User-agent: *
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
设置 robots.txt 的时间已经超过了 30 个小时。都不遵守 robots 的话,只能从 nginx 配置了。
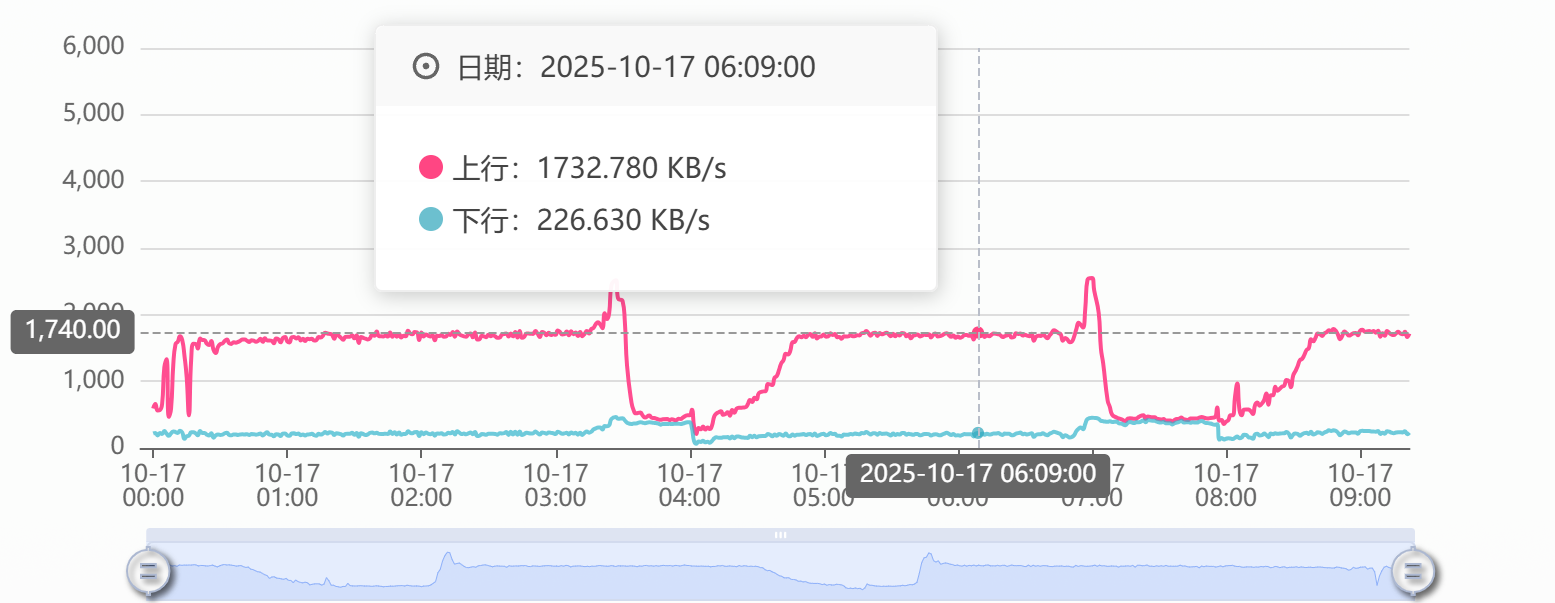
10M 的宽带直接被爬虫跑满了
20.171.207.130 - - [17/Oct/2025:09:16:41 +0800] "GET /?s=search/index/cid/323/bid/24/scid/85C4/peid/27/ov/new-asc.html HTTP/1.1" 200 38211 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)"
117.50.153.198 - - [17/Oct/2025:09:16:42 +0800] "GET /?s=search/index/cid/316/scid/85C4/poid/33/bid/8/ov/new-asc/peid/7.html HTTP/1.1" 200 38340 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0"
57.141.0.25 - - [17/Oct/2025:09:16:42 +0800] "GET /?s=search/index/poid/33/scid/9EBB198E982B/cid/444/peid/17/bid/12.html HTTP/1.1" 200 637932 "-" "meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)"
57.141.0.12 - - [17/Oct/2025:09:16:42 +0800] "GET /?s=search/index/poid/33/scid/9EBB198E982B/cid/631/peid/29/bid/28/ov/price-asc.html HTTP/1.1" 200 637644 "-" "meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)"
57.141.0.74 - - [17/Oct/2025:09:16:42 +0800] "GET /?s=search/index/poid/33/scid/C4/cid/608/peid/7/ov/new-asc.html HTTP/1.1" 200 635769 "-" "meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)"
57.141.0.63 - - [17/Oct/2025:09:16:42 +0800] "GET /?s=search/index/poid/33/peid/29/bid/24/scid/C4/cid/570/ov/access-desc.html HTTP/1.1" 200 618851 "-" "meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)"
117.50.153.198 - - [17/Oct/2025:09:16:43 +0800] "GET /?s=search/index/cid/321/bid/29/scid/85C4/ov/new-desc/peid/7/poid/33.html HTTP/1.1" 200 38368 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0"
57.141.0.34 - - [17/Oct/2025:09:16:43 +0800] "GET /?s=search/index/poid/33/peid/18/ov/new-desc/scid/9EBB198E982B/bid/8/cid/367.html HTTP/1.1" 200 467003 "-" "meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)"
