不过这周,OpenAI 终于发布了 ChatGPT API 了。
我也是第一时间基于真正的 ChatGPT API 撸了个真正的 ChatGPT Teams Bot:
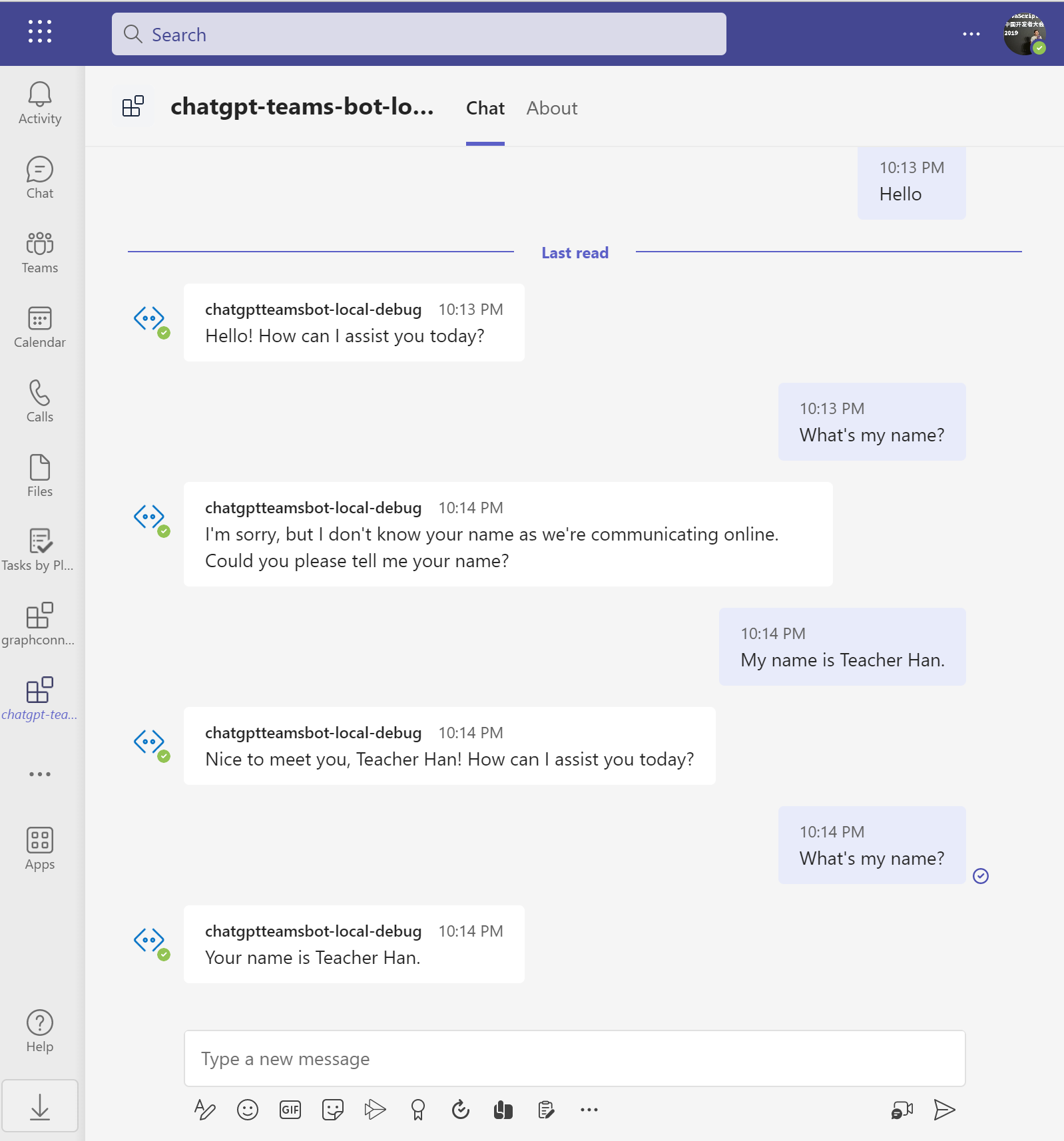
与 ChatGPT 一样,他们都是基于最新的 gpt-3.5-turbo model ,专门为聊天优化,能理解对话的上下文。
我这个机器人的代码完全开源,而且 clone 下来之后,可以很方便地根据 README 的步骤直接 F5 玩起来。大家有兴趣的,可以围观下:
https://github.com/formulahendry/chatgpt-teams-bot
不过呢,目前的 ChatGPT Teams Bot 是个很初步的版本,有一些 limitations ,比如官方提供的 openai Node.js SDK 需要开发者自己拼接聊天记录。我就选择了第三方的 chatgpt Node.js SDK ,不过他也只是把聊天记录存在内存中。
如此一来,我们会发现目前版本的一些问题:
[ol]
chat history 是存储在内存中的,如果 Bot 重启了,chat history 会丢失,怎么解决?
如果为了支持高并发,Bot 是部署在多个不同的 server 上的,如何保证 chat history 的一致性?
gpt-3.5-turbo model 有 4000 token 的限制,而且 input 也是算进去的,如何处理 chat history 超过限制的问题?
如果 Bot 会被添加到多个 Teams 的聊天对话中,如何保证聊天 context 不相互干扰?
[/ol]
