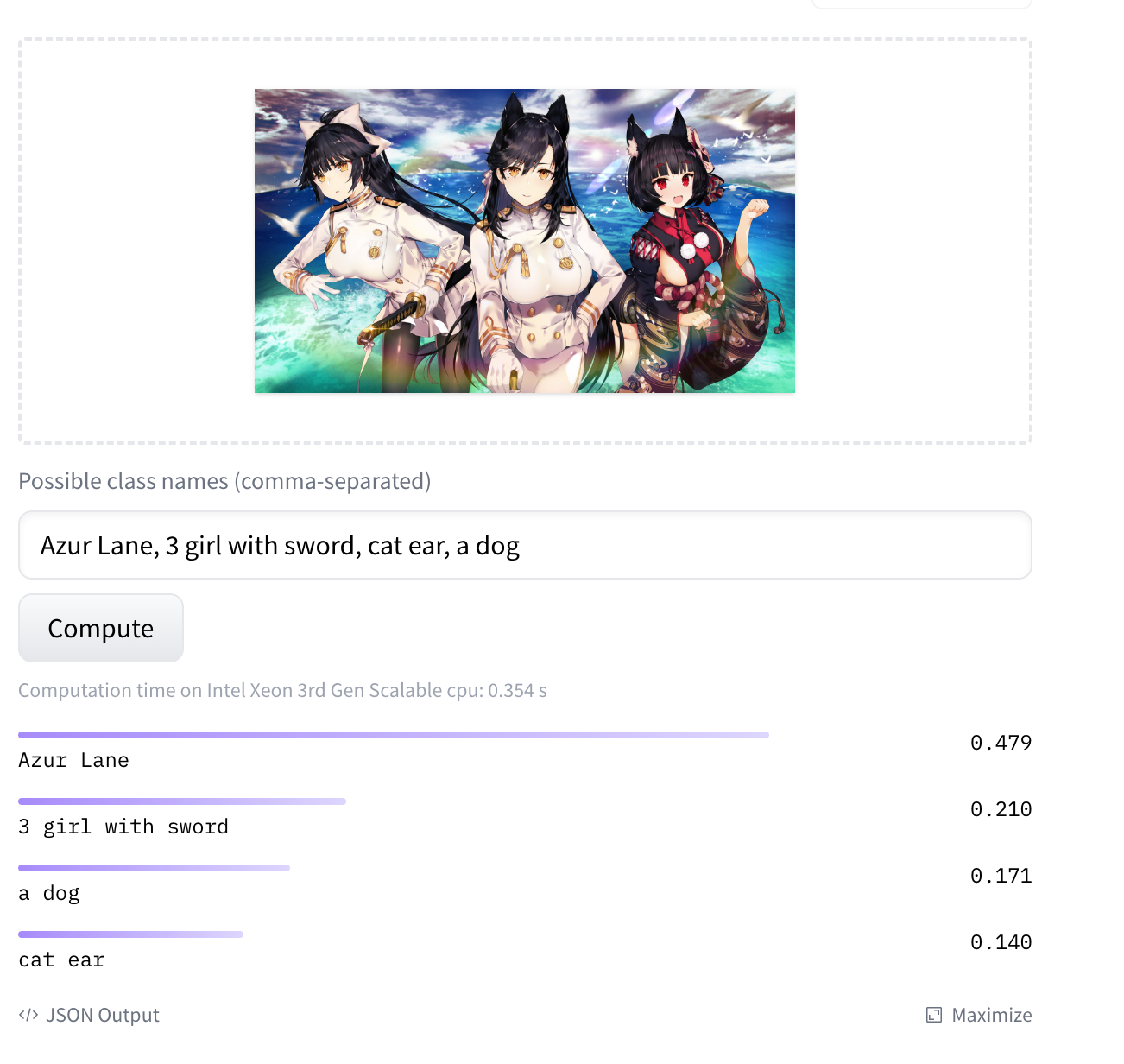
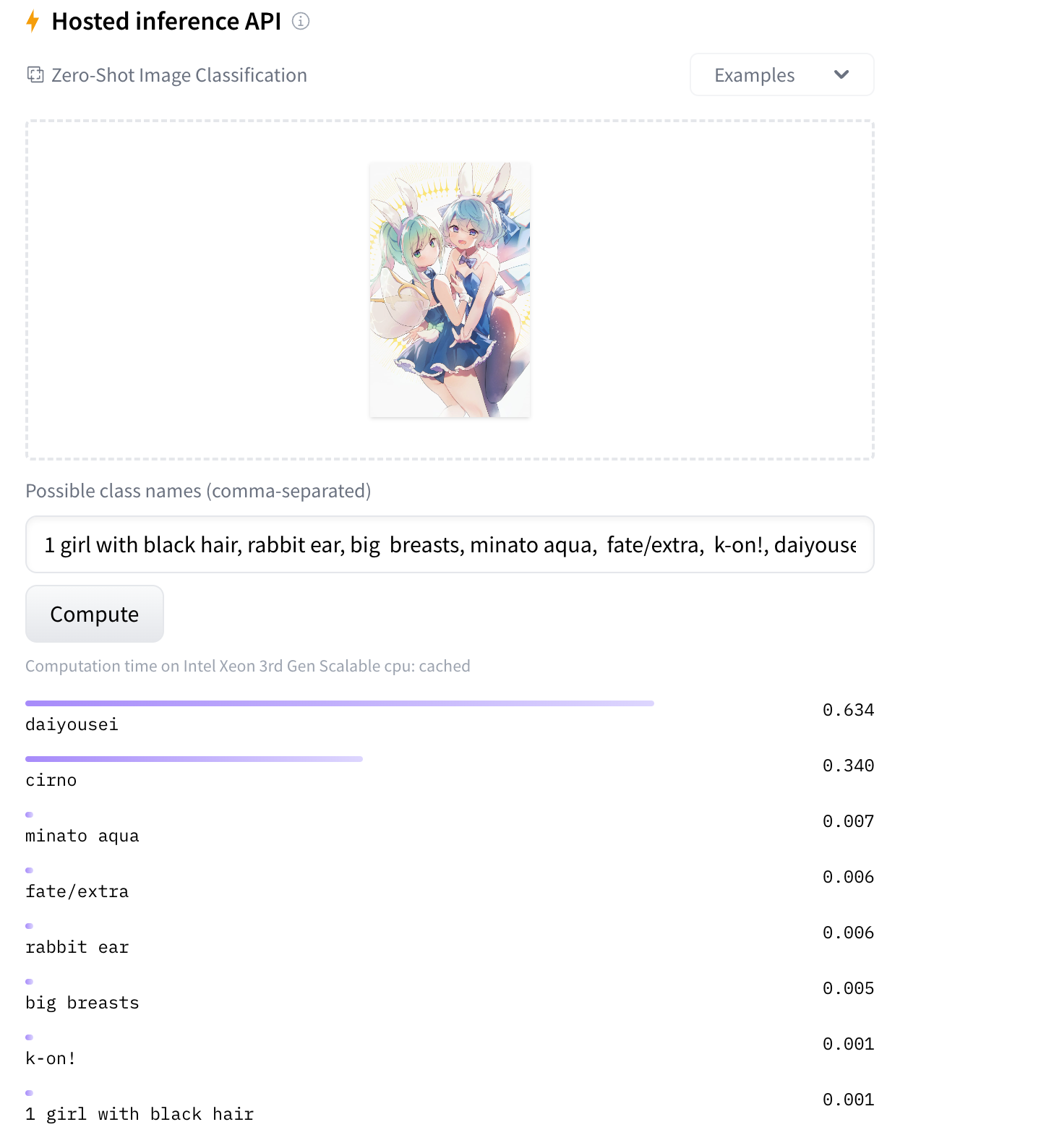
介绍
Huggingface 在线体验: https://huggingface.co/OysterQAQ/DanbooruCLIP
github 主仓库地址( pt 模型文件可以在 release 下载): https://github.com/OysterQAQ/ACG2vec
使用 danburoo2021 数据集对 clip ( ViT-L/14 )模型进行微调。
0-3 epoch 学习率为 4e-6 ,权重衰减为 1e-3
4-8 epoch 学习率为 1e-6 ,权重衰减为 1e-3
标签预处理过程:
for i in range(length):
# 加载并且缩放图片
if not is_image(data_from_db.path):
continue
try:
img = self.preprocess(
Image.open(data_from_db.path.replace("./", "/mnt/lvm/danbooru2021/danbooru2021/")))
except Exception as e:
#print(e)
continue
# 处理标签
tags = json.loads(data_from_db.tags)
# 优先选择人物和作品标签
category_group = {}
for tag in tags:
category_group.setdefault(tag["category"], []).append(tag)
# category_group=groupby(tags, key=lambda x: (x["category"]))
character_list = category_group[4] if 4 in category_group else []
# 作品需要过滤以 bad 开头的
work_list = list(filter(
lambda e:
e["name"] != "original"
, category_group[3])) if 3 in category_group else []
# work_list= category_group[5] if 5 in category_group else []
general_list = category_group[0] if 0 in category_group else []
caption = ""
caption_2 = None
for character in character_list:
if len(work_list) != 0:
# 去除括号内作品内容
character["name"] = re.sub(u"\\(.*?\\)", "", character["name"])
caption += character["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
caption += " "
if len(work_list) != 0:
caption += "from "
for work in work_list:
caption += work["name"].replace("_", " ")
caption += " "
# 普通标签
if len(general_list) != 0:
caption += "with "
if len(general_list) > 20:
general_list_1 = general_list[:int(len(general_list) / 2)]
general_list_2 = general_list[int(len(general_list) / 2):]
caption_2 = caption
for general in general_list_1:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption_2 += general["name"].replace("_", " ")
caption_2 += ","
caption_2 = caption_2[:-1]
for general in general_list_2:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
else:
for general in general_list:
# 如果标签数据目大于 20 则拆分成两个 caption
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
# 标签汇总成语句
# tokenize 语句
# 返回
# 过长截断 不行的话用 huggingface 的
text_1 = clip.tokenize(texts=caption, truncate=True)
text_2= None
if caption_2 is not None:
text_2 = clip.tokenize(texts=caption_2, truncate=True)
# 处理逻辑
# print(img)
yield img, text_1[0]
if text_2 is not None:
yield img, text_2[0]
预览