实现了的功能
[ol]
[/ol]
起因
之前在 v2 上提了一个问题,有没有一款类似幕布的可以私有化部署的,开源的大纲笔记软件,有几位老哥热情回复,这里先谢谢了
选型
有人推荐了 logseq ,纯本地,又是 jvm 的一套东西,难绷。
就感觉现在都在做加法,找不到一个合适的,简洁的,维护积极的替代品。
那就找一个最流行的社区最活跃的能满足功能的吧,回到 obsidian ,是 markdown 编辑器,预感能找到适合博客的插件。
markdown 的无序列表外加多层级可折叠,外加 editing toolbar 插件实现高亮,文件完全在自己的掌控,导出什么的也没问题。
就差个实时同步了,官方的 obsidian sync 无缝整合体验舒适,但贵,pass
插件中看中两个,一个 remotely save ,一个 obsidian livesync ,remotely save 支持很多方式,网盘,主要看中 s3 存储,obsidian-livesync 要搭建一个 ocuchDB 的服务器,可以实时同步。
由于还有私有网盘部署和局域网共享文件的需求,我选择了 remotely save ,自己使用 minio 搭建 s3 存储,插件开启每分钟同步以及打开 obsidian 时同步,体验也不错,移动设备不会留 obsidian 常驻
后台,打开会自动同步,pc 上又可以设置快捷键,也很方便。
图片上传到图床使用 image auto upload 插件+picgo core 实现,我自己利用 cf workers 转发到 telegraph 实现了一个图床,写了一个 picgo 插件,限制大小 5M ,一半够用,并且可以保证隐私,国内速度也不是不能用吧。
效果如下,自己参考加载速度,cf 的免费额度很够用了,如果流量大了也可以考虑其他家的服务,要么花点钱

博客打算用之前一直用的主题 zozo ,之前在 halo 时候用的这个,说明是 hugo 移植过来的,页面生成也用 hugo 吧,不过之前用的时候有些不满意的地方自己修改了,现在也不记得改了那些地方,重新改一次记下来吧,可能弄个衍生版以后就不用重新改了,使用插件 shell commands 来自动化的新建文章,开启本机实时预览服务器,使用 git 推送 cf 自动编译部署,写了段 js 和一个 go 程序,js 在本地预览时兼容双链,go 程序在 cf pages 构建时调用,这样可以在 obsidian 中使用双链而不需要其他操作也不用修改源文件就能兼容 hugo 。
总结
至此一个完整的笔记+博客工具链已经完成,依托于 obsidian 强大的生态,无数的插件带来的可塑性和灵活性,我才得以搭建完成合适的,满足需求的工具体系,之后可能会研究下 obsidian 插件,找找好的插件或者自己写写改改逐渐完善使用体验。
本次打造工具链用到的:
[ol]
[/ol]
过程记录
50 块的 cm311-1a 机顶盒刷 debian 用作服务器
之前用作软路由外加 docker 跑一堆服务的蜗牛星际 j1900前不久掉盘了,赶紧拔下来装硬盘盒把数据导出来,然后又拿小米 8+termux 外加自己编译的一堆东西把原本的服务跑起来了,虽然是 arm64 ,骁龙 845 在处理这些任务时也很强,但是始终不是一个正真完整的 linux ,要跑起来处处都是坑,docker 也基本拜拜,重新编译内核什么的想想就头很大,少不了一堆麻烦事,就在最近一次想要部署minio时候,release 的 arm64 二进制文件基本别想,因为安卓的 DNS 跟一般 linux 不一样,普通的 arm64 linux 的 go 程序只要跟 dns 相关的基本都得重新编译,这次也一样,编呗,然后编译完了还是有问题,跑不起来,这时候我已经不想再折腾了,甚至连报错是什么都懒得仔细看了,换平台吧
这时候我手上有cm311-1a,玩客云,还有个创维 e900s,cm311 这个是之前过年期间家人要回来会要看电视,所以买了一个刷原生安卓 TV 装了 TV Box ,youtube 等等给他们看电视用,码率不高放个 4k60 还是没什么问题的,kodi+阿里云 webdav 也很方便,现在这个电视被我搬到房里当显示器了,cm311 就空下来了,相对其他两个内存不到 1g ,arm32 的架构,cm311 的 s905l3a+2+16 强太多了,就用这个吧
之前刷过原生安卓 TV ,开了无线 ADB ,这里是 armbian 的 release 页面,下载需要的版本,解压后使用任意烧录工具烧录进 U 盘,U 盘容量大小 4G 就够了,注意 U 盘对 USB2.0 的兼容性,我手上常用的几个 U 盘都不行,找到一个很久不用的老 U 盘就可以了
刷完之后插在右边 USB 口,具体是否两个口都能用我不太清楚,但是我插右边口是可以的,之后电脑连 ADB ,执行adb shell reboot update就会从 U 盘启动了,我这里用了采集卡并且在另一个 USB 口插了键盘,跟随系统引导完成配置,这里的配置只影响 U 盘内容,登录进入 shell 之后执行armbian-install之后跟随指导完成配置即可,有一个要注意的点就是 dtb 选择时候选305
安装完成之后就能是一台 arm64 的 linux 主机了,现在 arm64 生态也不错,服务器上常用的各种东西都能跑起来,功耗也很低,安逸
遇到的几个坑:
使用 minio 打造私有 s3 存储
参考Minio 的 docker 部署,使用 podman 或者 docker 部署,我这里部署到刚刷完机的 cm311 机顶盒上,不要忘记挂载本地的路径保证持久化,之后登录 minio console 页面创建 bucket 和用户,给用户在 service account 这里创建一个 access key ,保存到本地,之后要用,别搞丢了
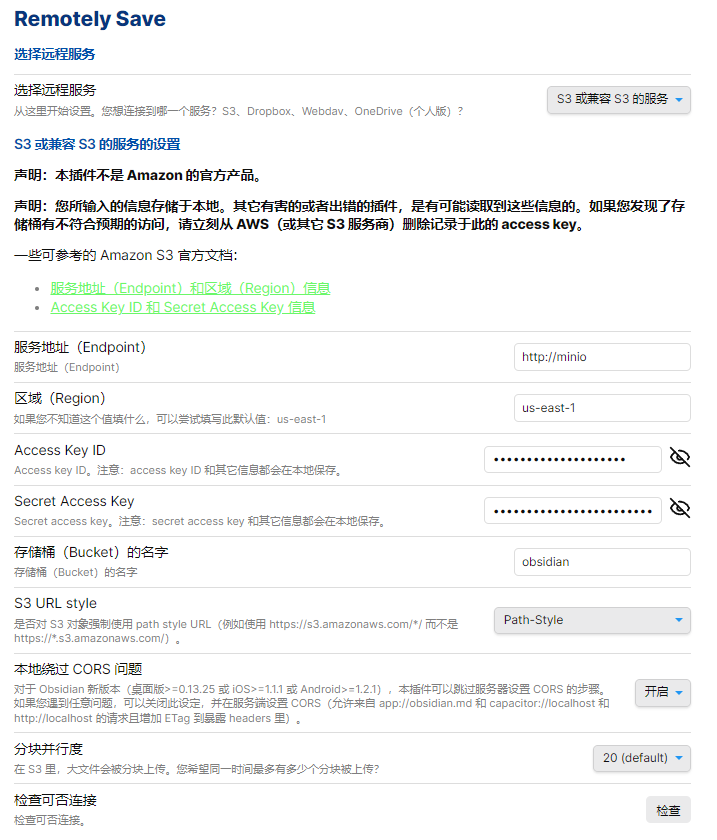
obsidian 使用 remotely save 插件配合 s3 存储实现多设备同步
没什么好说的,参照上面部署的 minio 的信息,填到 remotely save 插件里面即可,参考这个配置,可以按喜好加上快捷键进行同步:
picgo+自建 telegraph 代理图床实现无限图片存储
使用 go 语言重写了picgo upload功能,替代很重的node+picgo实现与 obsidian 插件image auto upload plugin配和自动上传图片到图床
已经更换图床和自动上传的方案为 go 重写的,这里适合使用 picgo 的用户参考,telegraph 的代理还是参照这里的搭建
为什么要这么做
telegraph 提供匿名的图片存储,单张图片限制 5M ,基本不存在被和谐的情况,并且不限数量
telegrah 在国内无法访问,所以基于 telegraph 的图床在国内也是无法使用,但是 cloudflare 的 workers 在国内是可以使用的,所以打算使用 worker 代理访问 telegraph
过程
cloudfalre workers 部分:
考虑到以后可能还会扩充功能,这里先把 router 功能独立出来
入口文件worker.js:
import router from './router';
export default {
async fetch(request, env, ctx) {
return router.handle(request)
}
}
路由和请求处理router.js:
import { Router } from 'itty-router';
const router = Router();
router.get('/file/:id', handleRequest)
router.post('/upload', handleRequest)
async function handleRequest(request) {
const url = new URL(request.url);
const response = fetch('https://telegra.ph/' + url.pathname + url.search, {
method: request.method,
headers: request.headers,
body: request.body,
});
return response
}
router.all('*', () => new Response('Not Found.', { status: 404 }));
export default router;
之后就可以用 worker 的域名加上upload或者file路径来进行上传和访问图片,默认的 worker 域名容易被墙,换自己域名比较稳定
picgo 部分:
这里需要写一个 picgo 的 uploader 插件来完成对我们自建图床的上传和取回 url ,参考官方插件模板在你的picgo 配置文件目录初始化一个空插件,初始化完成之后,修改生成的文件的src/index.js,改成如下内容:
const handle = async ctx => {
let output = ctx.output
output = await Promise.all(
output.map(async e => {
e.imgUrl = await upload(e.buffer, e.filename)
e.url = e.imgUrl
return e
})
)
ctx.output = output
return ctx
}
async function upload(buffer, filename) {
const { lookup } = require('mime-types')
let img = new FormData()
const file = new Blob([buffer], { type: lookup(filename) });
img.set('file', file, filename)
let res = await fetch("https://telegra.ph/upload", {
"body": img,
"method": "POST"
})
res = await res.json()
return 'https://telegra.ph' + res[0].src
}
module.exports = ctx => {
const register = () => {
ctx.helper.uploader.register('telegraph', { handle })
}
return {
register,
uploader: 'telegraph' // 请将 uploader 的 id 注册在这里
}
}
需要在插件根的目录执行npm i mime-types来安装mime-types,我写的这个需要mime-types判断类型,之后参照插件测试来安装插件,picgo 配置文件中开启并选用刚写的插件:
{
"picBed": {
"uploader": "telegraph",
"current": "telegraph"
},
"picgoPlugins": {
"picgo-plugin-telegraph": true
}
}
注意这里的插件的名称和 id 是你创建时候的名称和在上面代码里注册的 idtelegraph
配置完成之后正常的使用 picgo 即可
使用 go 语言实现 picgo 部分功能
起因
之前使用picgo+telegraph 代理+Obsidian 插件image Auto Upload Plugin实现图片自动上传到 telegraph 图床,效果完美,但是需要nodejs运行环境,还要装一堆依赖,虽然我主力机因为搭建了各种开发环境本来就有nodejs环境,但是我的另一台轻薄本我是不想装这么多乱七八糟的东西了,于是就想着找一个解决方案
过程记录
我的要求:
go 语言恰好符合平台通用性要求,这里使用 go 语言实现,这里先来看看image Auto Upload Plugin如何运作,以下是操作picgo-core上传的核心逻辑代码
export class PicGoCoreUploader {
async uploadFiles(fileList: Array): Promise {
let command = `${cli} upload ${fileList
.map(item => `"${item}"`)
.join(" ")}`;
const res = await this.exec(command);
const splitList = res.split("\n");
const splitListLength = splitList.length;
const data = splitList.splice(splitListLength - 1 - length, length);
if (res.includes("PicGo ERROR")) {
} else {
return {
success: true,
result: data,
};
}
}
}
// PicGo-Core 上传处理
async uploadFileByClipboard() {
const res = await this.uploadByClip();
const splitList = res.split("\n");
const lastImage = getLastImage(splitList);
if (lastImage) {
return {
code: 0,
msg: "success",
data: lastImage,
};
} else {
//错误处理
}
}
// PicGo-Core 的剪切上传反馈
async uploadByClip() {
let command;
if (this.settings.picgoCorePath) {
command = `${this.settings.picgoCorePath} upload`;
} else {
command = `picgo upload`;
}
const res = await this.exec(command);
return res;
}
}
export function getLastImage(list: string[]) {
const reversedList = list.reverse();
let lastImage;
reversedList.forEach(item => {
if (item && item.startsWith("http")) {
lastImage = item;
return item;
}
});
return lastImage;
}
大概的逻辑就是:从剪切板粘贴就使用child_process执行picgo upload,其他的就执行picgo upload xxx1.jpg xxx2.jpg,然后从控制台输出读取上传之后图片的网址,每行一个,从最后一行读取跟参数数量一样的行数作为图片网址,如果是剪切板上传就读取最后一个 http 开头的字符串
理解逻辑之后就可以开始写了:
package main
import (
"bytes"
"fmt"
"image/png"
"io"
"io/ioutil"
"mime/multipart"
"net/http"
"os"
"strings"
"golang.design/x/clipboard"
)
func uploadImage(file bytes.Buffer) {
buf := new(bytes.Buffer)
wr := multipart.NewWriter(buf)
fw, err := wr.CreateFormFile("uploadfile", "image.png")
if err != nil {
panic(err)
}
io.Copy(fw, &file)
wr.Close()
req, err := http.NewRequest("POST", "https://telegra.ph/upload", buf)
req.Header.Set("Content-Type", wr.FormDataContentType())
client := &http.Client{}
resp, err := client.Do(req)
body, _ := ioutil.ReadAll(resp.Body)
str := string(body)
str = strings.TrimPrefix(str, `[{"src":"\/file\/`)
str = strings.TrimSuffix(str, `"}]`)
fmt.Println("https://telegra.ph/file/" + str)
}
func main() {
if len(os.Args) == 2 && os.Args[1] == "upload" {
var file bytes.Buffer
img := clipboard.Read(clipboard.FmtImage)
if img != nil {
img, err := png.Decode(bytes.NewReader(img))
if err != nil {
panic(err)
}
png.Encode(&file, img)
}
uploadImage(file)
} else if len(os.Args) > 2 && os.Args[1] == "upload" {
for _, filePath := range os.Args[2:] {
var file bytes.Buffer
f, err := os.Open(filePath)
if err != nil {
panic(err)
}
defer f.Close()
io.Copy(&file, f)
uploadImage(file)
}
} else {
fmt.Println("Usage: go run main.go upload [image1] [image2] ...")
}
}
写完了,把编译出来的程序改名成picgo.exe或者 linux 下改成picgo放在path里,或者在image Auto Upload Plugin里面设置路径,粘贴和拖入图片自动上传功能使用正常
有需要的可以自己拿去编译一下用,如果你的网络访问telegraph有障碍,可以参考[[picgo+自建 telegraph 代理图床实现无限图片存储]]搭建自己的代理,再把程序中的域名换成你自己的,之后可能更完善些支持其他图床,暂时就不扔 github 了,也许未来某天会继续完善,但是目前已经够我用了,如果有你有自己的需求可以在这上面改改拿着用
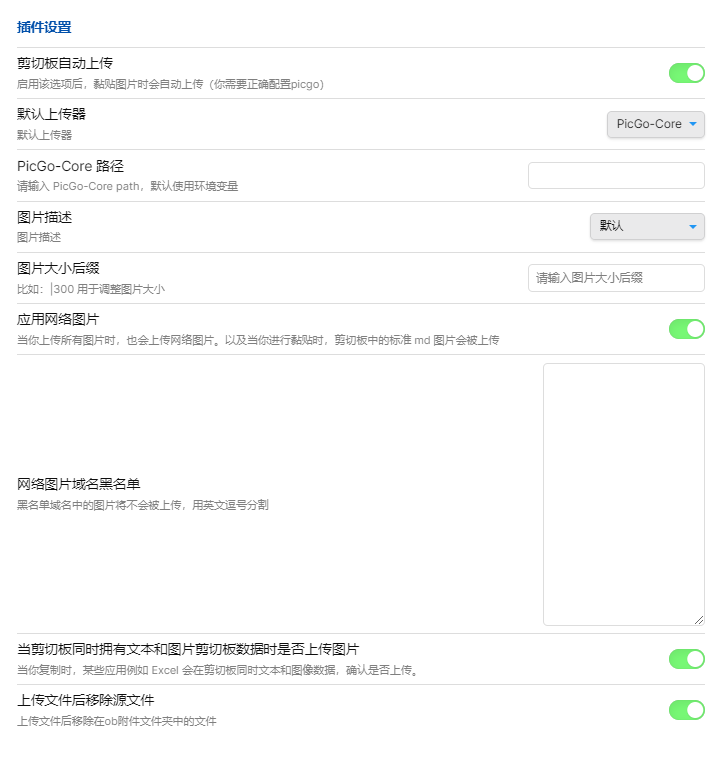
obsidian 插件 image auto upload plugin 配和 picgo 实现图片实时上传
参照图片设置image auto upload plugin,确保 path 内有可以正常运行的 picgo ,
可以参照picgo+自建 telegraph 代理图床实现无限图片存储或者使用 go 语言实现 picgo 部分功能来配置 picgo 或者使用 go 语言重写的 picgo
obsidian 插件 shell commands 实现 hugo 博客编辑实时预览
起因
想要一边编辑一边实时看到 hugo 页面的样子
过程记录
安装shell commands插件
在shell commands插件内新建一个shell command,填入以下内容,我这里设置了快捷键alt + B,运行就会尝试杀死在运行的 hugo 程序并开启一个 hugo 的服务端,指定端口 5678 并自动跳转到变化的页面,并且渲染草稿,记得把cd后的目录改成你的博客根目录
$processName = "hugo"
$process = Get-Process $processName -ErrorAction SilentlyContinue
if ($process) {
Stop-Process -Name $processName -Force
}
cd C:\Users\username\Documents\Notes\Notes\博客
hugo server --navigateToChanged --buildDrafts -p 5678
chrome http://localhost:5678
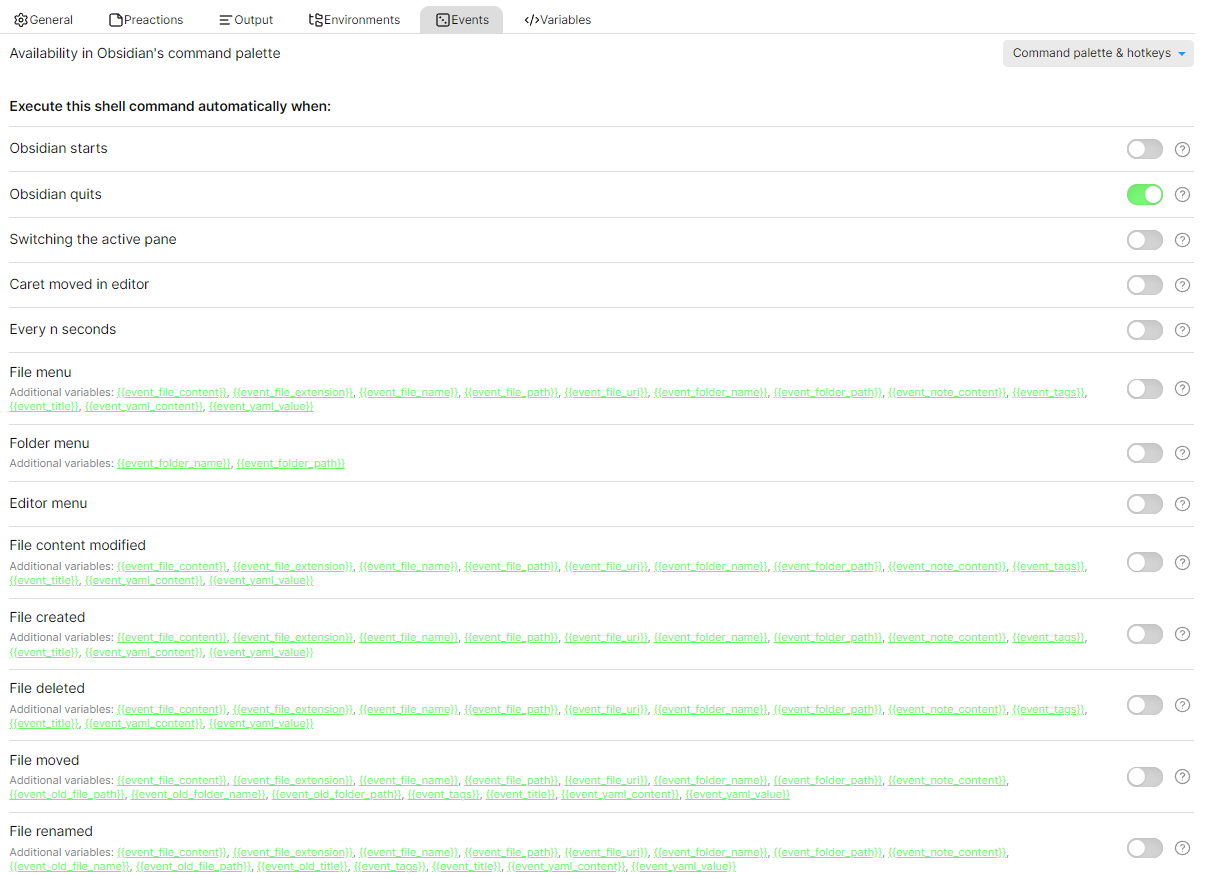
再新建一个shell command,填入以下内容
$processName = "hugo"
$process = Get-Process $processName -ErrorAction SilentlyContinue
if ($process) {
Stop-Process -Name $processName -Force
}
之后设置 event ,打开obsidian quits,这样退出 obsidian 时候 hugo 服务端也会被关掉
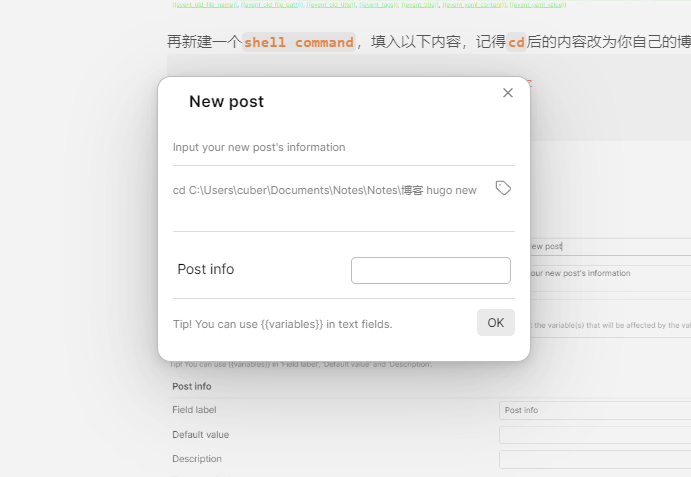
再新建一个shell command,填入以下内容,记得cd后的内容改为你自己的博客位置
cd C:\Users\username\Documents\Notes\Notes\博客
hugo new {{_postInfo}}
然后新建一个 preaction ,配置如图
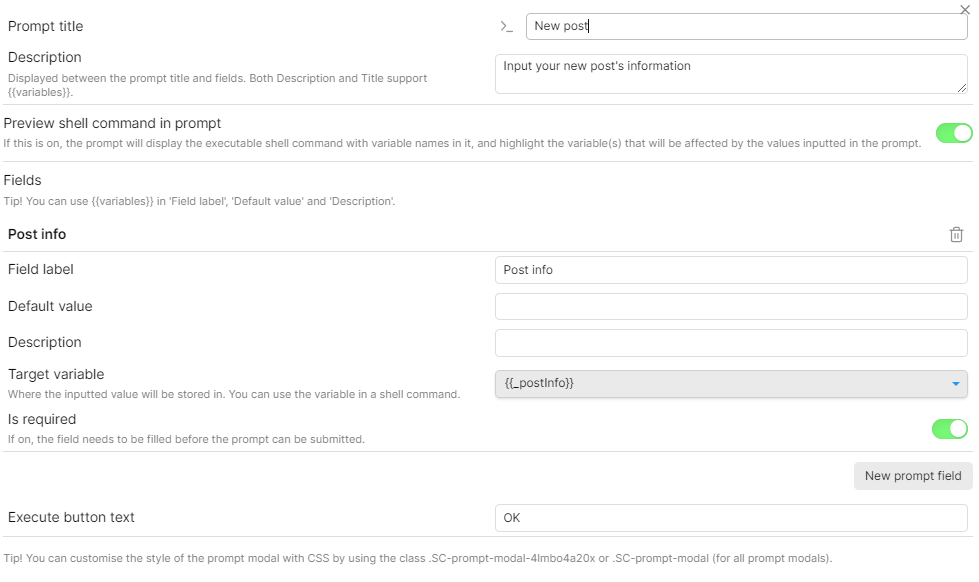
可以设置快捷键快速创建一篇博客,也可以用ctrl + P调出命令面板选择,之后弹窗需要填入内容,把正常使用hugo new之后的参数填在这里即可
再新建一个shell command,填入以下内容,记得cd后的内容改为你自己的博客位置,这样就能快速提交
cd C:\Users\username\Documents\Notes\Notes\博客
git add *
git commit -m "update post"
git push origin master
效果
我在这里把几个命令都绑定了快捷键,alt + N新建文章,alt + B开启实时预览,外加使用alt + P执行发布到 cloudflare pages ,很流畅,几秒钟就完成了页面更新,外加obsidian 兼容 hugo 的解决方案支持实时网页预览不修改本地 markdown 源文件这里实现的对双链的兼容,又有 obsidian 提示快速补全到文章的链接,真的很舒服
obsidian 兼容 hugo 的解决方案支持实时网页预览不修改本地 markdown 源文件
起因
之前选择 hugo 作为博客的页面生成器,用 obsidian 来编辑,体验不错,但是也有些问题,比如在[[obsidian 插件 shell commands 实现 hugo 博客编辑实时预览]]这篇文章中实现的效果中,obsidian 的双链[[]]不受支持,预览时候不会转换成链接,就只显示原来的文本
我想要实现的效果:
过程记录
首先想到的是 hugo 会不会有预处理 markdown 的功能,或者插件能实现,但是搜了一圈资料,无解,而且是老早就有人提过的问题,一直没有很好的解决
之后想通过修改 hugo 源码,在渲染页面之前对读取的 markdown 字符串加一个预处理,为此翻了半天 hugo 源码,改出了第一版的满足我要求的 hugo ,但是这里还是有些问题的,首先我对 hugo 的源码并没有全面的了解,会不会引入新 bug 不可知,其次在 cloudflare 的页面生成环境里面又要拉一次我的改版 hugo ,很麻烦,并且之后 hugo 每次更新我都要重新拉下来检查修改编译,很麻烦
我没找到 obsidian 的双链信息存储的位置,markdown 内也只有[[文章名]],并且只有在不同路径有同名文章时候才需要指定路径,猜测是把所有文章的标题用来匹配,而没有存储链接关系,理论上是可行的,所以后面把双链转换成网页的链接也从这个思路出发,先获取所有文章名和对应的地址,再根据[[文章名]]进行匹配
现在的解决方案是:
注意并不支持标题里有特殊符号,这里只对空格进行了处理,实际因为没去仔细研究 hugo 的转换规则只做简单处理,如果未来有需要会去看 hugo 源码的转换规则修改油猴脚本和 convert 转换程序
本地实时预览时候,在油猴脚本加一段代码,实时修改 html 实现双链文本转链接,具体实现如下:
// ==UserScript==
// @name obsidian link convert
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match http://localhost:5678/*
// @icon https://www.google.com/s2/favicons?sz=64&domain=undefined.localhost
// @grant none
// @run-at document-start
// ==/UserScript==
(function() {
document.addEventListener('DOMContentLoaded',() => {
async function getSitemapLinks(sitemapUrl) {
const response = await fetch(sitemapUrl);
const data = await response.text();
const parser = new DOMParser();
const doc = parser.parseFromString(data, 'application/xml');
const urls = Array.from(doc.querySelectorAll('url loc')).map(loc => loc.textContent);
return urls;
}
(async () => {
const sitemapUrl = 'http://localhost:5678/sitemap.xml';
const links = await getSitemapLinks(sitemapUrl);
let pages=links.map(e=>decodeURI(e.split('/').at(-2)))
const map = pages.reduce((acc, key, index) => {
acc.set(key, links[index]);
return acc;
}, new Map());
function replaceBracketsWithLinks(element = document.body) {
const regex = /\[\[(.*?)\]\]/g;
element.childNodes.forEach(node => {
if (node.nodeType === Node.TEXT_NODE && regex.test(node.textContent)) {
const span = document.createElement('span');
span.innerHTML = node.textContent.replace(regex, (match, text) => {
const urlText = text.replace(/ /g, "-");
const link = map.get(urlText);
return `${text}`;
});
node.parentNode.replaceChild(span, node);
} else if (node.nodeType === Node.ELEMENT_NODE && node.nodeName !== 'CODE' && node.nodeName !== 'PRE') {
replaceBracketsWithLinks(node);
}
});
}
replaceBracketsWithLinks()
})();
})
})();
主要的逻辑是:获取 sitemap 里面的所有链接,提取最后两个/之间的文本作为文章名,再把页面中的所有[[文章名]]替换成 a 标签,链接指向之前从 sitemap 获取的该名称对应的链接
实际效果是可以完成我的需求的,修改效果没问题,但是还是有些问题,在开启 MathJax 时候会把[[]]转换成数学公式,我一般是把 MathJax 关掉的,所以影响不大,如果你有需求,还是要自己探索
cloudflare 部署时候,改一下发布执行的命令,在前面加个预处理程序,把所有 markdown 内的双链都修改成 hugo 支持的链接,我写了一个 go 程序来实现:
package main
import (
"fmt"
"io/fs"
"io/ioutil"
"os"
"path/filepath"
"regexp"
"strings"
)
func processFileContent(content string, names []string, paths []string) string {
re := regexp.MustCompile(`\[\[(.*?)\]\]`)
return re.ReplaceAllStringFunc(content, func(match string) string {
name := match[2 : len(match)-2]
index := indexOf(names, name)
if index >= 0 {
path := paths[index]
path = strings.ReplaceAll(path, "\\", "/")
path = strings.TrimSuffix(path, ".md")
contentIndex := strings.Index(path, "content")
if contentIndex >= 0 {
path = path[contentIndex+len("content"):]
}
path = strings.ReplaceAll(path, " ", "-")
return fmt.Sprintf("[%s](%s)", name, path)
}
return match
})
}
func indexOf(slice []string, value string) int {
for i, v := range slice {
if v == value {
return i
}
}
return -1
}
func main() {
var paths []string
var names []string
filepath.WalkDir("content", func(path string, d fs.DirEntry, err error) error {
if err != nil {
return err
}
if !d.IsDir() && strings.HasSuffix(d.Name(), ".md") {
paths = append(paths, path)
names = append(names, strings.TrimSuffix(d.Name(), ".md"))
}
return nil
})
for _, path := range paths {
contentBytes, err := ioutil.ReadFile(path)
if err != nil {
panic(err)
}
content := string(contentBytes)
newContent := processFileContent(content, names, paths)
err = ioutil.WriteFile(path, []byte(newContent), os.ModePerm)
if err != nil {
panic(err)
}
}
}
主要逻辑是:遍历 content 文件夹,获取所有的 markdown 文件的名称和路径,再按照名称和路径的映射关系,把所有 markdown 内的[[文章名]]替换成匹配到的文章的 hugo 可以识别的链接
编译一份 linux 的可执行文件 convert ,放到博客的的根目录,再用 git 上传到 github ,cloudflare 拉取仓库时候就可以获取到转换用的程序,把发布命令修改成chmod 755 convert && ./convert && hugo,就能先执行转换程序再使用 hugo 发布
