第二集:
首先来看看一些有意思的数据:
v2ex
GitHub
昨天发帖之后,发现样本还是太少,所以又重新收集了数据,在昨天数据的基础上,爬了一晚上,样本数来到了 5000+ (这貌似是我能找到的极限了),基于更大的样本集,也重新产出了一些值得参考的新数据:
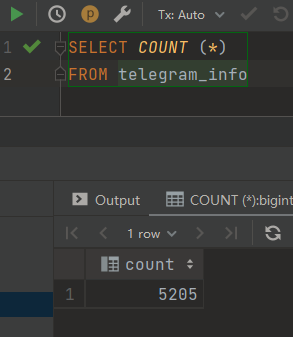
总样本数量:5205 个
其中正常账号 3036 个,异常账号 2169 个(主要是已注销账号),异常账号占比:41.7%,正常账号占比:58%
频道数:1700 ,群组:1136 ,机器人:198 。分别占比:32.7%,21.8%,0.38%
频道订阅人数排名前 10 的没有一个中文账号,前 10 的账号订阅人数均超过了 100 万,最高订阅人数 912 万
群组会员人数排名前 10 的 9 个都是中文账号,最高会员人数 19 万,最低 6 万
在过滤了 144 个关键字之后还剩下 2209 个账号,当然这其中依然有不少是需要筛选的(人麻了,筛了 5 个小时,实在筛不动了...),结果如下:
总结:
本次总共从 25 个 URL 地址获得了 5205 个样本集,样本集本身已经做了去重处理,实际的数量应该有 10000+,重复的账号没有分析的意义,就直接过滤掉了没有入库。入库之后的数据进行了二次过滤(主要是人工过滤),过滤了 Sex 、Gamble 、Politics 、黑灰产、已注销、私人账号等,经过两轮筛选最终只剩下了 2209 个账号,占总数的:42.4% ,已经不到一半了,这还是粗筛,如果细筛那最终样本会更少。
从过滤之后的数据来看,貌似各个分类的占比都很少,其实不然,因为很多账号都是跨多个分类,并不是只专精一个分类。另一方面从关键字来筛选分类,并不是很准确,最准确的应该是点进每个账号里去看内容,但这样的话人工成本会很高。
假如按照程序员这个角色的用户画像来进行推荐的话,应该和昨天的 6% 差距不大,这也基本反应了现在 Telegram 中文生态的现状。这些数据还有其他的挖掘价值,用来做数据分析还是很不错的。
GitHub 地址: https://github.com/alexbei/telegram-groups
网页版:https://www.tgqun.xyz
