声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请联系作者立即删除!
逆向目标
什么是 JSVMP?
JSVMP 全称 Virtual Machine based code Protection for JavaScript,即 JS 代码虚拟化保护方案。
JSVMP 的概念最早应该是由西北大学2015级硕士研究生匡开圆,在其2018年的学位论文中提出的,论文标题为:《基于 WebAssembly 的 JavaScript 代码虚拟化保护方法研究与实现》,同年还申请了国家专利,专利名称:《一种基于前端字节码技术的 JavaScript 虚拟化保护方法》,网上可以直接搜到,也可在公众号【K哥爬虫】后台回复 JSVMP,免费获取原版高清无水印的论文和专利。本文就简单介绍一下 JSVMP,想要详细了解,当然还是建议去读一下这篇论文。

JSVMP 的核心是在 JavaScript 代码保护过程中引入代码虚拟化思想,实现源代码的虚拟化过程,将目标代码转换成自定义的字节码,这些字节码只有特殊的解释器才能识别,隐藏目标代码的关键逻辑。在匡开圆的论文中,利用 WebAssembly 技术实现了特殊的虚拟解释器,通过编译隐藏解释器的执行逻辑。JSVMP 的保护流程如下图所示:
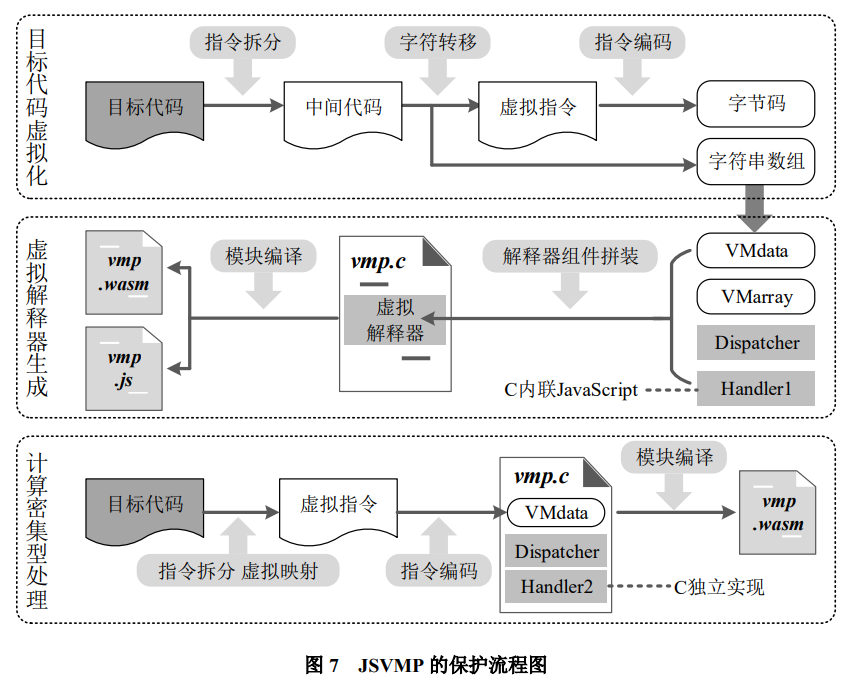
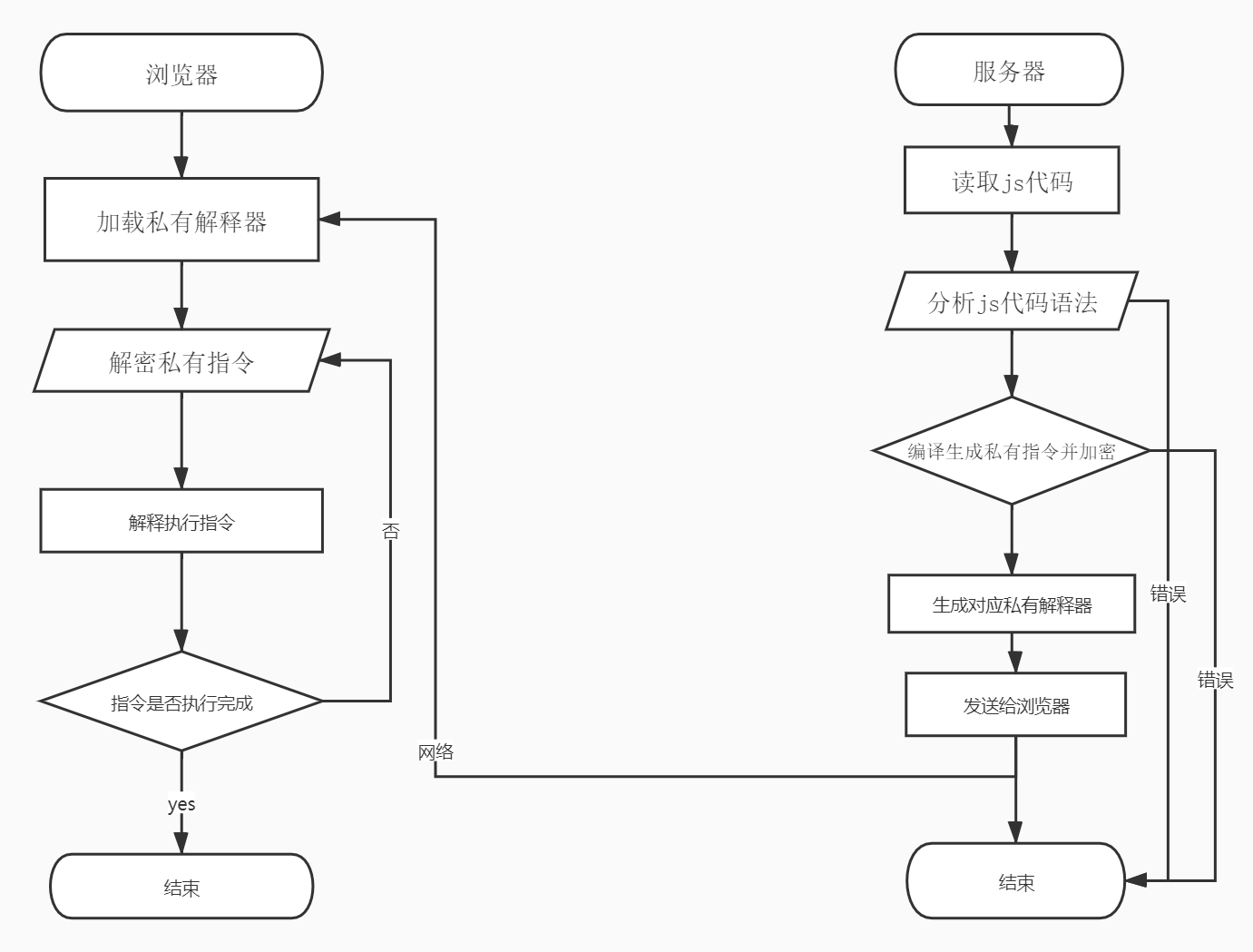
一个完整的 JSVMP 保护系统,大致的架构应该是这样子的:服务器端读取 JavaScript 代码 —> 词法分析 —> 语法分析 —> 生成AST语法树 —> 生成私有指令 —> 生成对应私有解释器,将私有指令加密与私有解释器发送给浏览器,然后一边解释,一边执行。
JSVMP 有哪些学习资料?
除了匡开圆的论文以外,还有以下文章也值得学习:
JSVMP 逆向方法有哪些?
就目前来讲,JSVMP 的逆向方法有三种(自动化不算):RPC 远程调用,补环境,日志断点还原算法,其中日志断点也称为插桩,找到关键位置,输出关键参数的日志信息,从结果往上倒推生成逻辑,以达到算法还原的目的,RPC 技术K哥以前写过文章,补环境的方式以后有时间再写,本文主要介绍如何使用插桩来还原算法。
抓包情况
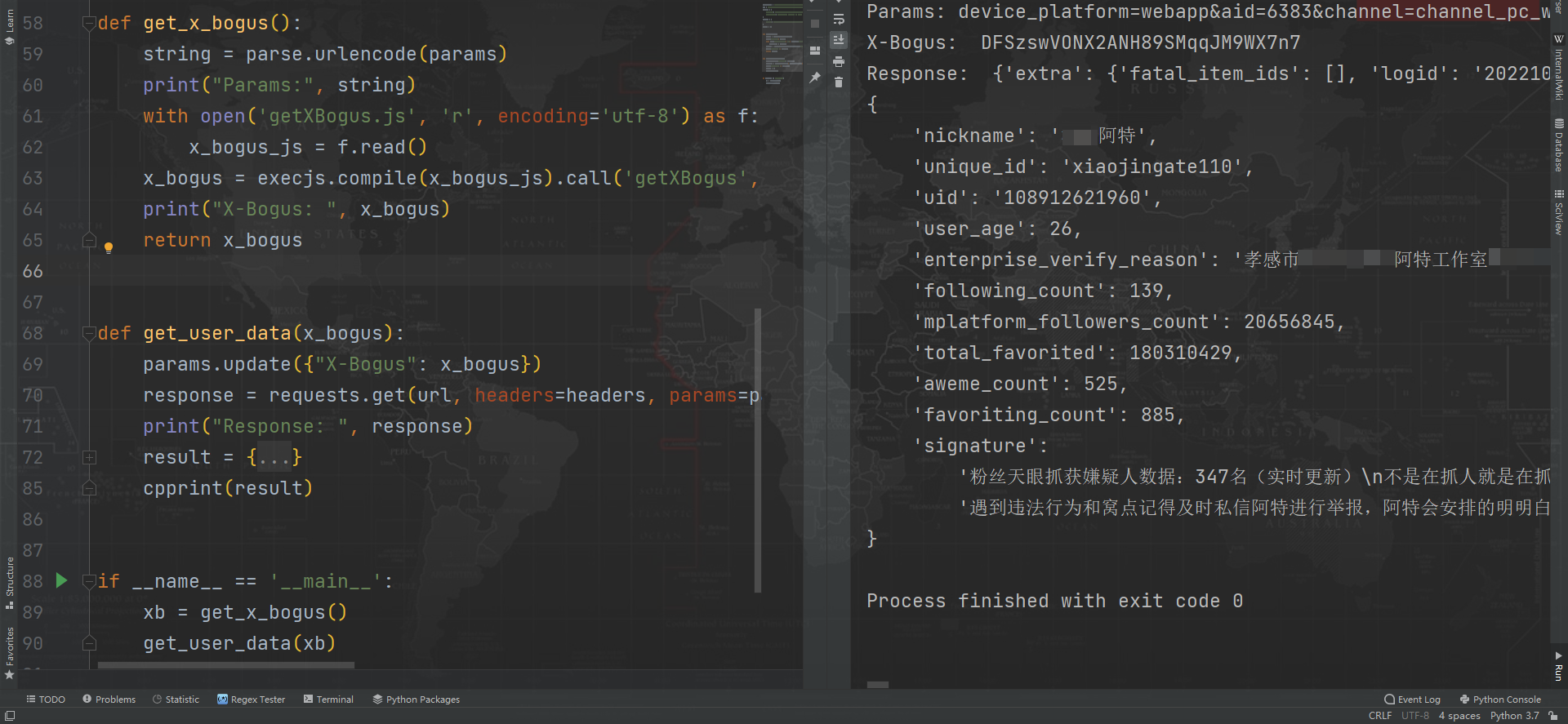
随便来到某个博主主页,抓包后搜索可发现一个接口,返回的是 JSON 数据,里面包含了博主某音号,认证信息、签名,关注、粉丝、获赞等,请求 Query String Parameters 里包含了一个 X-Bogus 参数,每次请求会改变,此外还有 sec_user_id 是博主主页 URL 后面那一串,webid 直接请求主页返回内容里就有,msToken 与 cookie 有关,清除 cookie 访问,就没这个参数了,实测该接口不验证 webid 和 msToken,直接置空即可。
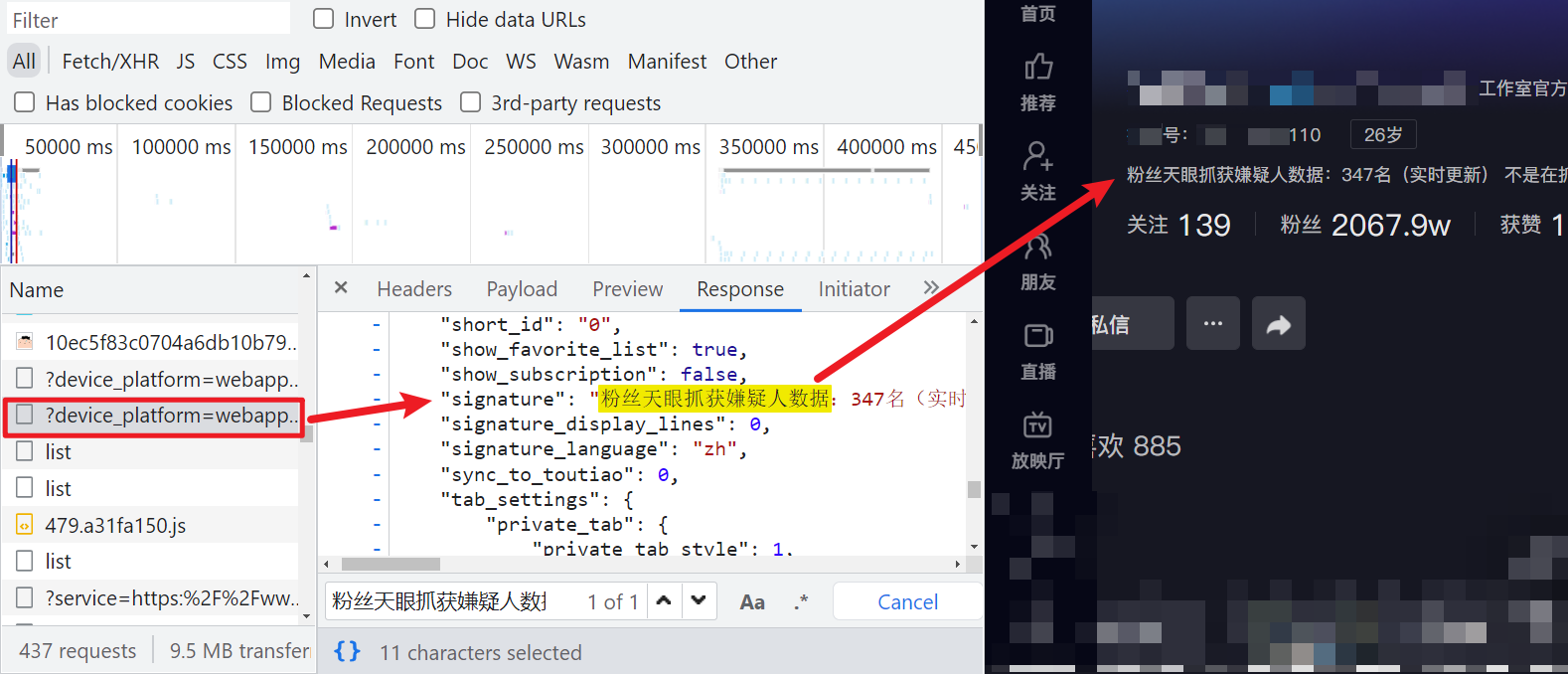
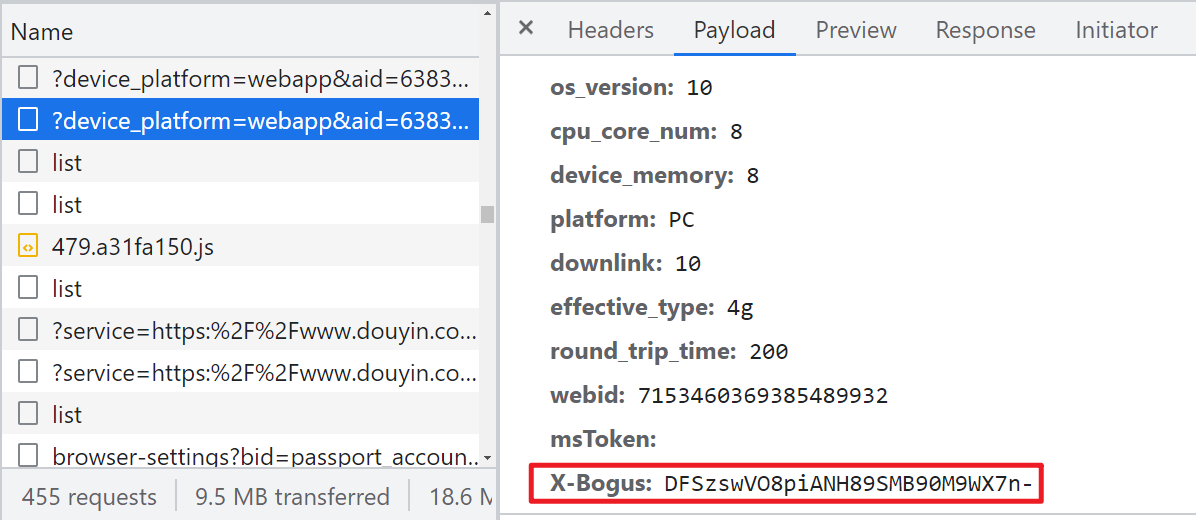
逆向分析
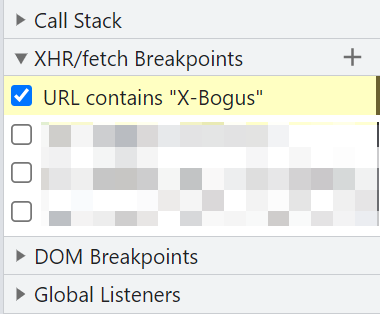
这条请求是 XHR 请求,所以直接下个 XHR 断点,当 URL 中包含 X-Bogus 参数时就断下:
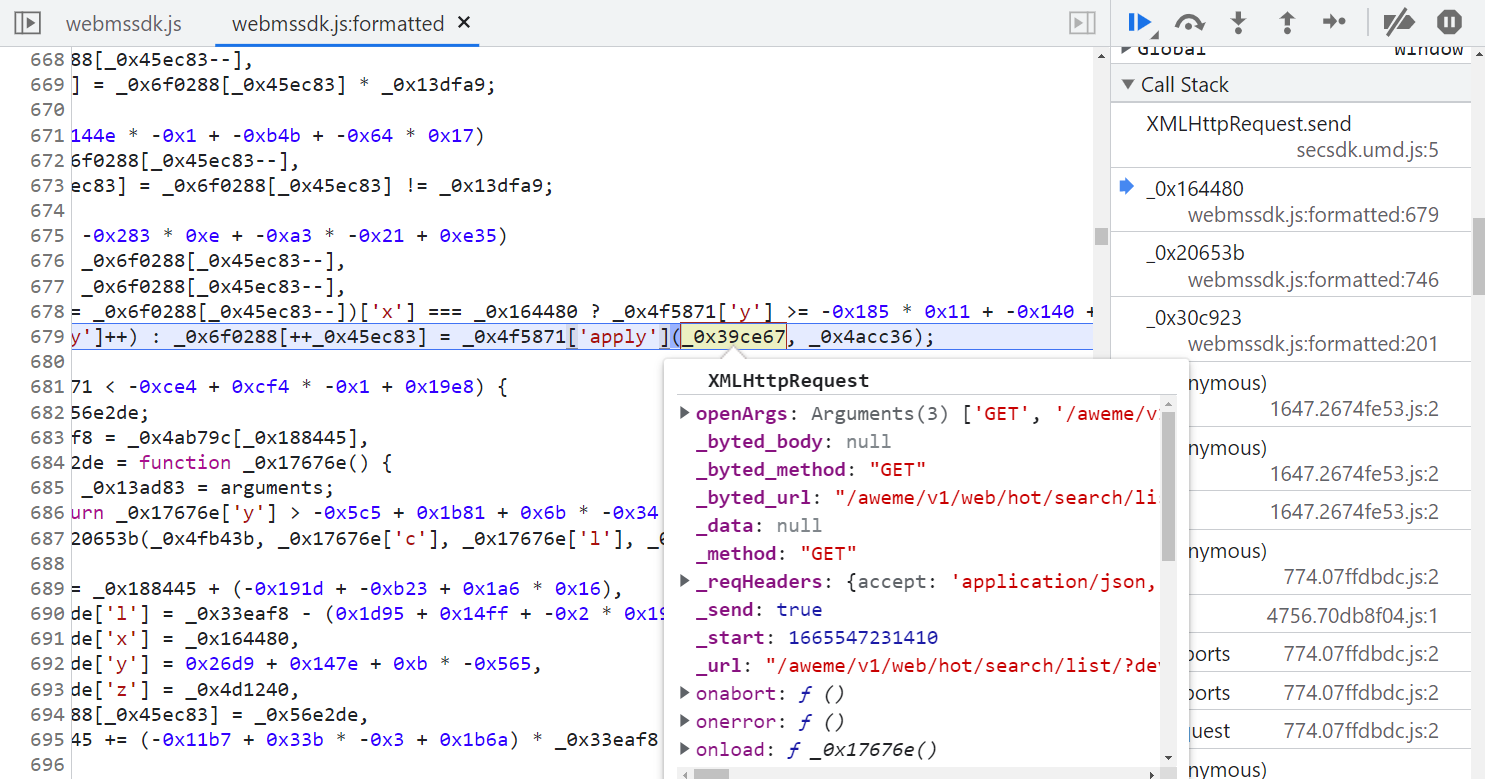
往前跟栈,来到一个叫 webmssdk.js 的 JS 文件,这里就是生成参数的主要 JS 逻辑了,也就是 JSVMP,整体上做了一个混淆,这里可以使用 AST 来解混淆,K哥以前同样也写过 AST 的文章,这里还原混淆不是重点,咱们直接使用 V 佬的插件 v_jstools 来还原:
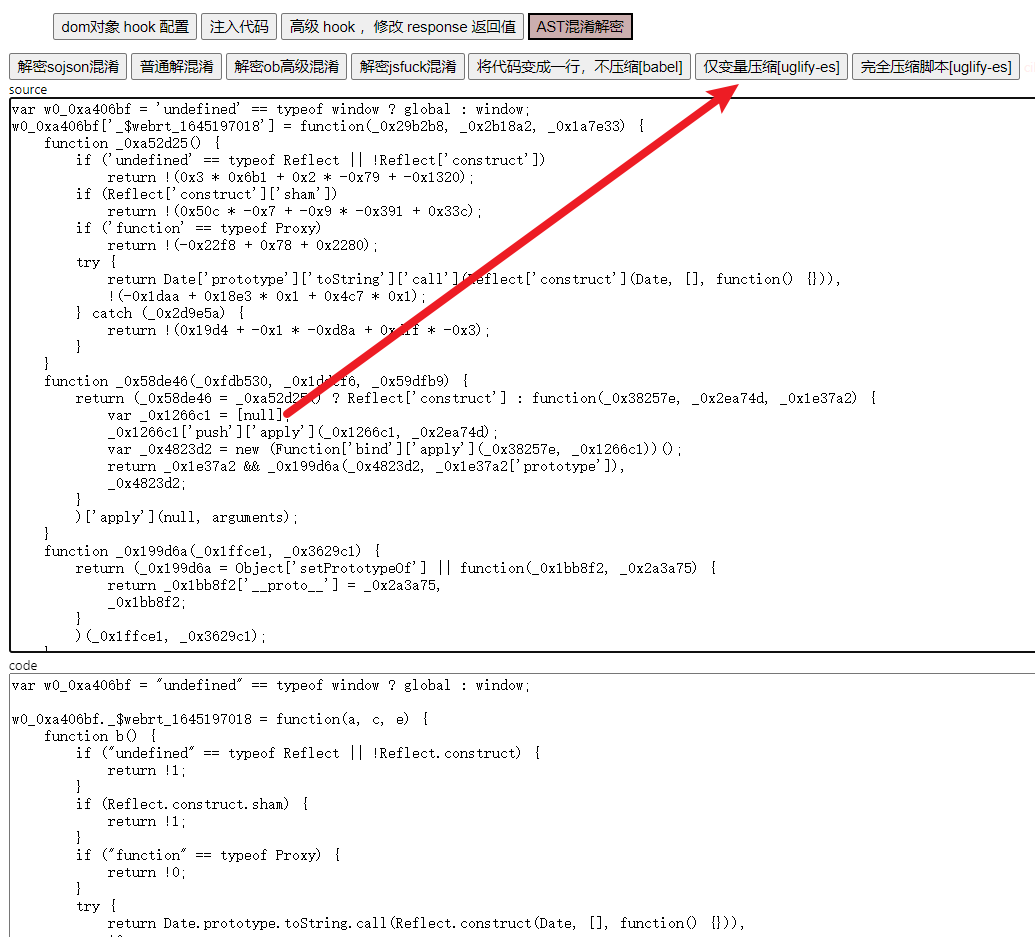
还原后使用浏览器的 Overrides 替换功能将 webmssdk.js 替换掉,往上跟栈,如下图所示,到 W 这里就已经生成了 X-Bogus 了,this.openArgs[1] 就是携带了 X-Bogus 的完整 URL,仔细观察这段代码,有很多三元表达式,当 M 的值为 15 时,就会走到这段逻辑,U 的值生成之后,有一个 S[C] = U 的操作。
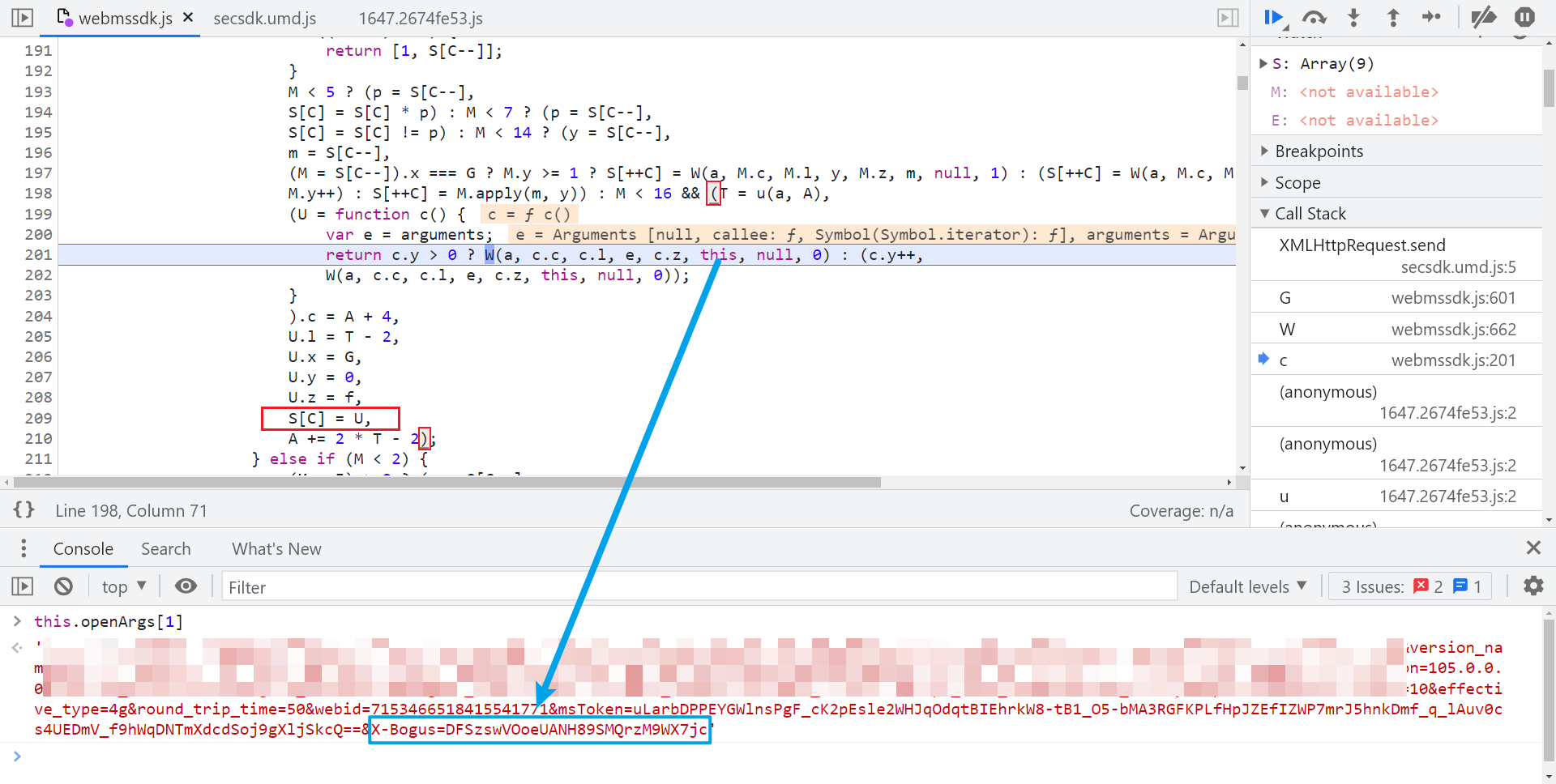
再往上看代码,S 是一个数组,单步调试的话会发现代码会一直走这个 if-else 的逻辑,几乎每一步都有 S 数组的参与,不断往里面增删改查值,for 循环里面的 I 值,决定着后续 if 语句的走向,这里也就是插桩的关键所在,如下图所示:
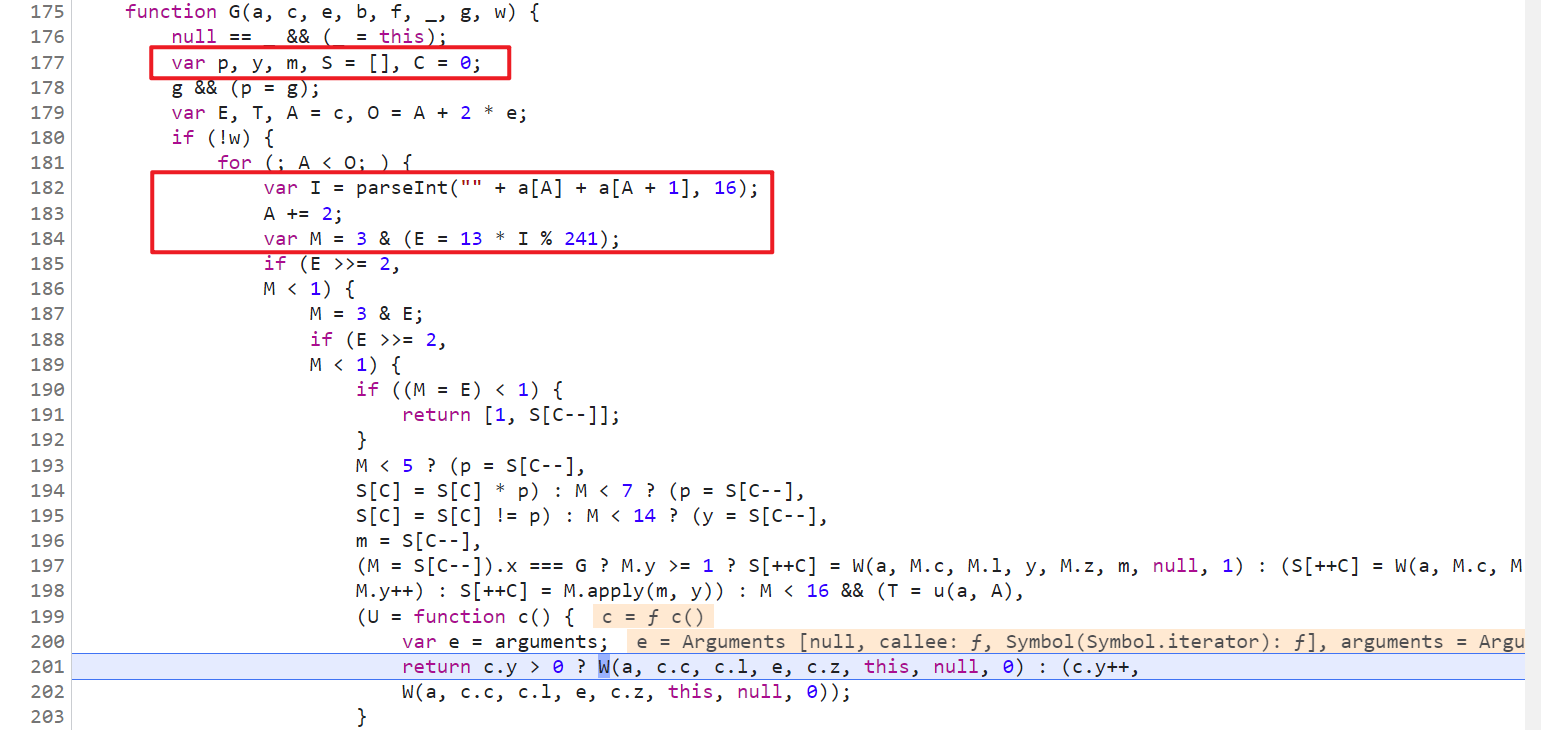
插桩分析
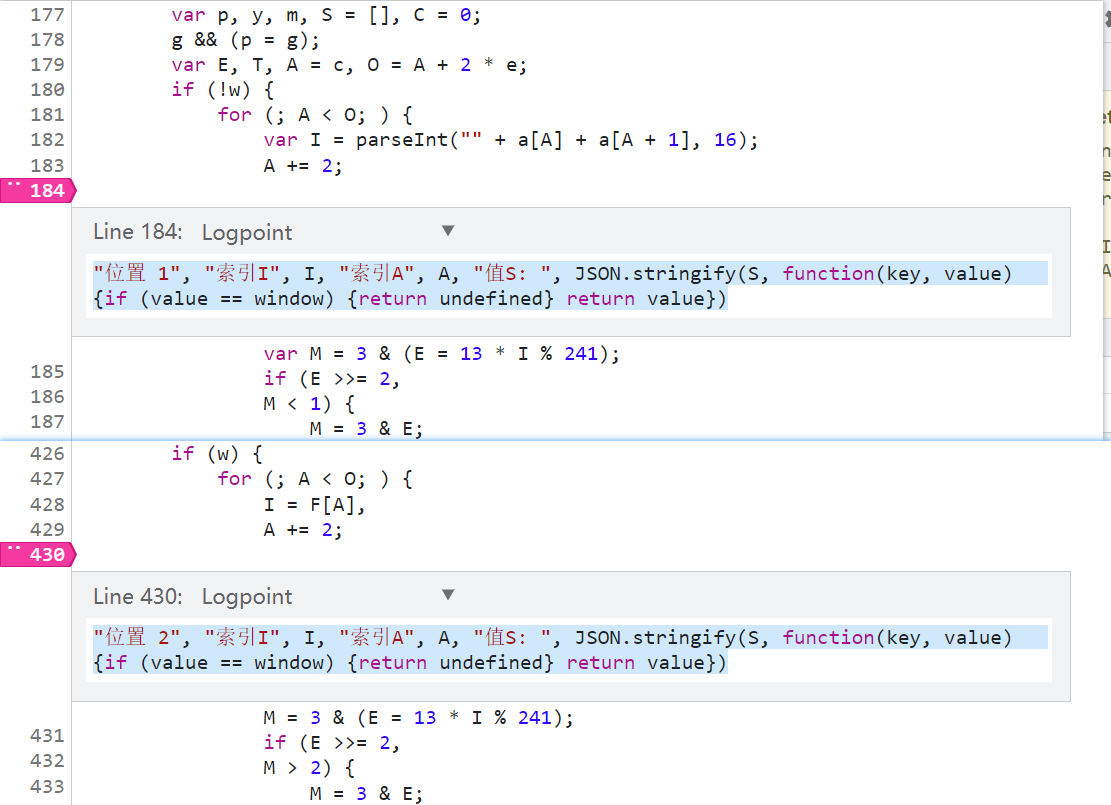
大的 for 循环和 if-else 逻辑有两个地方,为了保证最后的日志更加详细完整,在这两个地方都下个日志断点(右键 Add logpoint),断点内容为:
"位置 1", "索引I", I, "索引A", A, "值S: ", JSON.stringify(S, function(key, value) {if (value == window) {return undefined} return value})
"位置 2", "索引I", I, "索引A", A, "值S: ", JSON.stringify(S, function(key, value) {if (value == window) {return undefined} return value})
插桩输出 S 的时候为什么要写这么长一串呢?首先 JSON.stringify() 方法的作用是将 JavaScript 值转换为 JSON 字符串,基础语法是 JSON.stringify(value[, replacer [, space]]),如果不将其转换成 JSON,那么 S 的值,输出可能是这样的:[empty, Array(26), 1, Array(0)],你看不到 Array 数组里面具体的值,该方法有个可选参数 replacer,如果 replacer 为函数,则 JSON.stringify 将调用该函数,并传入每个成员的键和值,在函数中可以对成员进行处理,最后返回处理后的值,如果此函数返回 undefined,则排除该成员,举个例子:
var obj1 = {key1: 'value1', key2: 'value2'}
function changeValue(key, value) {
if (value == 'value2') {
return '公众号:K哥爬虫'
} return value
}
var obj2 = JSON.stringify(obj1, changeValue)
console.log(obj2)
// 输出:{"key1":"value1","key2":"公众号:K哥爬虫"}
上面的代码中 JSON.stringify 传入了一个函数,当 value 为 value2 的时候就将其替换成字符串 公众号:K哥爬虫,接下来我们演示一下当 value 为 window 时,会发生什么:
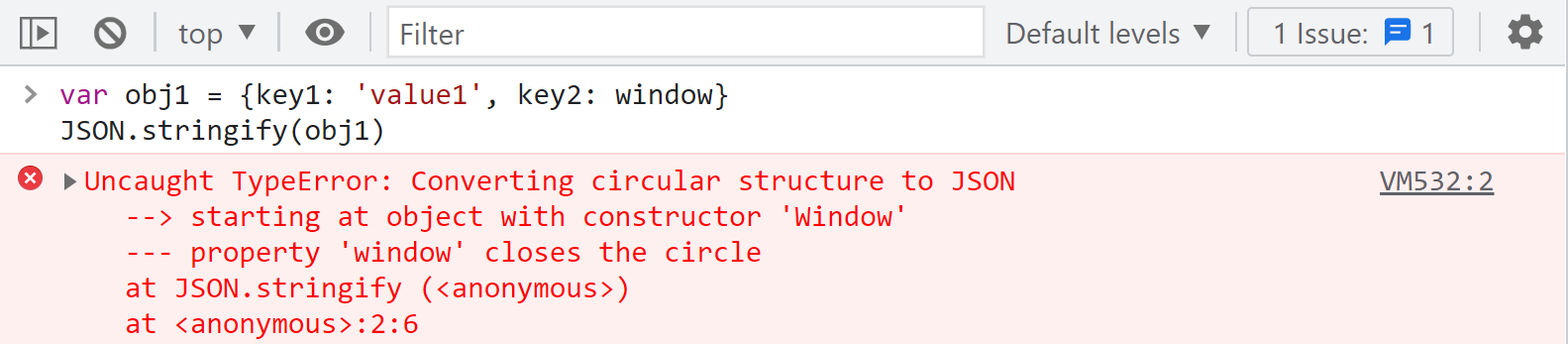
根据报错我们可以看到这里由于循环引用导致异常,要知道在插桩的时候,如果插桩内容有报错,就会导致不能正常输出日志,这样就会缺失一部分日志,这种情况我们就可以加个函数处理一下,让 value 为 window 的时候,JSON 处理的时候函数返回 undefined,排除该成员,其他成员正常输出,如下图所示:
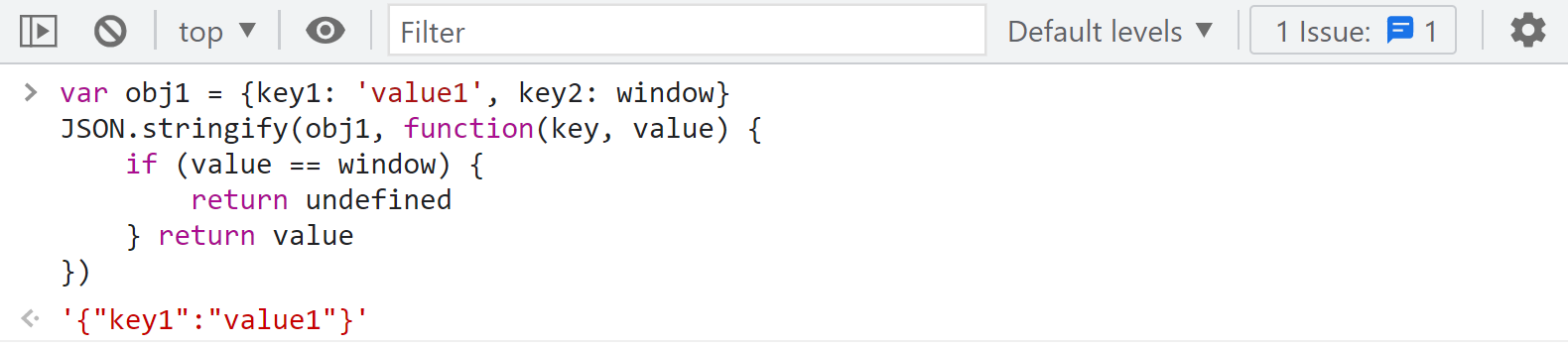
以上就是日志断点为什么要这样写的原因,下好日志断点后,注意前面我们下的 XHR 断点不要取消,然后刷新网页,控制台就开始打印日志了,因为有很多 XHR 请求都包含了 X-Bogus,如果你 XHR 断点取消了,日志就会一直打印直到卡死。日志输出完毕后,大约有8千多条,搜索就能看到最后一条日志 X-Bogus 已经生成了:
28个字符生成逻辑
直接在打印的日志页面右键 save as..,将日志导出到本地进行分析。X-Bogus 由28个字符组成,现在要做的就是看 DFSzswVOAATANH89SMHZqF9WX7n6 这28个字符是怎么来的,在日志里搜索这个字符串,找到第一次出现的地方,观察一下可以发现,他是逐个字符依次生成的,如下图红框所示:
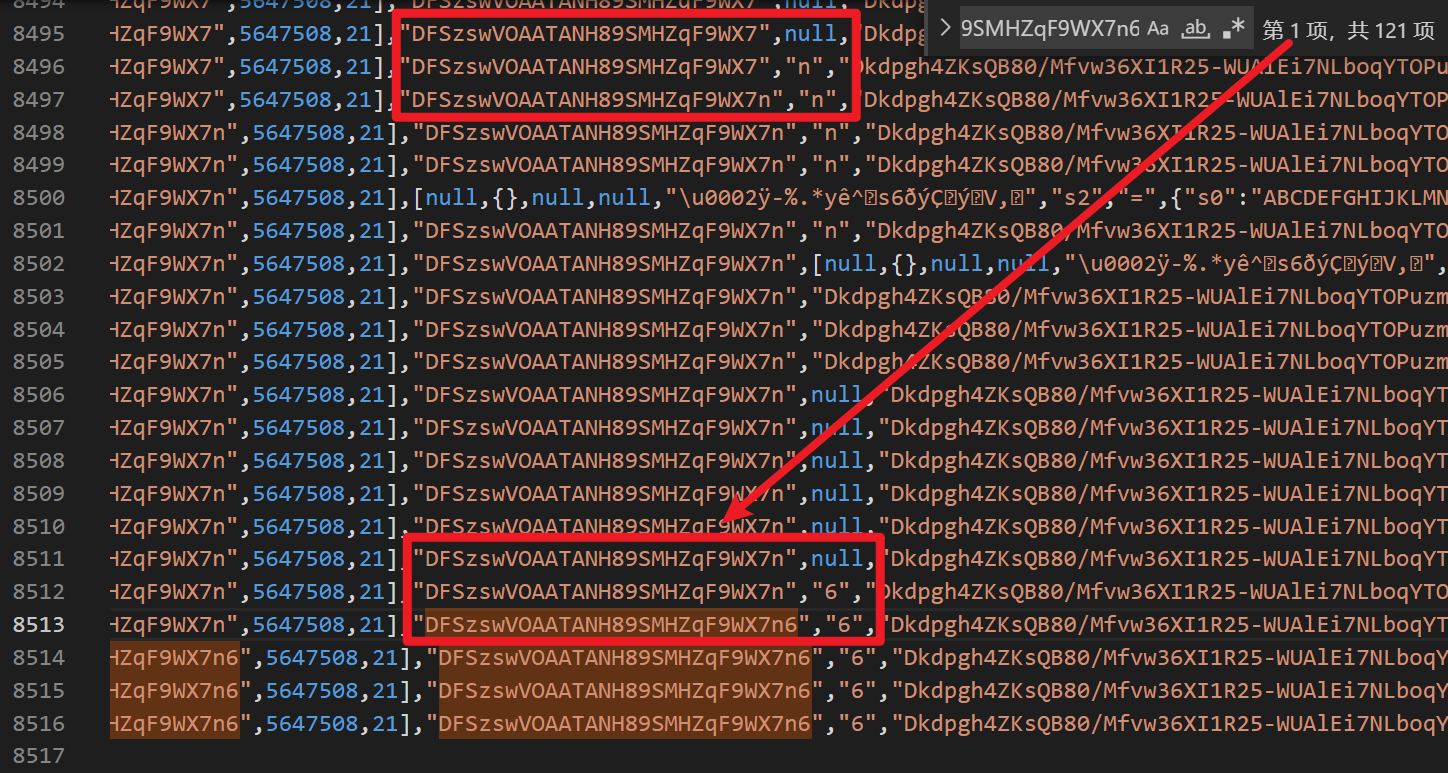
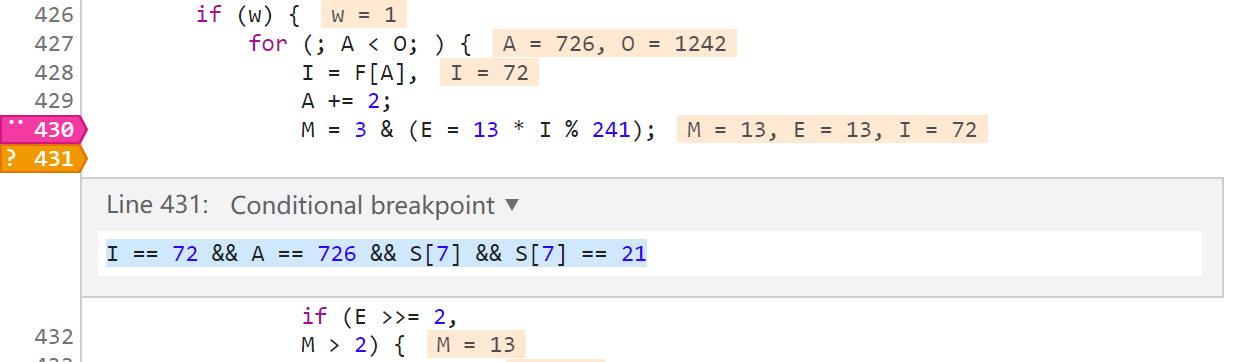
在上图中,第8511行,X-Bogus 字符串的下一个元素是 null,到了第8512行,就生成数字6了,那么在这两步之间就是数字6的生成逻辑,这个时候我们看第8511行的日志断点是 位置 2 索引I 16 索引A 738,那么我们回到原网页,在位置2,下一个条件断点(右键 Add conditional breakpoint),当 I == 16 && A == 738 && S[7] && S[7] == 21 时就断下。之所以要加 S[7] 是因为 索引I 16 索引A 738 的位置有很多,在日志里搜一下大概有40多个,多加个限制条件就可以缩小范围,当然有可能加了多个条件仍然有多个位置都满足,这就需要你细心观察了,通过断点断下的时候看看控制台前面输出的日志来判断是不是我们想要的位置。这也是一个小细节,一定要找准位置,千万别搞混了。(提示一下,像我这样下断点的话,一般情况下会断下两次,第二次是满足要求的)
(注意:本文描述的日志的多少行、断点的具体位置、变量的具体值,可能会有所变化,以你的实际情况为准,但思路是一样的)
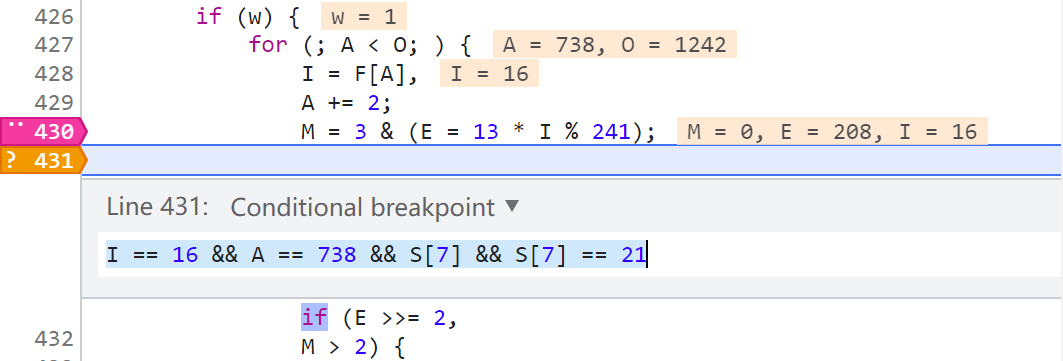
刷新网页,断下之后开始单步跟,来到下图所示的地方:
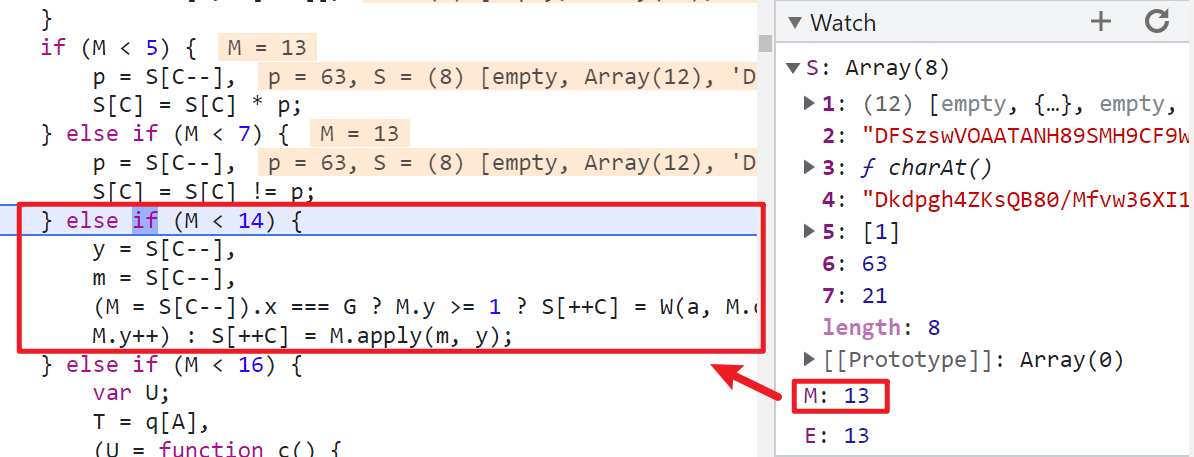
到这里之后,就不要下一步了,再下一步有可能整个语句就执行完毕了,其中的细节你看不到,所以这里我们在控制台挨个输入看看:
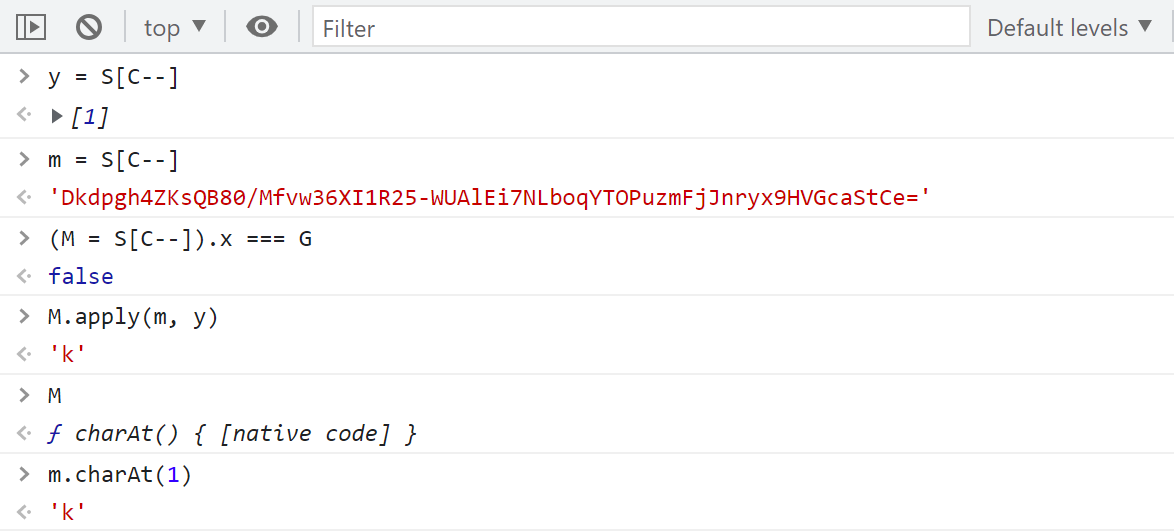
可以看到实际上的逻辑就是返回指定位置的字符,y 的值就是 S[5],m 的值就是 S[4],经过多次调试发现 m 的值是固定的,M 就是 charAt() 方法,我们再看看我们本地的日志,S[5] 的值为 [20],charAt() 取值出来就是6,逻辑完全正确。

现在我们还需要知道这个20是怎么来的,继续往上看,找到20第一次出现的地方,在第8510行,那么我们就要使其在上一步断下,也就是第8509行,如下图所示:

第8509行的索引信息为 位置 2 索引I 47 索引A 730,同样的下条件断点观察怎么生成的:
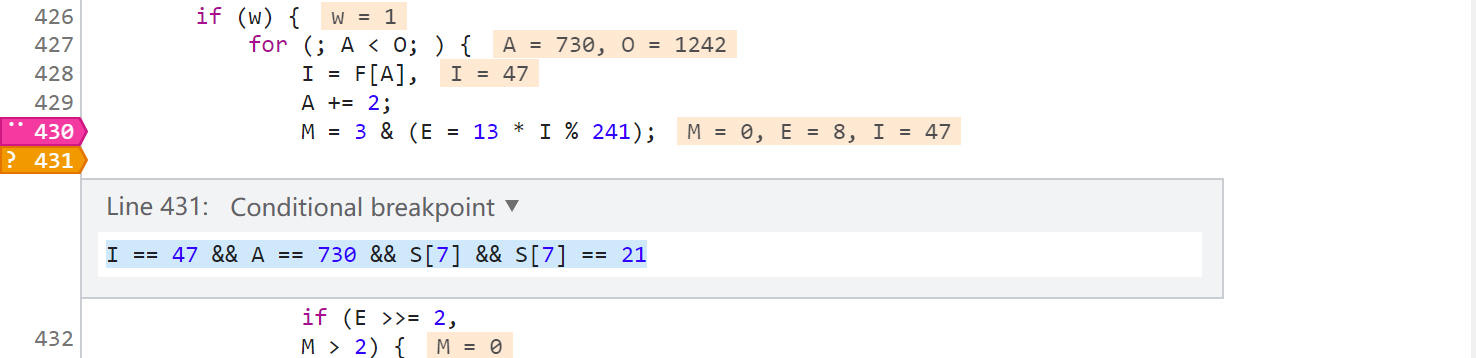
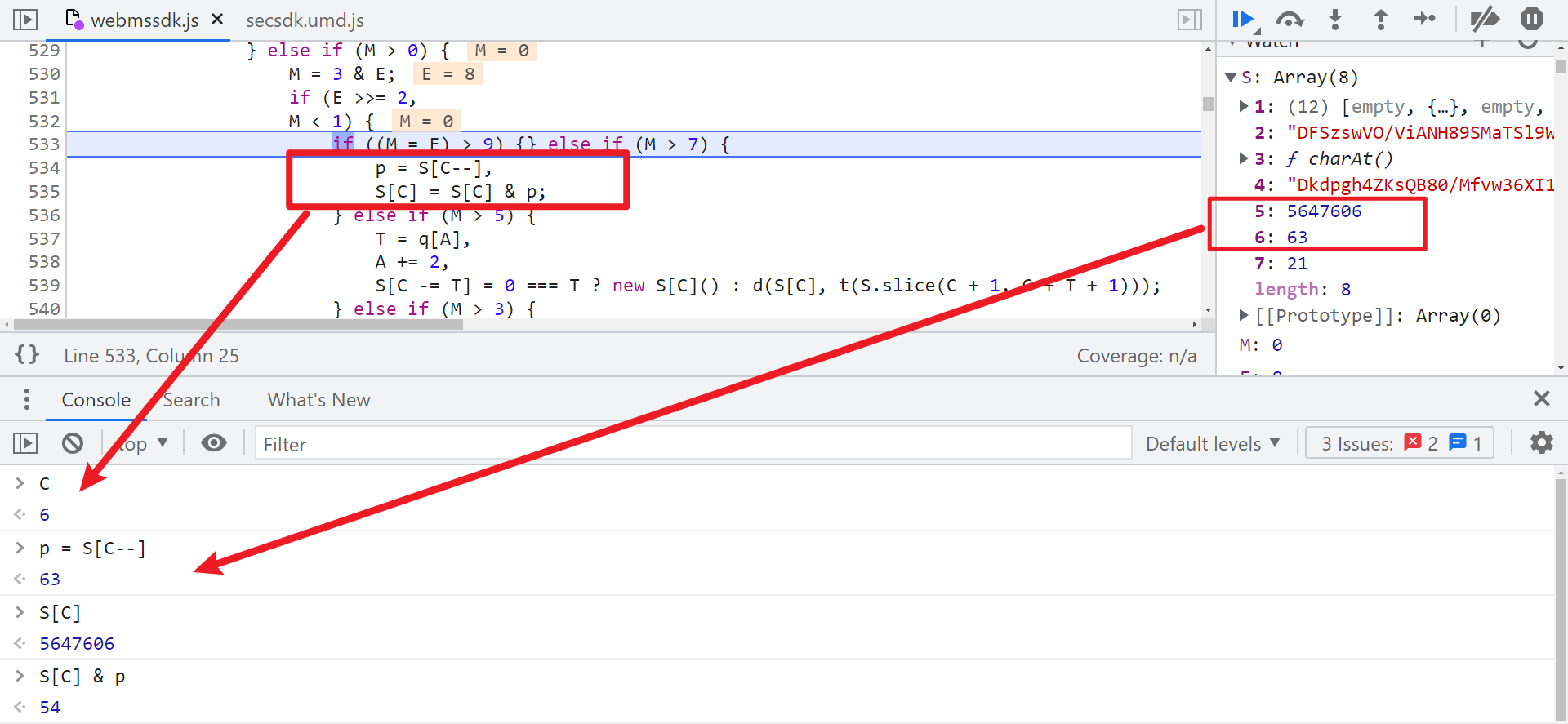
可以看到逻辑是 S[5] & S[6],再看我们本地 S[5] = 5647508、S[6] = 63,5647508 & 63 = 20,逻辑正确,20就是这么来的。接下来又开始找 5647508 和 63 是怎么生成的,同样在生成的上一步,也就是8508行下个条件断点,这行的索引为 位置 2 索引I 72 索引A 726。

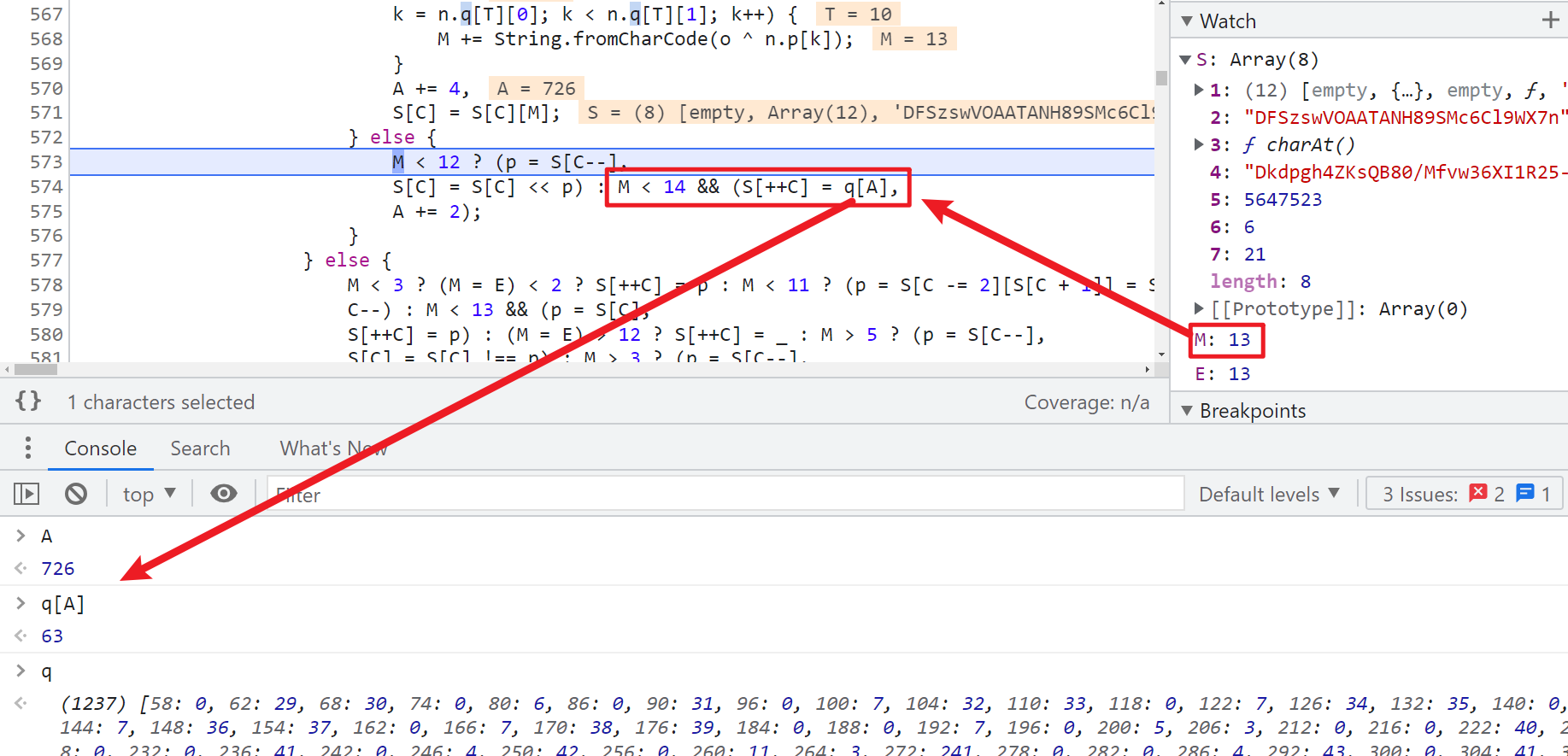
可以看到 63 是直接 q[A] 生成的,q 是一个大数组,A 就是索引为 726,q 这个大数组怎么来的先不用管,而 5647508 这个大数字,搜索一下,发现有很多,咱们也先放着,到这里咱们可以总结一下最后一个字符的生成步骤如下:
short_str = "Dkdpgh4ZKsQB80/Mfvw36XI1R25-WUAlEi7NLboqYTOPuzmFjJnryx9HVGcaStCe="
q[726] = 63
5647508 & 63 = 20
short_str.charAt(20) = '6'
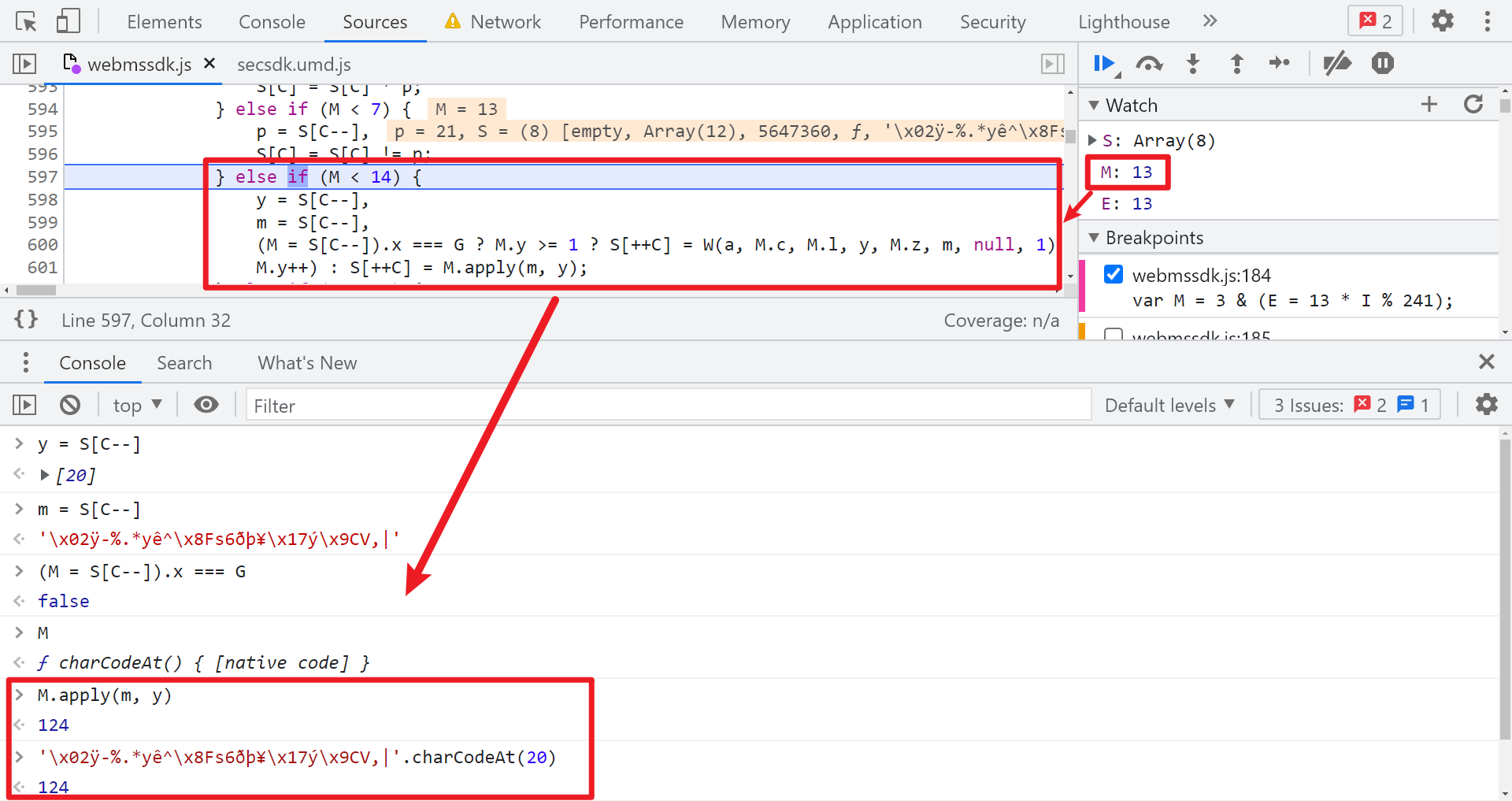
然后接日志着往上看,看倒数第二个字母是怎么来的,方法也和前面演示的一样,不断往前下条件断点,这里就不再逐步演示了,当你找完四个数字后,就可以开始看 5647508 这个大数字怎么来的了,搜索这个数字,同样的找到第一次出现的地方,在其前一步下条件断点,步骤捋出来会发现有一个乱码字符串经过 charCodeAt() 操作,再加上一些位运算得到的,乱码字符串类似下图所示:
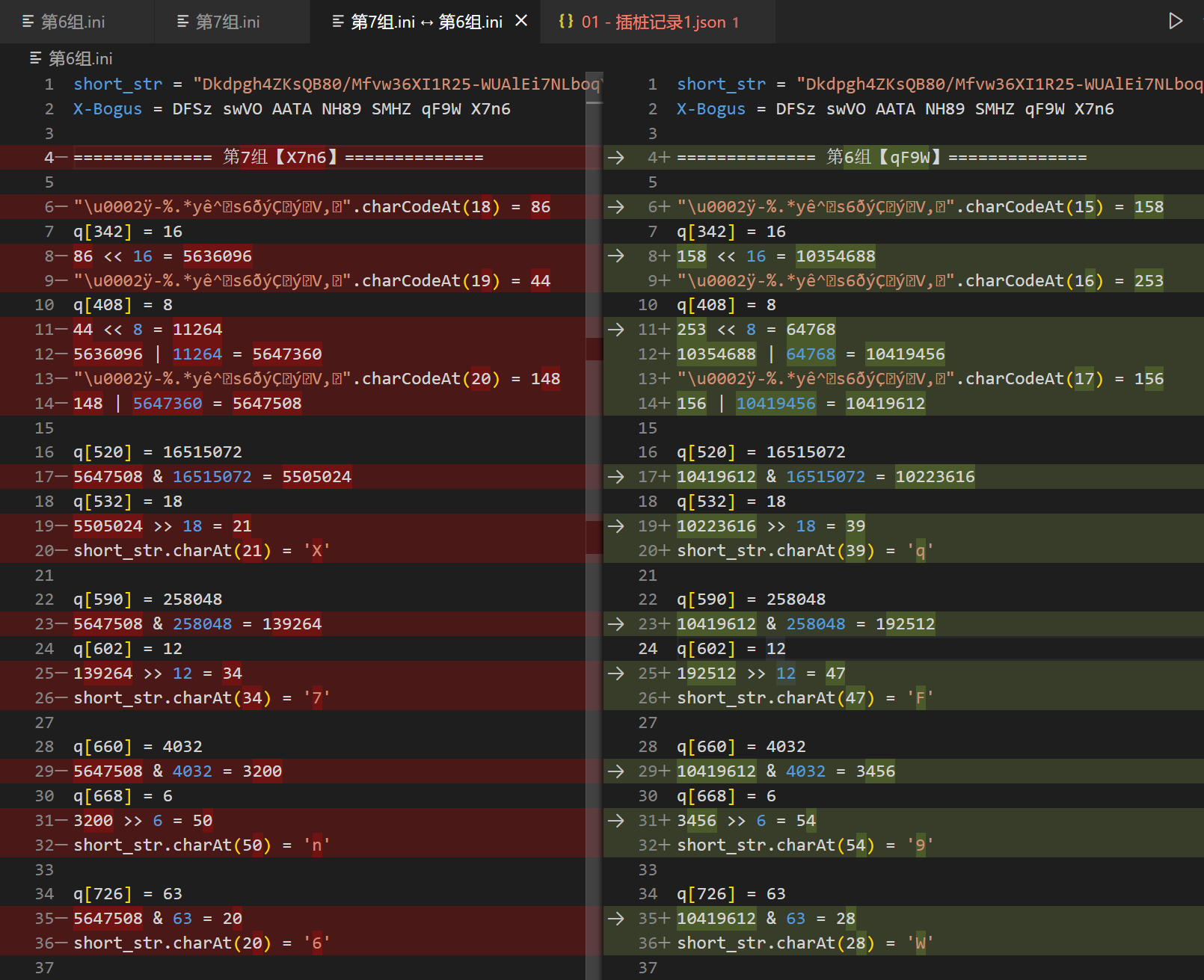
至于这个乱码字符串怎么来的,我们后面再讲,到这里先总结一下,首先我们的 X-Bogus = DFSz swVO AATA NH89 SMHZ qF9W X7n6,将其看成每四个为一组,之所以这么分组,是因为你经过分析后会发现,每一组的每一个字符生成流程都是一样的,这里以最后两组为例,流程大致如下:
short_str = "Dkdpgh4ZKsQB80/Mfvw36XI1R25-WUAlEi7NLboqYTOPuzmFjJnryx9HVGcaStCe="
X-Bogus = DFSz swVO AATA NH89 SMHZ qF9W X7n6
============== 第6组【qF9W】==============
"\u0002ÿ-%.*yê^s6eyÇyV,".charCodeAt(15) = 158
q[342] = 16
158 > 18 = 39
short_str.charAt(39) = 'q'
q[590]= 258048
10419612 & 258048 = 192512
q[602] = 12
192512 >> 12 = 47
short_str.charAt(47) = 'F'
q[660] = 4032
10419612 & 4032 = 3456
q[668] = 6
3456 >> 6 = 54
short_str.charAt(54) = '9'
q[726] = 63
10419612 & 63 = 28
short_str.charAt(28) = 'W'
============== 第7组【X7n6】==============
"\u0002ÿ-%.*yê^s6eyÇyV,".charCodeAt(18) = 86
q[342] = 16
86 > 18 = 21
short_str.charAt(21) = 'X'
q[590] = 258048
5647508 & 258048 = 139264
q[602] = 12
139264 >> 12 = 34
short_str.charAt(34) = '7'
q[660] = 4032
5647508 & 4032 = 3200
q[668] = 6
3200 >> 6 = 50
short_str.charAt(50) = 'n'
q[726] = 63
5647508 & 63 = 20
short_str.charAt(20) = '6'
将流程对比一下就可以发现,每个步骤 q 里面的取值都是一样的,这个可以直接写死,不同之处就在于最开始的 charCodeAt() 操作,也就是返回乱码字符串指定位置字符的 Unicode 编码,第7组依次是 18、19、20,第6组依次是15、16、17,以此类推,第1组刚好是0、1、2,如下图所示:
每一组的逻辑都是一样的,我们就可以写个通用方法,依次生成七组字符串,最后拼接成完整的 X-Bogus,代码如下:(乱码字符串的生成后文会讲)
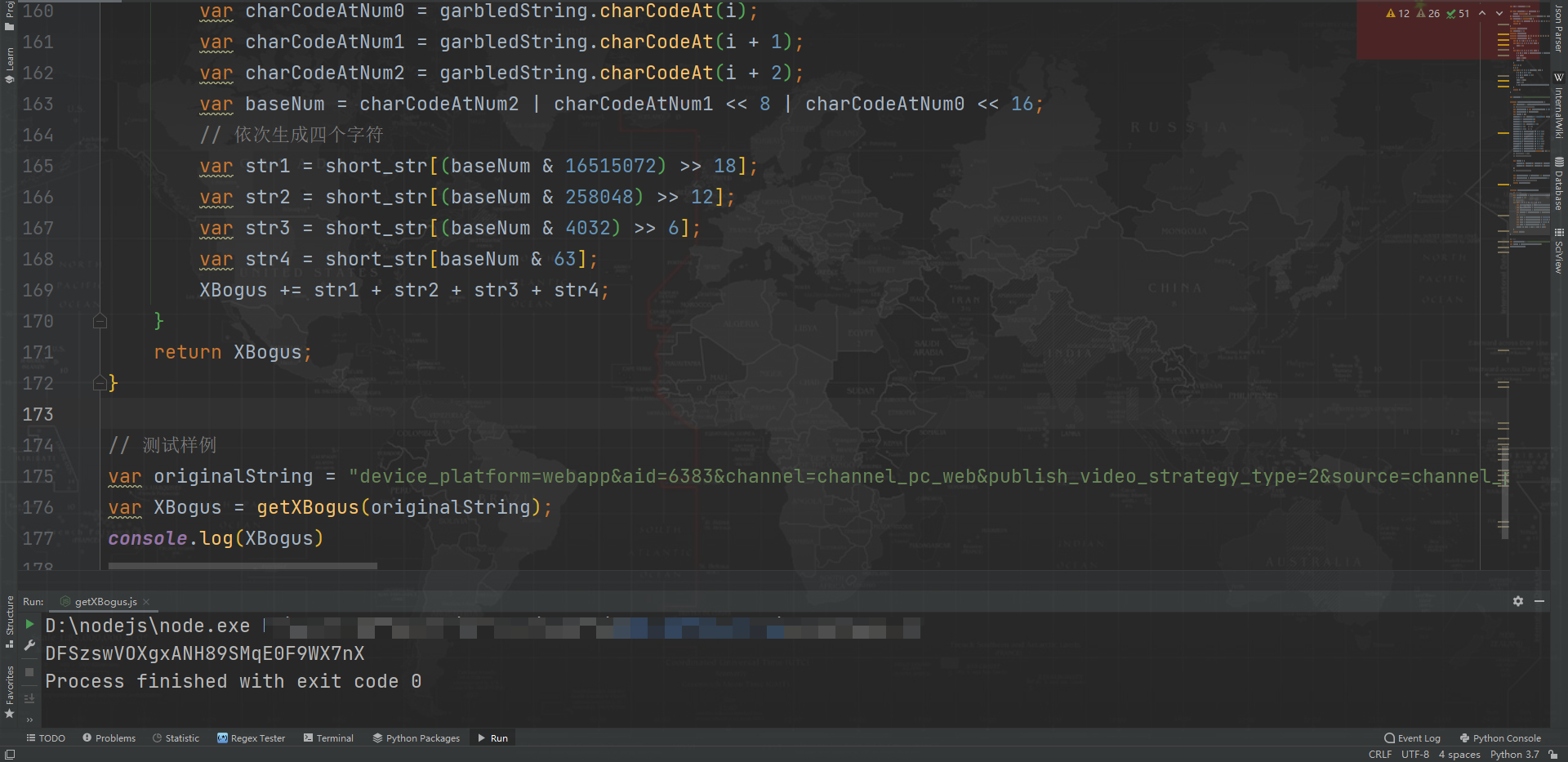
function getXBogus(originalString){
// 生成乱码字符串
var garbledString = getGarbledString(originalString);
var XBogus = "";
// 依次生成七组字符串
for (var i = 0; i > 18];
var str2 = short_str[(baseNum & 258048) >> 12];
var str3 = short_str[(baseNum & 4032) >> 6];
var str4 = short_str[baseNum & 63];
XBogus += str1 + str2 + str3 + str4;
}
return XBogus;
}
乱码字符串生成逻辑
在进行下一步之前,我们要注意两点:
文章演示有些变量前后不对应,因为每次插桩的值都是会变的,看流程就行了,流程是正确的;
我们日志输出是经过 JSON.stringify 处理了的,有些步骤是向某个函数传入乱码字符串进行处理,你会发现处理后的结果和日志不一致,这是正常的。
乱码字符串的生成相对来说稍微复杂一点,但思路仍然一样,这里就不一一截图展示了,直接用日志描述一下关键步骤,注意以下日志是正向的步骤,就不逆着推了,建议自己先逆着把流程走一走,再来看这个步骤就看得懂了。
Step1:首先对 URL 后面的参数,也就是 Query String Parameters 进行两次 MD5、两次转 Uint8Array 处理,最后得到的 Uint8Array 对象在后面的步骤中用得到,步骤如下:
位置 1 索引I 4 索引A 134:将 URL 后面的参数进行 MD5 加密得到字符串
位置 1 索引I 16 索引A 460:将上一步的字符串转换为 Uint8Array 对象
位置 1 索引I 4 索引A 134:将上一步的 Uint8Array 对象进行 MD5 加密,得到字符串
位置 1 索引I 29 索引A 472:将上一步的字符串转换为 Uint8Array 对象
上述步骤中,我们将最终得到的结果命名为 uint8Array,关键代码实现如下:
var md5 = require("md5");
// 字符串转换为 Uint8Array 对象,缺失的变量自行补齐
_0x5960a2 = function(a) {
for (var c = a.length >> 1, e = c
Step2:生成两个大数,一个是时间戳,我们称之为 fixedString1,另一个调用某个方法生成,我们称之为 fixedString2。
fixedString1
位置 1 索引I 43 索引A 806:1663385262240 / 1000 = 1663385262.24
fixedString2
位置 1 索引I 16 索引A 834:M.apply(null, []) = 536919696
上述步骤中,M 对应以下方法,缺失的方法自行补齐(其中 _0x229792 是创建 canvas):
function _0x2996f8() {
try {
return _0x4b3b53 || (_0xb55f3e.perf ? -1 : (_0x4b3b53 = _0x229792(3735928559), _0x4b3b53));
} catch (a) {
return -1;
}
}
Step3:先后生成两个数组,我们称之为 array1、array2,array2 就是由 array1 的元素位置变换后得来的,严格来讲,array1 不是一个完整的数组,而是一个个数字,这一点可以在日志中体现出来,为了方便我们就直接将其视为一个数组,两个数组都有19个元素,步骤如下:
array1[0] 至 array1[3] 为定值
array1[4]
位置 1 索引I 25 索引A 946:uint8Array[14]
array1[5]
位置 1 索引I 25 索引A 970:uint8Array[15]
array1[6] 至 array1[7] 为定值,8、9 与 ua 有关
array1[10]
位置 1 索引I 52 索引A 1090:fixedString1 >> 24 = 99
位置 1 索引I 47 索引A 1098:99 & 255 = 99
array1[11]
位置 1 索引I 52 索引A 1122:fixedString1 >> 16 = 25417
位置 1 索引I 47 索引A 1130:25417 & 255 = 73
array1[12]
位置 1 索引I 52 索引A 1154:fixedString1 >> 8 = 6506755
位置 1 索引I 47 索引A 1162:6506755 & 255 = 3
array1[13]
位置 1 索引I 52 索引A 1186:fixedString1 >> 0 = 241
位置 1 索引I 47 索引A 1194:241 & 255 = 241
array1[14]
位置 1 索引I 52 索引A 1218:fixedString2 >> 24 = 32
位置 1 索引I 47 索引A 1226:32 & 255 = 32
array1[15]
位置 1 索引I 52 索引A 1250:fixedString2 >> 16 = 8192
位置 1 索引I 47 索引A 1258:8192 & 255 = 0
array1[16]
位置 1 索引I 52 索引A 1282:fixedString2 >> 8 = 2097342
位置 1 索引I 47 索引A 1290:2097342 & 255 = 190
array1[17]
位置 1 索引I 52 索引A 1314:fixedString2 >> 0 = 536919696
位置 1 索引I 47 索引A 1322:536919696 & 255 = 144
array1[18]
位置 1 索引I 27 索引A 1352:array1.reduce(function(a, b) { return a ^ b; }); = 100
array1 完整值如下
位置 1 索引I 27 索引A 1538:64,1.00390625,1,8,9,185,69,63,74,125,99,73,3,241,32,0,190,144,100
array2 由 array1 元素交换位置而来:
array2 = [array1[0], array1[2], array1[4], array1[6], array1[8], array1[10], array1[12], array1[14], array1[16], array1[18], array1[1], array1[3], array1[5], array1[7], array1[9], array1[11], array1[13], array1[15], array1[17]]
array2 完整值如下
array2 = [64,1,9,69,74,99,3,32,190,100,1.00390625,8,185,63,125,73,241,0,144]
Step4:将 Step3 得到的 array2 经过转换得到乱码字符串,步骤如下:
位置 1 索引I 16 索引A 1706:
_0x2f2740.apply(null, array2) = "@\u0000\u0001\u000eíxE?\u0016c%>® \u0000¾ó"
位置 1 索引I 16 索引A 1760:
_0x46fa4c.apply(null, ["ÿ", "@\u0000\u0001\u000e\t1E?J}cI\u0003ñ \u0000¾d"]) = "\u0002ÿ-%.*yê^s6eyÇyV,"
位置 1 索引I 16 索引A 1812:
_0x2b6720.apply(null, [2, 255, "\u0002ÿ-%.*yê^s6eyÇyV,"]) = "\u0002ÿ-%.*yê^s6eyÇyV,"
其中用到的函数:
function _0x2f2740(a, c, e, b, d, f, t, n, o, i, r, _, x, u, s, l, v, h, g) {
let w = new Uint8Array(19);
return w[0] = a,
w[1] = r,
w[2] = c,
w[3] = _,
w[4] = e,
w[5] = x,
w[6] = b,
w[7] = u,
w[8] = d,
w[9] = s,
w[10] = f,
w[11] = l,
w[12] = t,
w[13] = v,
w[14] = n,
w[15] = h,
w[16] = o,
w[17] = g,
w[18] = i,
String.fromCharCode.apply(null, w);
}
function _0x46fa4c(a, c) {
let e, b = [], d = 0, f = "";
for (let a = 0; a
自此,整个流程就走完了。可以用 JavaScript 来实现整个算法,用 Python 也可以,完善代码后随便请求一个博主主页,简单解析几个数据,输出正常: