/t/1006548
上次分享了我的日志写作流程,虽然只有一个老哥看到了,但是提出了一些很好的建议,我也在这几天做了一些调整,现在的流程更加完善了。谢谢 @arloor
前言
上次提到可以使用 VSCode + OneDrive + Copilot 组合来写日志,但是有个问题,这里引用的图库是 imgur 和 unsplash 。这两个站点对于国内的访问速度都不是很理想。即使分发到了 mdnice 还是会有图片访问的问题。但是经老哥的提醒,我可以使用 VSCode 的 task 来做一点点事情。
增加一个 mirror 图床
因为我的网站是直接部署到 vercel 的,它本身在国内的访问速度尚可,所以可以利用它进行一次转发,从而实现国内的访问速度。看代码:
import { NextRequest } from 'next/server'
// handle the get request and return the response
export async function GET(
request: NextRequest,
context: { params: { id: string } }
) {
const url = request.nextUrl.searchParams.get('url') ?? ''
if (!checkImageUrl(url)) return new Response('Invalid URL', { status: 400 })
// download the image and return it
const image = await fetch(url)
const imageBuffer = await image.arrayBuffer()
const imageType = image.headers.get('content-type') ?? 'image/jpeg'
const response = new Response(imageBuffer, { status: 200 })
response.headers.set('content-type', imageType)
response.headers.set('cache-control', 'public, max-age=31536000, immutable')
return response
}
function checkImageUrl(url: string) {
return url.match(/https:\/\/i.imgur.com\/[a-zA-Z0-9]+/) ||
url.match(/https:\/\/images.unsplash.com\/photo-[a-zA-Z0-9]+/)
? true
: false
}
这样的话,就可以直接通过 api/i?url=https://i.imgur.com/QNV9QPz.png 进行访问了。速度还可以。
这里应该还有优化的空间,例如权限,例如缓存,例如图片压缩?
这样就有了一个自己的图床,只有在日志里面引用 imgur 的图片,那就可以直接使用这个图床了。
使用 task 对日志进行处理
这里的 task 是指 VSCode 的 task ,可以在 VSCode 的菜单栏中找到,也可以通过快捷键 Ctrl + Shift + B 来打开,也就是上面老哥提到的方法。
在上篇文章中提到,每次我的截图,通过 VSCode 的插件 vscode-imgur 来上传到 imgur ,然后直接粘贴到 markdown 中。还有 unsplash 的图片也是直接粘贴到 markdown 中。这样的话需要一个 format 的处理过程。task 如下:
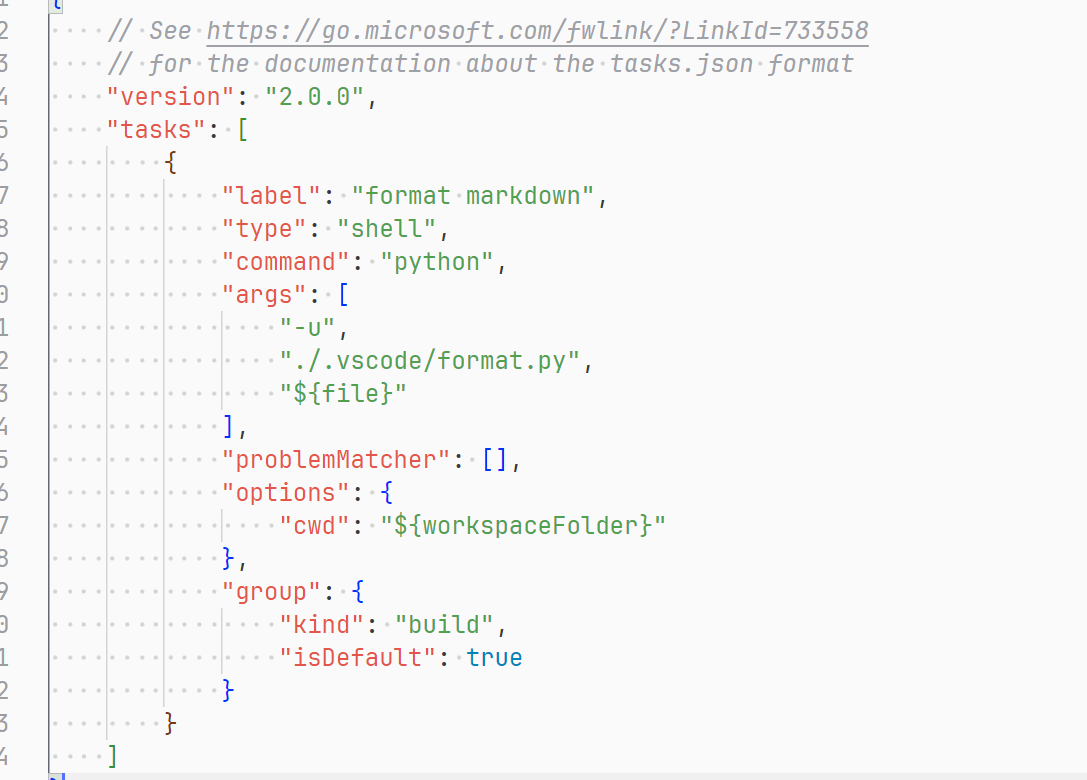
这里的 format.py 是一个 python 脚本,用来处理 markdown 文件,代码如下:
# format the file with replace all imgur links with the vercel mirror
# read the file
with open(format_file, "r", encoding='utf-8') as f:
lines = f.readlines()
# regex  to match the imgur links
r = re.compile(r"!\[.*\]\(( https://.*)\)")
for i, line in enumerate(lines):
# check if the line matches the regex
match = r.match(line)
if not match:
continue
# get the link
link = match.group(1)
if (link.startswith(mirror)):
continue
# replace the link with the vercel mirror
replaced_link = f"{mirror}{link}"
lines = line.replace(link, replaced_link)
has_formatted = True
print(f"Replaced {link} with mirror {replaced_link}")
这样的话,每次可以通过执行 task ,完成 markdown 文件的格式化。另外我还顺便把英文标点符号替换成了中文标点符号。
还有什么步骤可以优化的吗?
