| 本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删! |
淘宝关键词搜索及X5滑块
环境
根据关键词获取品牌列表
先根据搜索关键词获取到所有的品牌id:也就是ppath参数,目的是这样可以筛选更精准的数据,因为默认只显示100页数据
def get_brand(self):
"""
根据关键词获取品牌列表
"""
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Referer": "https://s.taobao.com/search?q=^%^E7^%^AC^%^94^%^E8^%^AE^%^B0^%^E6^%^9C^%^AC^%^E7^%^94^%^B5^%^E8^%^84^%^91&imgfile=&js=1&stats_click=search_radio_tmall^%^3A1&initiative_id=staobaoz_20230127&tab=mall&ie=utf8&bcoffset=0&p4ppushleft=^%^2C44&style=grid&s=0",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
"sec-ch-ua": "^\\^Not_A",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
}
cookies = {
"cookie2": "1c1f03c4df47307258a30c65ce1db555",
}
url = "https://s.taobao.com/search"
params = {
"q": self.word,
"imgfile": "",
"js": "1",
"stats_click": "search_radio_tmall^%^3A1",
"initiative_id": "staobaoz_20230127",
"tab": "mall",
"ie": "utf8",
"style": "grid"
}
# response = requests.get(url, headers=headers, params=params)
response = self._parse_url(url=url, headers=headers, params=params)
if not response:
yield None
# print(response.text)
res = re.findall(r'g_page_config = (.*?)};', response.text, re.M | re.S)
if not res:
yield None
datas = jsonpath.jsonpath(json.loads(res[0] + "}"), "$..sub")
if not datas:
yield None
for data in datas[0]:
yield data
根据关键词、品牌、销量搜索商品列表
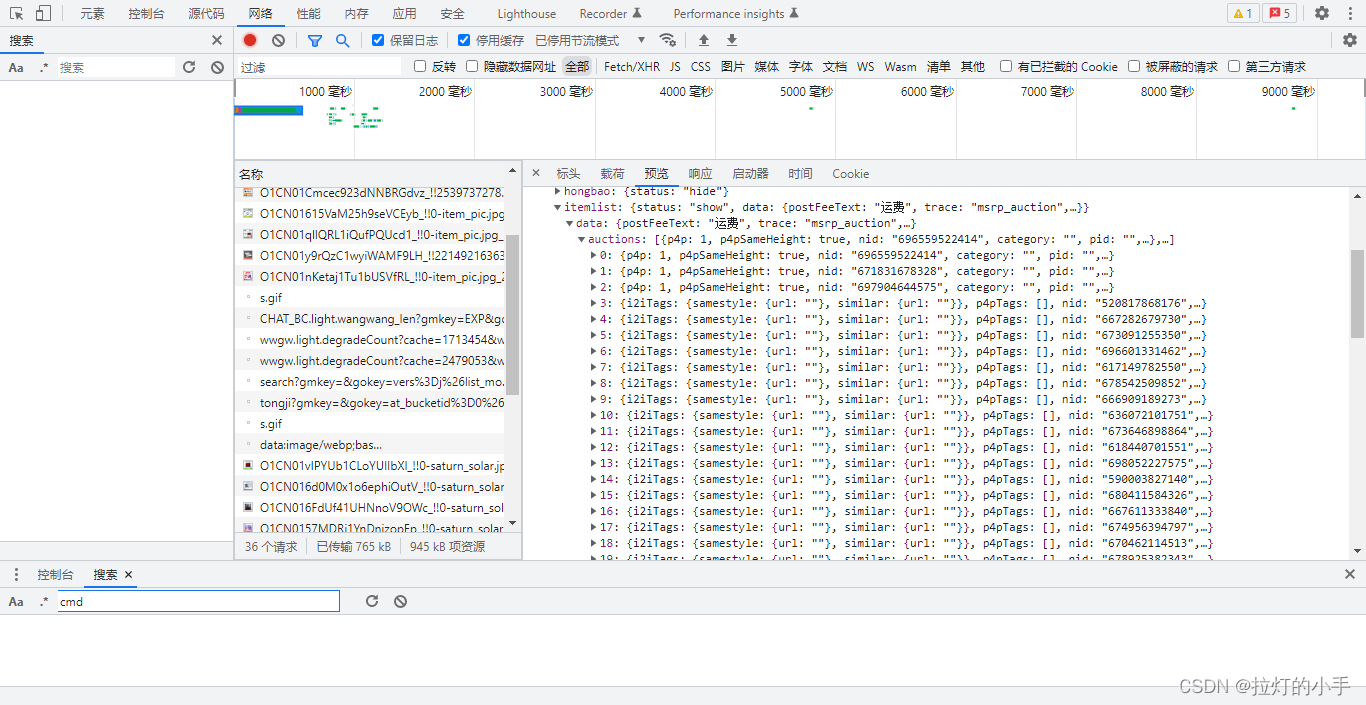
具体的参数多抓几个包对比一下,很容易就分析出来了
def get_products(self, ppath, page):
"""
获取商品列表 根据销量排序
ppath:品牌代码
page:翻页
"""
headers = {
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Referer": "https://s.taobao.com/search?q=^%^E7^%^AC^%^94^%^E8^%^AE^%^B0^%^E6^%^9C^%^AC^%^E7^%^94^%^B5^%^E8^%^84^%^91&imgfile=&js=1&style=grid&stats_click=search_radio_tmall^%^3A1&initiative_id=staobaoz_20230127&tab=mall&ie=utf8&bcoffset=0&p4ppushleft=^%^2C44&cps=yes&ppath=20000^%^3A11119&sort=sale-desc&s=44",
"Sec-Fetch-Dest": "script",
"Sec-Fetch-Mode": "no-cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
"sec-ch-ua": "^\\^Not_A",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
}
url = "https://s.taobao.com/search"
params = {
"data-key": "s",
"data-value": page,
"ajax": "true",
"_ksTS": "1674837683322_2012",
"callback": "jsonp2013",
"q": self.word,
"imgfile": "",
"js": "1",
"style": "grid",
"stats_click": "search_radio_tmall^%^3A1",
"initiative_id": "staobaoz_20230127",
"tab": "mall",
"ie": "utf8",
"bcoffset": "0",
"p4ppushleft": "^%^2C44",
"cps": "yes",
"ppath": ppath,
"sort": "sale-desc",
"s": ''
}
# 第一页的时候请求参数不一样
if page == 1:
params['data-value'] = '0,1'
params['data-key'] = 's,ps'
params['s'] = (int(page) - 1) * 44
else:
params['data-value'] = int(page) * 44
params['s'] = (int(page)-1) * 44
response = requests.get(url, headers=headers, params=params)
return response.text
滑块处理
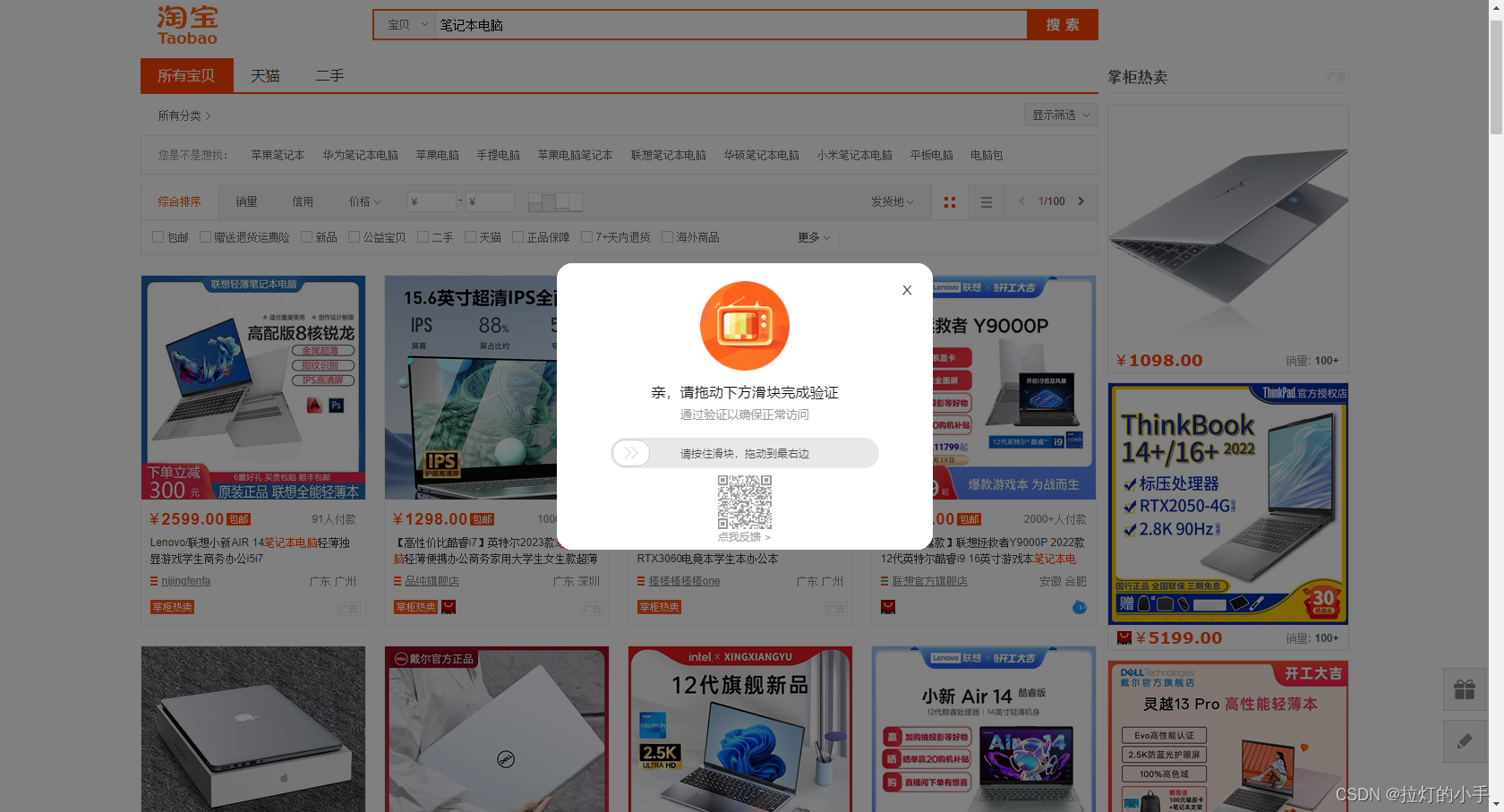
触发滑块后,搜索并定位appkey,抓到punish.js
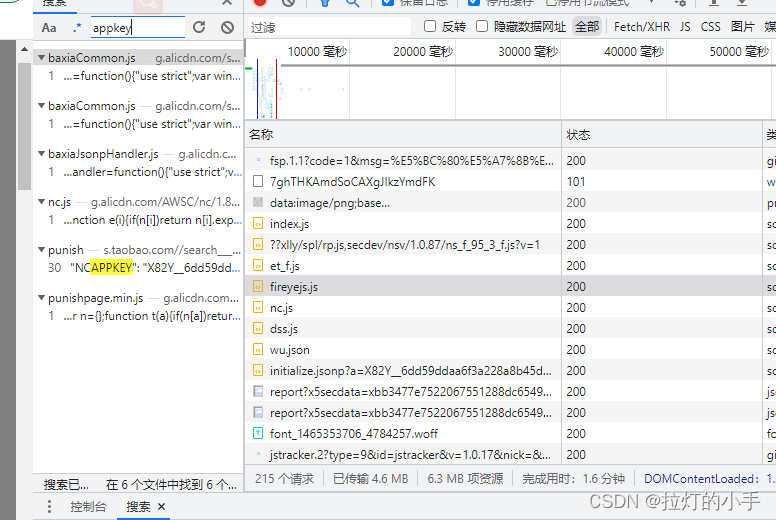
提取验证所需参数:
''appkey': 'X82Y__4efeef942d19c56bafab18ba3da969f4'
'token': '1c797559e58912c4ee46af4bd6371aec',
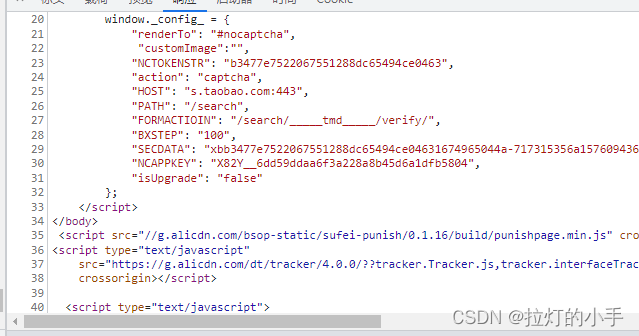
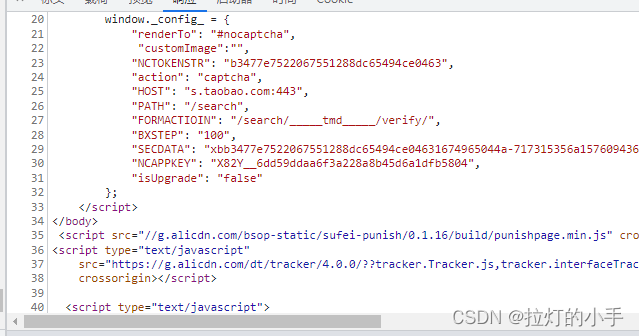
生成x5sec:"7b2277616762726964676561643b32223a223037393766353232633166646661326337346262333664616130356462383031434e434337497747454e7a746b2b7a356f493771495367454d4b447a344a4146227d"

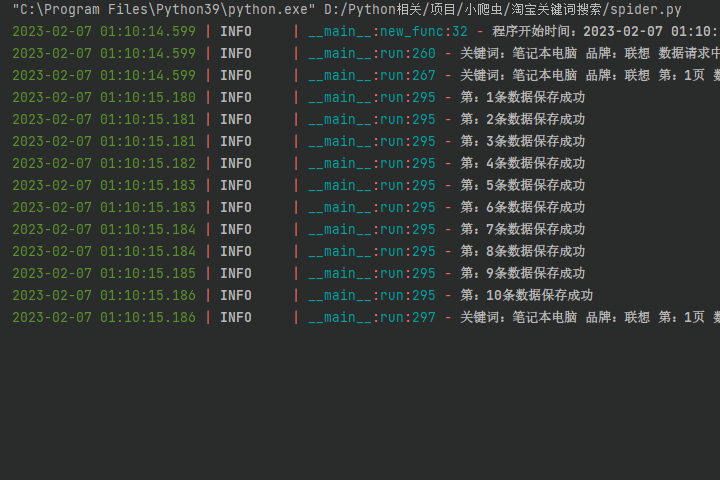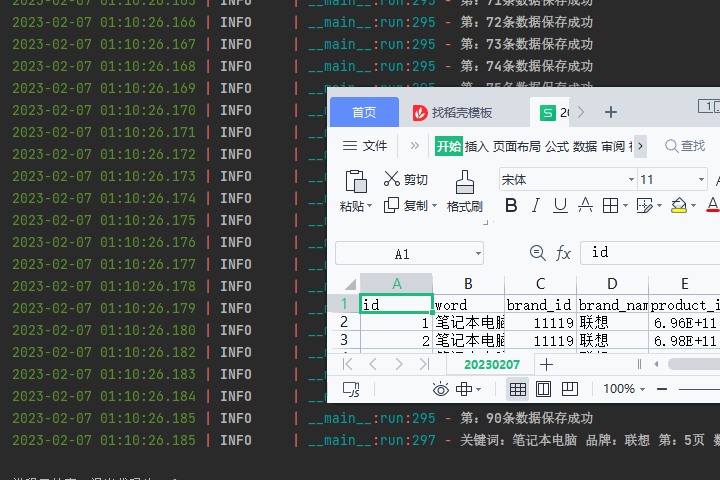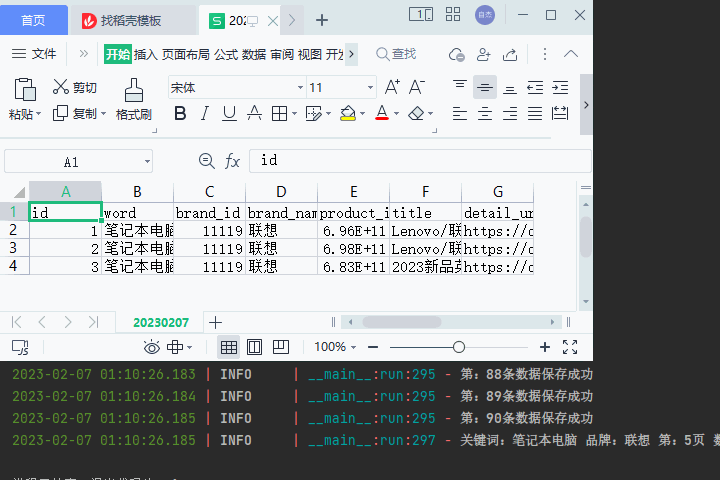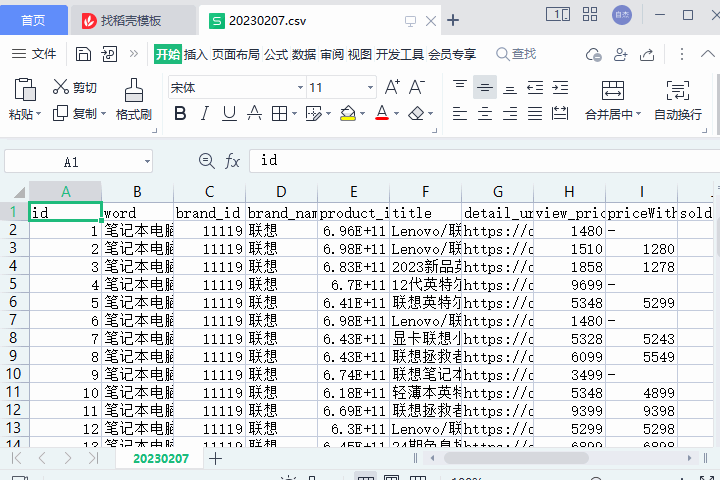
效果
| 本文仅供学习交流使用,如侵立删! |
