行词性分析
thu_result = thu.cut(danmu_content, text=True)
data = [
danmu_content,
sentiment_score,
thu_result,
timestamp,
mid,
name,
birthday,
regtime,
fans,
friend
]
sheet.append(data)
# 计算平均值
average_sentiment_score = sum(sentiment_scores) / len(sentiment_scores)
print("弹幕情绪值平均值:", average_sentiment_score)
# 计算中位数
median_sentiment_score = statistics.median(sentiment_scores)
print("弹幕情绪值中位数:", median_sentiment_score)
# 弹幕词频统计 jieba
@staticmethod
def jieba_danmu_frequency_statistics(workbook):
sheet = workbook.create_sheet(title="弹幕词频统计")
headers = ["词语", "频次"]
sheet.append(headers)
# 获取之前写入的弹幕信息sheet
danmu_sheet = workbook["弹幕信息"]
word_frequency = {} # 存储词频
# 请求停用词库
stopwords_file = 'https://ghproxy.com/https://raw.githubusercontent.com/hoochanlon/scripts/main/d-txt/cn_stopwords.txt'
response = requests.get(stopwords_file)
stopwords = response.content.decode('utf-8').split('\n')
for row in danmu_sheet.iter_rows(min_row=2, values_only=True):
danmu_content = row[0]
# 使用jieba进行分词,并忽略空格
words = [word for word in jieba.lcut(danmu_content) if word.strip() != '' and len(word) > 1]
for word in words:
if word not in stopwords: # 判断词语是否为停用词
if word in word_frequency:
word_frequency[word] += 1
else:
word_frequency[word] = 1
# 根据词频进行排序并获取前30个词语
sorted_word_frequency = sorted(word_frequency.items(), key=lambda x: x[1], reverse=True)[:30]
for word, frequency in sorted_word_frequency:
data = [word, frequency]
sheet.append(data)
# 写入评论基本信息
@staticmethod
def write_comments_info(workbook, bv_reply_json):
sheet = workbook.create_sheet(title="评论信息")
headers = ["热门评论", "点赞数", "情绪值","话题回复条目","会员ID","会员名","评论时间"]
sheet.append(headers)
# print(bv_reply_json)
sentiment_scores = [] # 存储情绪值
# 遍历每个评论
for comment in bv_reply_json['data']['replies']:
content = comment['content']['message']
sentiment_score = Tools.calculate_sentiment_score(content)
sentiment_scores.append(sentiment_score) # 将情绪值添加到列表中
like_count = comment['like']
member_id = comment['member']['mid']
member_name = comment['member']['uname']
comment_time = Tools.format_timestamp(int(comment['ctime']))
# 使用 dict.get() 方法获取字段值,提供默认值,避免 keyError。
reply_control = comment.get('reply_control', {})
sub_reply_entry_text = reply_control.get('sub_reply_entry_text', 'N/A')
# 判断点赞数是否大于 5,经测试发现默认上限20条
# if like_count > 5:
data = [
content,
like_count,
sentiment_score,
sub_reply_entry_text,
member_id,
member_name,
comment_time
]
sheet.append(data)
# 计算平均值
average_sentiment_score = sum(sentiment_scores) / len(sentiment_scores)
print("评论情绪值平均值:", average_sentiment_score)
# 计算中位数
median_sentiment_score = statistics.median(sentiment_scores)
print("评论情绪值中位数:", median_sentiment_score)
# 写入评论基本信息 威力加强版
@staticmethod
def write_comments_info_plus(workbook):
sentiment_scores = [] # 存储情绪值
try:
# json.load 则是文件对象;要解决这个问题,可以使用 json.loads 方法,它可以直接将字符串转换为 JSON 对象,而不需要文件对象
bv_reply_json = json.loads(BilibiliAPI.get_comment_json_to_webui(bv_json))
except json.JSONDecodeError as e:
print("解析评论JSON失败:", str(e))
return BilibiliExcel.write_comments_info(workbook, bv_reply_json) # 终止当前函数
sheet = workbook.create_sheet(title="评论信息")
headers = ["热门评论", "点赞数", "情绪值","话题回复条目","会员ID","会员名","评论时间","IP归属"]
sheet.append(headers)
# 遍历每个评论
for comment in bv_reply_json['data']['replies']:
content = comment['content']['message']
sentiment_score = Tools.calculate_sentiment_score(content)
sentiment_scores.append(sentiment_score) # 将情绪值添加到列表中
like_count = comment['like']
member_id = comment['member']['mid']
member_name = comment['member']['uname']
comment_time = Tools.format_timestamp(int(comment['ctime']))
# 使用 dict.get() 方法获取字段值,提供默认值,避免 keyError。
reply_control = comment.get('reply_control', {})
sub_reply_entry_text = reply_control.get('sub_reply_entry_text', 'N/A')
location = reply_control.get('location', 'N/A')
# 将属地信息处理为不带前缀的形式
location = location.replace('IP属地:', '')
data = [
content,
like_count,
sentiment_score,
sub_reply_entry_text,
member_id,
member_name,
comment_time,
location
]
sheet.append(data)
# 计算平均值
average_sentiment_score = sum(sentiment_scores) / len(sentiment_scores)
print("评论情绪值平均值:", average_sentiment_score)
# 计算中位数
median_sentiment_score = statistics.median(sentiment_scores)
print("评论情绪值中位数:", median_sentiment_score)
# 评论词频统计 jieba
@staticmethod
def jieba_comments_frequency_statistics(workbook):
sheet = workbook.create_sheet(title="评论词频统计")
headers = ["词语", "频次"]
sheet.append(headers)
# 获取之前写入的弹幕信息sheet
comments_sheet = workbook["评论信息"]
word_frequency = {} # 存储词频
# 请求停用词库
stopwords_file = 'https://ghproxy.com/https://raw.githubusercontent.com/hoochanlon/scripts/main/d-txt/cn_stopwords.txt'
response = requests.get(stopwords_file)
stopwords = response.content.decode('utf-8').split('\n')
for row in comments_sheet.iter_rows(min_row=2, values_only=True):
comments_content = row[0]
# 使用jieba进行分词,并忽略空格
words = [word for word in jieba.lcut(comments_content) if word.strip() != '' and len(word) > 1]
for word in words:
if word not in stopwords: # 判断词语是否为停用词
if word in word_frequency:
word_frequency[word] += 1
else:
word_frequency[word] = 1
# 根据词频进行排序并获取前30个词语
sorted_word_frequency = sorted(word_frequency.items(), key=lambda x: x[1], reverse=True)[:30]
for word, frequency in sorted_word_frequency:
data = [word, frequency]
sheet.append(data)
@staticmethod
def save_workbook(workbook):
workbook.save(Tools.get_save())
class Print_info:
# 打印基础信息
@staticmethod
def base_message():
if 'Windows' == platform.system():
os.system('cls')
else:
os.system('clear')
text = '''
************************************
B站视频基础信息调研 v2023.6.26
作者:Github.com/hoochanlon
项目地址:https://github.com/hoochanlon/scripts
程序功能明细:
1. 视频标题、作者、发布时间、播放量、收藏量、分享量、累计弹幕、评论数、视频简介、视频类别、视频链接、封面链接。
2. 100条弹幕、情绪值、词性分析、发表时间、用户ID
3. 20篇热门评论、点赞数、情绪值、话题回复条目、会员ID、会员名、评论时间。
4. 威力增强:弹幕:用户名、生日、注册时间、粉丝数、关注数(cookie);评论:显示评论用户的IP归属地(webbui)。
5. 文本情绪值中位数、词频统计、词云、柱形统计图。
使用事项说明:
1. 确保python类库,安装完善:
pip3 install -r https://raw.githubusercontent.com/hoochanlon/scripts/main/d-txt/requirements.txt
2. cookie 值可输入 key=value 的形式如 “a=a;” 跳过,并执行之后的动作。
3. 在弹出浏览器窗口时,不要关闭,并登录B站,用于程序在登录状态才获取的API部分属性信息(如:IP归属地等)。
4. 请确保网络环境状态良好,否则可能会出现网络请求失败的情况;分析报表生成过程中,会有一定的等待时间,请耐心等待片刻。
免责声明:本程序仅供社科研究与编程学习交流使用,不得用于任何商业及非法用途。
************************************
'''
print(text.center(50, ' '))
if __name__ == '__main__':
Print_info.base_message()
# 获取输入视频链接
# video_url = re.findall(r'.*BV\w+', input("请输入Bilibili视频链接:"))[0]
while True:
video_url = input("请粘贴Bilibili视频链接:")
if re.match(r'.*BV\w+', video_url):
break
else:
print("链接格式不正确,请重新输入。")
# 获取视频基础信息json
bv_json = BilibiliAPI.get_bv_json(video_url)
# 获取视频弹幕信息xml
danmu_xml = BilibiliAPI.get_danmu_xml(bv_json)
# 获取视频评论信息json
bv_reply_json = BilibiliAPI.get_comment_json(bv_json)
# 创建一个新的Workbook对象
workbook = Workbook()
# 删除默认创建的空白Sheet
workbook.remove(workbook.active)
# 创建用户ID CRC32校验器对象
cRc32checker = CRC32Checker()
# 将视频基础信息写入Excel
BilibiliExcel.write_base_info(workbook, bv_json)
# 将弹幕信息写入Excel
# BilibiliExcel.write_danmu_info(workbook, danmu_xml)
# 将弹幕信息写入Excel 威力增强版
BilibiliExcel.write_danmu_info_by_cookies(workbook, danmu_xml)
# 弹幕词频统计
BilibiliExcel.jieba_danmu_frequency_statistics(workbook)
# 将评论信息写入Excel
# BilibiliExcel.write_comments_info(workbook, bv_reply_json)
# 将评论信息写入Excel 威力加强版
BilibiliExcel.write_comments_info_plus(workbook)
# 评论词频统计
BilibiliExcel.jieba_comments_frequency_statistics(workbook)
# 保存Excel文件
BilibiliExcel.save_workbook(workbook)
# 生成词云与柱形统计图
Tools.get_word_cloud("弹幕词频统计", workbook)
Tools.get_word_chart("评论词频统计", workbook)
参考资料
常规
uid 反查
API
json
cookie:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Cookies
拆包
